
Log เป็นข้อมูลที่ได้มาจากระบบคอมพิวเตอร์ ซึ่งทำหน้าที่ในการบันทึกรายละเอียดข้อมูลการทำงานต่าง ๆ ของระบบ ช่วยให้ผู้พัฒนาและผู้ดูแลระบบสามารถเข้าใจการทำงานของระบบ วิเคราะห์พฤติกรรมที่ผิดปกติและสามารถแก้ไขได้อย่างทันท่วงที ในระบบที่มีขนาดใหญ่ขึ้นทำให้ปริมาณของ Log นั้นเพิ่มตามไปด้วย การอ่านข้อมูล Log ทั้งหมดด้วยตนเองจึงทำได้ยาก Log parser จึงเข้ามาช่วยแก้ปัญหาตรงนี้ โดย Log parser นั้นจะทำให้ข้อมูล Log ที่ไม่มีโครงสร้างชัดเจน กลายเป็น Log template ที่มีโครงสร้างมากขึ้นกว่าเดิมได้
การสร้าง Log จากในระบบคอมพิวเตอร์นั้น จำเป็นต้องมี Template ที่มนุษย์เขียนให้ เช่น “Sending <*> quality objects” จะเห็นได้ว่า Template ดังกล่าวมีช่องว่าง (Placeholder) ที่ด้วยสัญลักษณ์ “<*>” ให้คอมพิวเตอร์สามารถเติมค่าต่าง ๆ ที่เรียกกว่า Parameter ลงไปได้ ซึ่งจาก Template ดังกล่าวสามารถสร้างเป็น Log ได้หลายรูปแบบดังนี้
- Sending 0 quality objects
- Sending 90 quality objects
- Sending 2 quality objects
จะเห็นได้ว่าจาก Template เพียงอันเดียว สามารถสร้าง Log ที่แตกต่างกันได้จำนวนนับไม่ถ้วน การทำงานของ Log parser นั้นเสมือนกันการทำย้อนกลับจากสิ่งที่กล่าวไปข้างต้น Log parser จะทำหน้าที่แยก Parameter และ Template ออกจากกัน ทำให้การวิเคราะห์ Template ที่มีจำนวนไม่มากนักนั้นทำได้ง่ายกว่า
Log parser approaches
การทำ Log parser นั้นสามารถทำได้หลายวิธี ซึ่งสามารถแบ่งได้ตามยุคสมัยดังนี้
- Rule-based pattern matching
- Heuristic-based
- Machine-learning-based
- LLM-based
Rule-based pattern matching
เนื่องจากในบางครั้ง Parameter ของ Log มักจะมีลักษณะที่ตายตัว เช่น IP, Email, ตัวเลข, เวลา เป็นต้น ทำให้เราสามารถเขียนเป็นกฏในการแยก Paremeter ในแต่ละรูปแบบออกมาได้ โดยการใช้ Regular Expressions (Regex) เช่น
- IP สามารถใช้ Pattern ดังนี้ “\d{1,3}(?:\.\d{1,3}){3}”
- ตัวเลขที่มีทศนิยม สามารถใช้ Pattern ดังนี้ “\d+(?:\.\d+)*”
ข้อดี
- การใช้ Regex ในการจับ Pattern นั้นค่อนข้างตรงไปตรงมา ถ้าสามารถเขียน Regex ให้ครอบคลุมได้ จะได้ผลของการทำ Log parser ที่ดีมาก
- สามารถควบคุมและอธิบายการทำงานของ Log parser ได้
ข้อเสีย
- จำเป็นต้องเข้าใจลักษณะของข้อมูล Log เป็นอย่างละเอียด จึงจะสามารถเขียน Regex ที่ครอบคลุมออกมาได้ การเขียน Regex ที่ไม่ครอบคลุม อาจจะทำให้ได้ผลที่แย่ได้ เช่น “\d{1,3}(?:\.\d{1,3}){3}” สามารถใช้จับ IP ได้ แต่ไม่สามารถจับ IP มีเลข Port ได้
- ไม่เหมาะกับการใช้กับข้อมูลที่มีจำนวนมาก เพราะอาจจะไม่สามารถหา Pattern ที่สามารถใช้กับข้อมูลทั้งหมดได้
- บาง Pattern นั้นอาจจะไม่สามารถเขียน Regex จับแบบตรง ๆ เช่น Username
Heuristic-based
ในกรณีที่ข้อมูล Log เริ่มมีขนาดใหญ่ขึ้น การทำ Rule-based pattern matching จึงเริ่มทำได้ยาก แต่อย่างไรก็ตามข้อมูล Log ที่มาจาก Template เดียวกันนั้น ถ้านำมาเปรียบเทียบกันในระดับคำต่อคำนั้น จะพบว่าในบางส่วนจะมีตัวอักษรที่เหมือนกัน 100% ซึ่งส่วนนั้นจะมาจาก Template ที่เรากำหนดไว้ตั้งแต่ต้น และอีกส่วนที่ไม่เหมือนกันจะเป็น Parameter ที่ถูกใส่เข้าไปใน Template เพื่อใช้สร้าง Log
ด้วยแนวคิด Heurictic นี้ถ้าