
อยากอัพสกิล Data Science แต่เลือกไม่ถูกว่าจะเริ่มเรียน R หรือ Python ดี ภาษาไหนเหมาะกับอะไร และ R ใช้งานง่ายจริงมั้ย มาอ่านได้ในบทความนี้เลยครับ
What is R ?
R คือ Statistical Programming language พัฒนาต่อยอดมาจากภาษา S โดยนักสถิติชื่อ Ross Ihaka และ Robert Gentleman ที่ประเทศนิวซีแลนด์ในช่วงปี 1990s โดยเป้าหมายแรกของทั้งสองคนคือการสร้างโปรแกรม หรือเครื่องมือสำหรับสอนวิชาสถิติให้กับนักศึกษา และถูกใช้อย่างแพร่หลายในกลุ่มนักสถิติ Data Miners และนักวิชาการทั่วโลก
R version 1.0 เปิดให้ดาวน์โหลดใช้งานวันที่ 29 ก.พ. 2543 อัพเดทตอนเดือน เม.ย. 2565 ที่ผ่านมา R เดินทางมาถึงเวอร์ชัน 4.2.0 แล้ว มีฟีเจอร์ใหม่ ๆ เพิ่มขึ้นอย่างต่อเนื่อง อ้างอิงจาก Tiobe Index (พ.ค. 2565) R ได้รับความนิยมอยู่ในอันดับที่ 13 ของภาษาคอมพิวเตอร์ทั่วโลก ส่วนตัวผู้เขียนเองคิดว่าเราจะเอา R มาเทียบกับภาษาอื่น ๆ ยากหน่อย เพราะ Scope ของ R จะโฟกัสที่การวิเคราะห์ข้อมูลเป็นหลักแตกต่างจากภาษาคอมพิวเตอร์อื่น ๆ

จากผลสำรวจหลาย ๆ ที่ เราจะเห็น Python, R, SQL ติดสามอันดับแรกของสายงาน Data อยู่เสมอ ๆ โดย Python เป็น General Purpose Language ที่สามารถใช้ทำงานได้หลายประเภท ตั้งแต่ Web Development, Software, API ไปจนถึงงาน Machine Learning & Deep Learning ส่วน R จะเน้นหลัก ๆ ที่งานสถิติ และการวิเคราะห์ข้อมูล
Getting Started
เราสามารถเริ่มเขียน R ได้ง่าย ๆ สองวิธี
- รัน R ใน Local Machine (ดาวน์โหลดและติดตั้งเอง)
- รัน R ใน Cloud Environment (เขียนผ่าน Web Browser)
สำหรับเพื่อน ๆ ที่สนใจแบบที่หนึ่ง รันใน Local Computer ของเรา สามารถดาวน์โหลด R และ RStudio Desktop IDE มาใช้งานได้ฟรี
ในตัวอย่างบทความนี้ เราจะสอนเขียน R บน RStudio Cloud โดยเราสามารถสมัครใช้งานฟรี 25 ชั่วโมงต่อเดือน ผ่าน Web Browser แนะนำเป็น Google Chrome, Microsoft Edge, Safari
Great Books to Learn R
สำหรับหนังสือที่ R Programmers นิยมอ่านกัน มีดังต่อไปนี้ เล่มที่ได้รับความนิยมสูงที่สุดคือ R for Data Science เขียนโดย Hadley Wickham ผู้บุกเบิก Modern R ในช่วง 10 ปีที่ผ่านมา
- R for Data Science (O’Reilly) อ่านฟรีออนไลน์
- Introduction to Data Science (CRC Press)
- Practical Data Science with R (Manning)
- R Cookbook (O’Reilly)
อ่านหนังสือ อ่านบทความนี้ และเปิด RStudio Cloud มาเขียนโปรแกรมพร้อม ๆ กันเลยนะครับ
Hello World
เปิด Web Browser ไปที่ Rstudio Cloud สมัครบัญชีฟรี เมื่อเข้าไปที่หน้า Dashboard แล้วให้เรากดปุ่ม New Project ทางด้านขวาบนของหน้าจอ แล้วเลือก Option New RStudio Project ไปที่หน้าต่าง Console และพิมพ์คำสั่งนี้ กด Enter หนึ่งครั้ง
print("hello world")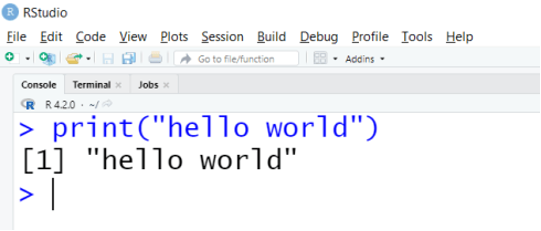
R (เหมือนกับ Python) เป็นภาษาแบบ Interpreted Language => REPL => Real, Evaluate, Print, Loop สามารถเขียนคำสั่ง กดรัน และเห็นผลลัพธ์ได้ทันที
1 + 1
2 * 5
8 - 3
5 / 2เบื้องต้นเราสามารถใช้ R เป็นเครื่องคิดเลขได้เลย ถ้าเราต้องการ Clear หน้าจอ Console ให้กด Shortcut CTRL+L บนคีย์บอร์ด
Comment
เวลาเขียนโปรแกรมเราสามารถใส่ Comment ให้กับโค้ดไลน์นั้น ๆ ของเราได้ด้วย เพื่ออธิบายการทำงานของโปรแกรมเบื้องต้น ใน R เราใช้ # และตามด้วย Comment ที่ต้องการ
# this is a commentData Types
ประเภทข้อมูลพื้นฐานใน R ที่เราใช้กันบ่อย ๆ จะมี Numeric, Character และ Logical ตามลำดับ สำหรับงานสถิติจะมีตัวแปรประเภท Factor เพิ่มขึ้นมาด้วย i.e. ตัวแปรกล่มสามารถแบ่งได้เป็น Nominal และ Ordinal
is.numeric(100)
is.character("hello")
is.logical(TRUE)ฟังก์ชันใน Code Block นี้ใช้ตรวจสอบประเภทข้อมูลของค่า หรือตัวแปรที่เราสร้างขึ้นมา ทั้งสามบรรทัดด้านบนจะได้คำตอบเป็น TRUE ทั้งหมดเลย
ถ้าต้องการเปลี่ยน Data Type ใน R เราจะใช้ฟังก์ชันที่ขึ้นต้นด้วย as._() เช่น as.numeric(“100”) หรือ as.character(5525) เป็นต้น
Operators
R มี operators ที่เราใช้เหมือนในภาษาอื่นๆ ไว้เทียบค่าสองฝั่งของสมการ โดย == คือเท่ากัน และ != คือไม่เท่ากัน
- ==
- !=
- >
- <
- >=
- <=
ตัวอย่างการใช้งาน operators ถาม R ว่า 1+1 มีค่าเท่ากับ 2 หรือเปล่า #TRUE
1 + 1 == 2 # TRUE
2 * 2 != 4 # FALSEเราสามารถเปรียบเทียบ character ได้ด้วย เช่น “Hello” == “hello” #FALSE สิ่งที่ต้องจำไว้เสมอคือ R เป็นภาษาแบบ Case Sensitive ตัวพิมพ์เล็ก-ใหญ่มีผลกับการเขียนโปรแกรมของเรา
Variables
Concept สำคัญของการเขียนโปรแกรม ที่คือการใช้ตัวแปร (Variable) เพื่อเก็บค่าบางอย่าง (Value) โดยค่านั้นจะเป็น Single Value หรือจะเป็น Object ประเภทอื่น ๆ ก็ได้ ใน R ตัวแปรจะเป็นอะไรก็ได้ ตั้งแต่ตัวเลขทั่วไป โมเดลทางสถิติ ฟังก์ชัน หรือแม้แต่ Graphic/ Visualization ก็ได้
R ใช้เครื่องหมาย <- หรือ Assign Symbol เพื่อประกาศค่าตัวแปร
# numeric variables
income <- 15000
expense <- 12500
saving <- income - expense
print(saving)ถ้าเรา Assign ค่าใหม่ไปที่ตัวแปรเดิม จะเป็นการ Overwrite ค่าเดิม (อัพเดทค่าใหม่)
# character variables
text <- "hello world"
text <- "updated text hehe"
print(text) # updated text heheTip – จริง ๆ ใน R เราจะใช้เครื่องหมาย <- หรือ = เพื่อประกาศค่าตัวแปรก็ได้ครับ อยู่ที่ความถนัดของแต่ละคนเลย สำหรับเพื่อน ๆ ที่มาจากสาย Python หรือภาษาอื่น ๆ อาจจะถนัดใช้ = มากกว่า
# we can use <- or = to create a new variable
x <- 100
x = 100ถ้าต้องการลบตัวแปรออกจาก Environment ให้พิมพ์ฟังก์ชัน rm() และใส่ชื่อตัวแปรที่ต้องการลบออก อันนี้เป็น Good Practice เวลาเขียนโปรแกรม ให้เก็บไว้เฉพาะตัวแปรที่เราใช้ใน Session นั้น ๆ (ลดการใช้งาน Memory ในกรณีที่ RAM คอมพิวเตอร์เรามีจำกัด)
# remove variable
rm(x)ทิปสำหรับวิธีการตั้งชื่อตัวแปรใน R ให้ใช้เป็นตัวพิมพ์เล็กทั้งหมดแบบ Snake Case เช่น my_name, my_age, และ hello_world ชื่อตัวแปรห้ามขึ้นต้นด้วยตัวเลข และห้ามใช้ Reserve Keywords เช่น if for หรือ while เป็นต้น
Data Structures
ทุกภาษาจะมีสิ่งที่เราเรียกว่า Data Structures เพื่อใช้เก็บข้อมูลที่มีโครงสร้างหลาย ๆ แบบ ใน R ที่เราใช้หลัก ๆ จะมี 4 แบบดังนี้ (อีกแบบที่ใช้บ่อยคือ Array ในกรณีที่ข้อมูลมีหลายมิติ)
- Vector
- Matrix
- List
- DataFrame
ในบทความนี้เราจะโฟกัสที่สองตัวหลักที่เราใช้ในงาน Data Analysis คือ Vector และ Dataframe
Vector
Vector เปรียบเสมือน Array ของภาษาอื่น ๆ ใน R เราใช้ฟังก์ชัน c() เพื่อสร้าง Vector และคุณลักษณะสำคัญของ Vector คือจะเก็บข้อมูล (Data Type) ได้แค่ประเภทเดียวเท่านั้น ตัวอย่างนี้เราลองสร้าง 3 vectors ชื่อว่า friends, ages, movie_lover ตามลำดับ
# create vectors
friends <- c("john", "mary", "anna", "david", "henry")
ages <- c(25, 22, 30, 28, 32)
movie_lover <- c(TRUE, TRUE, FALSE, FALSE, TRUE)เราสามารถ Subset หรือดึงข้อมูลออกมาจาก vector ด้วยการใช้สัญลักษณ์ [ ] และใส่เลข Index โดย Index ใน R จะเริ่มต้นที่เลข 1 (ไม่เหมือนกับ Python ที่เริ่มที่เลขศูนย์)
# subset
friends[1]
friends[2]
friends[3]
friends[4]
friends[5]
# update values
friends[1] <- "superman"
friends[2] <- "captain marvel"จากตัวอย่าง Code นี้ เราอัพเดทค่าในตำแหน่งที่ 1,2 เป็น Superman และ Captain Marvel ตามลำดับ จะเห็นว่าวิธีการอัพเดทค่าใน Vector ง่ายมาก ๆ เราสามารถเลือก Index ที่ต้องการและใช้ <- assign ค่าใหม่ได้เลย
DataFrame
มาถึง Highlight ของการเขียนโค้ด R คือการสร้าง Dataframe จาก Vectors ที่เราเขียนมาในหัวข้อก่อนหน้านี้ เราใช้ฟังก์ชัน data.frame() และใส่ Vector ที่เตรียมไว้ โดย friends, ages, movie_lover จะกลายเป็นคอลัมน์ที่ 1 2 และ 3 ตามลำดับใน Dataframe
# create dataframe from vectors
df <- data.frame(friends, ages, movie_lover)
View(df)DataFrame คือข้อมูลในรูปแบบตารางมีคอลัมน์และแถว (Columns, Rows) ถ้านึกภาพไม่ออก ให้นึกถึงตารางในโปรแกรม Microsoft Excel หรือ Google Sheets ได้เลย เราใช้ฟังก์ชัน View() เพื่อเรียกดู DataFrame ใน Rstudio
ถ้าเรามีไฟล์ csv (Comma Separated Values) เตรียมไว้ แล้วให้เราคลิกที่ปุ่ม Files > Upload ในหน้าต่างขวาล่างของ RStudio เมื่ออัพโหลดไฟล์ขึ้นไปแล้ว เราสามารถอ่านและเขียนไฟล์ csv ได้ง่าย ๆ ด้วยฟังก์ชัน read.csv() และ write.csv() ตามลำดับ
# read csv file
new_df <- read.csv("file.csv")
# write csv file
write.csv(new_df, "new_file.csv", row.names=FALSE)ฟังก์ชันทั้งหมดที่เราอธิบายในบทความมาถึงตรงนี้คือ Base R Functions ที่ใช้กันมา 20 กว่าปีแล้ว การเขียน R ในปัจจุบันจะมี Packages/ Libraries ใหม่ ๆ ให้เราใช้งานมากมาย ช่วยให้การเขียนโปรแกรมง่าย ๆ และสนุกขึ้นอย่างมาก (ทำงานเสร็จเร็วขึ้น อะไรที่ทำใน Microsoft Excel ได้ ก็สามารถทำเสร็จใน R ได้เหมือนกัน โดยเฉพาะงาน Data Transformation)
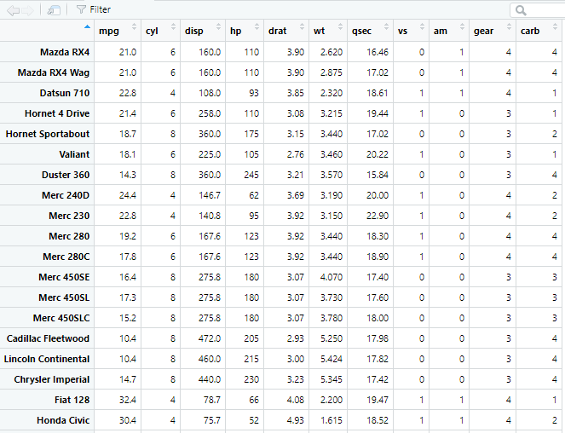
มาลองดู Built-in Dataframe ใน R กันบ้าง อันนี้จะเป็น Dataframe ที่ R เตรียมไว้ให้ Users ลองใช้งานได้ทันที แค่เปิดโปรแกรมขึ้นมา พิมพ์ชื่อ Dataframe นั้นได้เลย ในตัวอย่างนี้เราจะใช้ mtcars เพื่ออธิบายการ Subset Dataframe ง่าย ๆ
ทบทวนสั้น ๆ ว่า Index ใน R เริ่มที่เลข 1 และ Dataframe คือตารางที่เราต้องกำหนดทั้ง Rows, Columns ในการดึงค่า เช่น Rows = 1:2 และ Columns = 3:4
# built-in dataframe
View(mtcars)
# subset dataframe
mtcars[1:5, ]
mtcars[ , 1:5]
mtcars[1:5, 1:5]
mtcars[1:5, c("mpg", "hp", "wt")]
mtcars[mtcars$hp < 100, ]รูปแบบการ Subset Dataframe ใน R จะทำได้สามแบบ
- ดึงด้วยตำแหน่ง เช่น เลขแถวหรือคอลัมน์ที่เราต้องการ mtcars[1:5, ] คือการดึงแถวที่ 1 ถึง 5 เอามาทุกคอลัมน์
- ดึงด้วยชื่อ เช่น ดึงคอลัมน์ชื่อตามนี้ c(“mpg”, “hp”, “wt”) ออกมา
- ดึงด้วยเงื่อนไข เช่น จงดึงรถยนต์ที่มี hp < 100
Common Statistics
R มีฟังก์ชันสถิติพร้อมให้ใช้งานเยอะมาก เรียกว่าเกิดมาเพื่องาน Statistical Analysis โดยเฉพาะ ตัวอย่างด้านล่างเราดึงคอลัมน์ hp, wt ออกมาจาก Dataframe เก็บค่าเป็น Vector
เสร็จแล้วเราเรียกใช้งานฟังก์ชันสถิติต่าง ๆ เช่น mean(), sum(), sd() ไปจนถึง cor() หรือ Pearson Correlation สำหรับหาความสัมพันธ์ของ Numeric Columns สองตัว
# get column hp from mtcars dataframe
hp <- mtcars[["hp"]]
wt <- mtcars[["wt"]]
# common statistics
mean(hp)
sum(hp)
length(hp) # count
min(hp)
max(hp)
sd(hp)
var(hp)
cor(hp, wt) # correlationR มีฟังก์ชันเพื่อวิเคราะห์และพรีวิวหน้าตาของ dataframe หลายฟังก์ชันมาก ๆ ด้านล่างคือ 4 ฟังก์ชันที่เราใช้บ่อยๆ str() เพื่อดูโครงสร้างข้อมูลเบื้องต้น head(), tail() จะพรีวิวหกแถวบนสุดและล่างสุดของ dataframe ตามลำดับ ส่วน summary() ใช้สรุปผลสถิติทุกคอลัมน์ของ Dataframe แบบเร็ว ๆ
# common dataframe functions
str(mtcars)
head(mtcars)
tail(mtcars)
summary(mtcars)ผลลัพธ์ที่ได้จาก summary(mtcars)

Optional Reading – R ใช้ค่า NA เพื่อแทน Missing Values ใน Vectors หรือ Dataframe ถ้าเราต้องการนับค่า NA ใน Data Stucture ที่เราทำงานด้วย สามารถใช้ฟังก์ชัน is.na() ได้เลย
# create vector with some NA values
some_NAs <- c(30, 35, 40, NA, 50)
is.na(some_NAs) # FALSE FALSE FALSE TRUE FALSE
# count NA in every column
apply(mtcars, 2, function(col) sum(is.na(col)))โค้ดในตัวอย่างด้านบน เราใช้ฟังก์ชัน apply() เป็นตัวอย่างของ Functional Programming ใน R เพื่อลดการเขียน for loop และสามารถนับจำนวน NA (Missing Values) ในแต่ละคอลัมน์ของ mtcars Dataframe ได้ในบรรทัดเดียว นี่คือความสวยงามของภาษา R เลยครับ
Function
เราเห็นตัวอย่างการใช้งานฟังก์ชันใน R มาเยอะมากในบทความ มาลองเขียนฟังก์ชันไว้ใช้งานเองกันบ้าง โดยหัวข้อนี้เราจะอธิบายการสร้าง Function และการใช้งาน Control Flow เพื่อควบคุมพฤติกรรมของโปรแกรมที่เราพัฒนาขึ้นมา
- Function
- Control Flow
R ใช้คีย์เวิร์ด Function ในการประกาศฟังก์ชันใหม่ ตามตัวอย่างด้านล่าง โค้ดส่วนที่อยู่ใน { } คือ Body ของ Function นั้น ๆ i.e. การทำงานของฟังก์ชันเป็น Steps ที่เรากำหนดไว้
greeting <- function() {
print("Hi There!")
}
greeting_name <- function(name) {
cat("Hello! ", name)
}ฟังก์ชันใน R จะมีหรือไม่มี Input ก็ได้ ลองดูตัวอย่างฟังก์ชัน greeting() vs. greeting_name() ด้านบน เวลาที่เราเจอฟังก์ชันใหม่ที่เราไม่เคยใช้มาก่อน เกือบทุกฟังก์ชันใน R จะมาพร้อมกับคู่มือ ให้เราพิมพ์ ? ตามด้วยชื่อฟังก์ชัน หน้าต่างขวาล่างของหน้าจอจะเปิดหน้า Help/ Manual ทันที
ตัวอย่างเช่น ถ้าเราอยากรู้ว่าฟังก์ชัน cat() ใช้ทำอะไร พิมพ์ ?cat ใน Console
?catมาถึงตรงนี้เชื่อว่าทุกคนเขียนโปรแกรมกันใน Console กันมาตลอด แต่จริง ๆ ข้อดีของการเขียนโค้ดคือเราสามารถ Save Text File หรือ Script ที่เราเขียนได้

ให้เราเปิดหน้าต่าง Script (ซ้ายบนของ Rstudio ขึ้นมา) และเริ่มเขียนโค้ดที่เราต้องการ กด Save File เป็นไฟล์นามสกุล .R เราสามารถดาวน์โหลดไฟล์ Script จาก Cloud ลงมาทำงานต่อใน Local Computer ของเราได้อีกด้วย หรือส่งต่อให้ทีมของเราพัฒนาโปรแกรมต่อ
มาลองเขียนฟังก์ชันที่รับ Input มากกว่าหนึ่งตัวกันบ้าง ตัวอย่างด้านล่างใน Body เราใช้ return() เพื่อบอกว่าฟังก์ชัน add_two_nums() จะ Return ผลลัพธ์อะไรออกมา
ฟังก์ชันที่ใช้ return() จะสามารถประกาศค่าในตัวแปรใหม่ได้
# function with two arguments
add_two_nums <- function(a, b) {
return(a + b)
}
# test this function
result <- add_two_nums(10, 15)
print(result)ถ้าเราเพิ่ม Control Flow เช่น การเขียน if-else, for loop หรือ while loop ฟังก์ชันของเราจะมีความสามารถเพิ่มขึ้นอีกเยอะเลย การควบคุม branching ต่าง ๆ การรันคำสั่งแบบมีเงื่อนไข หรือการเขียน for loop ที่มีเงื่อนไข เป็นต้น
# if-else example
grading <- function(score) {
if (score >= 80) {
print("passed")
} else {
print("failed")
}
}
# test function
grading(75) # failed
grading(99) # passedตัวอย่างด้านบนเราใช้ฟังก์ชัน grading() ที่รับคะแนนสอบนักเรียน และแปลงเป็นเกรดคือ “passed” (คะแนนมากกว่าหรือเท่ากับ 80) หรือ “failed” (คะแนนน้อยกว่า 80)
มาลองดูการเขียน for loop ใน R กันบ้าง ตัวอย่างนี้เรา print() คำว่า “hello” ทั้งหมด 5 รอบ (for loop คือเรารู้ว่า loop เราจะวิ่งกี่รอบ หรือ finite loop)
# for loop in r
hello_n_times <- function(n) {
for (i in 1:n) {
print("hello!")
}
}
# test function
hello_n_times(5)สำหรับการเขียน Function + Control Flow ใน R เราใช้ { } เพื่อกำหนด Scope ของการทำงานของโปรแกรม ถ้าฟังก์ชันที่เขียนมีความซับซ้อน เราอาจจะตาลายกับ { } ได้ อาจจะเป็นข้อจำกัดหนึ่งของ R เมื่อเทียบกับ Python ที่ใช้ย่อหน้าหรือ Whitespace ในการกำหนด Scope
Packages
Packages คือ R code ที่ Developers ทั่วโลกช่วยกันพัฒนาขึ้นมาและ Publish ให้คนทั่วไปดาวน์โหลดมาใช้งานได้ฟรี การดาวน์โหลด Packages จะช่วยให้การทำงานหลายอย่างของเราไม่ต้องเริ่มจากศูนย์ เพราะปัญหาที่เราเจออยู่ตอนนี้ มีคนเคยเจอมาก่อน และคิด Solutions ให้เรายืมมาใช้ได้แล้ว (แถมฟรีด้วย) ?
มาลองดูตัวอย่าง Library Glue เพื่อสร้าง String Template กันบ้าง (คล้าย ๆ กับ fstring ของภาษา Python) วิธีการดาวน์โหลดให้เรียกใช้ฟังก์ชัน install.packages() แค่ครั้งเดียว ครั้งต่อไปที่เปิดโปรแกรมขึ้นมา สามารถใช้ library() ตามด้วยชื่อฟังก์ชัน เพื่อโหลดฟีเจอร์ของ Package นี้ขึ้นมาได้เลย
Note – เราอาจจะใช้คำว่า Packages และ Libraries สลับกันบ้าง แต่ใน R ส่วนใหญ่จะหมายถึงสิ่งเดียวกันนะครับ เวลาเราดาวน์โหลด Packages มาจากอินเตอร์เน็ต ไฟล์จะถูกเก็บใน Library ของคอมพิวเตอร์เรา i.e. folder ที่เรากำหนดไว้
install.packages("glue")
library(glue)ประกาศค่าตัวแปร my_name และ my_age เสร็จแล้วดึงค่าตัวแปรสองตัวนี้ไปใส่ใน Template ที่เราเตรียมไว้ด้วย { } ตัวอย่างโค้ดด้านล่างจะได้ประโยคว่า “Hi my name is Toy, and I’m 33 years old”
my_nage <- "Toy"
my_age <- 33
glue("Hi my name is {my_name}, and I'm {my_age} years old")R Packages ที่เรานิยมใช้กันในงาน Data Science ทั้งหมดสามารถดาวน์โหลดใช้งานได้ฟรี
- Tidyverse
- Tidymodels
- Caret
- Lubridate
- Shiny
- ค้นหา Packages/ Libraries ที่เราต้องการใช้งานได้ที่ rdocumentation
การที่ R หรือ Python มี Libraries ให้เลือกใช้มากมาย เป็นเพราะ Community และการเปิด Opensource ของตัว Source Code และฟีเจอร์ต่าง ๆของภาษาให้นักพัฒนาเข้ามาต่อยอดได้
สรุปการดาวน์โหลด Packages ให้มองง่าย ๆ ว่าเป็นการเพิ่มฟีเจอร์ใหม่ ๆ ให้กับโปรแกรมของเรา โดยเราไม่ต้องเขียนเอง แต่ยืมมาใช้ได้เลย ไม่ต้อง reinvent the wheels ?
Data Transformation
อีกหนึ่ง package ที่สาย R อย่างพวกเราจะขาดไม่ได้เลย คือ dplyr (อยู่ในตระกูล tidyverse) พัฒนาโดยทีม RStudio และ Hadley Wickham คนเดิม
เราใช้ dplyr เพื่อทำ data transformation จัดการ Dataframe ปรับแต่งหน้าตา หรือ Join Multiples Dataframes เข้าด้วยกันได้ง่าย ๆ Hadley เรียก dplyr ว่า “The grammar of data manipulation”
install.packages("dplyr")
library(dplyr)
โดยฟังก์ชันหลักของ dplyr จะมีอยู่ 5 ตัวคือ select(), filter(), arrange(), mutate(), summarise() เพื่อน ๆ สามารถอ่านการเขียน dplyr แบบเต็ม ๆได้ที่ dplyr document
mtcars %>%
select(hp, wt, am) %>%
filter(hp > 100) %>%
arrange(wt)เราเขียน %>% เพื่อสร้าง Data Pipeline ง่าย ๆ ในตัวอย่างโค้ดนี้เราเขียน Pipeline ขึ้นมา 3 ขั้นตอน เริ่มจากการใช้ select() เพื่อเลือกคอลัมน์ hp wt am เสร็จแล้วฟิลเตอร์เฉพาะรถยนต์ที่มี hp มากกว่า 100 และขั้นตอนสุดท้ายเรียงข้อมูลจากน้อยไปมากด้วยคอลัมน์ wt
ผลลัพธ์จะออกมาเป็น Dataframe ที่วิ่งผ่าน pipeline นี้มา (ถูก Transformed แบบที่เราต้องการ) โดย Pipeline ไม่ควรยาวเกินไป Hadley แนะนำว่าซักประมาณ 8-10 ขั้นตอนกำลังดี ๆ
มาลองดู Syntax การ Join Tables กันบ้าง โดยใน dplyr รองรับการ join ครบทั้ง 4 แบบมาตรฐานคือ inner, left, right และ full join ตัวอย่างวิธีใช้ เช่น
customer %>%
inner_join(address, by="customer_id") %>%
inner_join(invoice, by="customer_id")เราสามารถนำผลลัพธ์หรือ Dataframe ที่ผ่าน Pipeline นี้มาแล้ว ไปใช้ทำ Data Analysis อื่น ๆ ต่อไปได้ ถ้าทุกคนสังเกตดี ๆ จะเห็นว่า dplyr syntax ได้รับแรงบันดาลใจมาจาก SQL ในหลาย ๆ มิติ หัวข้อต่อไปเราจะลองเขียน SQL-like ใน Rstudio ด้วย Package sqldf
Writing SQL in R
สำหรับใครที่ถนัดใช้ SQL ในการจัดการข้อมูล เราสามารถโหลด sqldf Library ขึ้นมาได้เลย และเขียน SQL Query ที่เราอาจจะเชี่ยวชาญกว่าใน RStudio
install.packages("sqldf")
library(sqldf)
sqldf("SELECT * FROM mtcars WHERE hp < 80 AND am = 1")ผลลัพธ์ที่ได้จาก sqldf จะออกมาเป็น Dataframe หรือ Value ตาม SQL ที่เรากำหนด เราสามารถเก็บค่าอยู่ในตัวแปร เช่น df_query และใช้คำสั่งใน R จัดการ Dataframe นี้ต่อ เช่น head(), tail(), summary() หรือ dplyr เป็นต้น

Data Visualization
จุดแข็งอีกอย่างหนึ่งของ R คือการทำกราฟฟิค และ Data Visualization รูปแบบต่าง ๆ และ Library ที่โด่งดังที่สุดของ R Programmer คือ ggplot2 โดย Hadley Wickham
gg ย่อมาจากคำว่า grammar of graphics สำหรับเพื่อน ๆ ที่สนใจ อ่านหนังสือเล่มนี้ได้ฟรีออนไลน์ที่เว็บไซต์ของ Hadley Wickham จัดว่าเป็นเล่มในตำนานอีกเล่ม ?
install.packages("ggplot2")
library(ggplot2)
ggplot(mtcars, aes(hp, wt)) +
geom_point() +
geom_smooth(col="red") +
theme_minimal()การทำงานของ ggplot2 เป็นเหมือนกับ Layer ที่เราสามารถเขียนซ้อนกันได้ จาก Syntax สังเกตว่าเราใช้เครื่องหมาย + ในการซ้อน Layer เช่น เพิ่ม Point (Scatter Point) และมี Smooth Curve Mode (Smooth) อยู่ด้านบน
ggplot2 สามารถสร้างชาร์ทแบบ 2D ได้มากกว่า 35 แบบ และสามารถ Customize ปรับหน้าตาของชาร์ทได้อย่างที่ใจเราต้องการ ตั้งแต่ Theme, Axis, Label, Legend เป็นต้น

ชาร์ททั้งหมดที่เราสร้างขึ้นมา สามารถ Export ออกมาเป็นไฟล์ PNG, JPG หรือแม้แต่ Interactive Plot ด้วย Library ggplotly หรือทำเป็น Production Dashboard ด้วย shiny
Models
มาถึงจุดแข็งอีกหนึ่งอย่างของภาษา R นั่นคือการทำโมเดลทางสถิติ หรือ Machine Learning พื้นฐานที่ทำงานกับ Structured Data ในตัวอย่างนี้ เราลองดาวน์โหลดและติดตั้ง Caret และเทรนโมเดล Linear Regression ง่าย ๆ จบใน 1-2 บรรทัด
install.packages("caret")
library(caret)
lm_model <- train(mpg ~ hp + wt, data = mtcars, method = "lm")
lm_modelผลลัพธ์ที่ได้จาก train() function จะออกมาเป็น Bootstrapped Error ของ Regression เช่น RMSE, Rsquared หรือ MAE ถ้าเราต้องการเทรนโมเดลอื่น ๆ ที่ไม่ใช่ Linear Model สามารถเปลี่ยนชื่อโมเดลได้ที่ Argument Method โดย Caret เป็น Interface ที่สามารถเทรนได้มากกว่า 200 โมเดล ดูรายชื่อโมเดลที่ Caret รองรับได้ที่ github topepo-caret

Linear regression output
R มีฟังก์ชันดี ๆ ให้ใช้งานอีกหลายตัว ตั้งแต่ Tidyverse, Caret, mlr, Tidymodels, Shiny ส่วนใหญ่มี Online Resources ให้เราศึกษาได้ฟรี (ลอง Google เพิ่มเติมได้เลยนะครับ) ครอบคลุมหลายงานในสาย Data แต่จะเน้นหนักหน่อยที่ Statistics และ Data Analysis
Tips for Learning R
สำหรับทุกคนที่อยากเรียนและฝึกฝน R ต่อ เราแนะนำดาวน์โหลด cheatsheets ของ RStudio มาเก็บไว้ติดตัวได้เลย เค้าทำสรุป Functions สำคัญให้เราไว้หมดแล้ว มีตั้งแต่การทำ Data Transformation, Data Visualization ไปจนถึงการจัดการ String, Factor และอีกมากมาย (อัพเดทใหม่ทุกปี)

ขอให้ทุกคนสนุกกับการเขียนภาษา R นะครับ
บทความโดย กษิดิศ สตางค์มงคล
ตรวจทานและปรับปรุงโดย อนันต์วัฒน์ ทิพย์ภาวัต

Data Analyst - DataRockie






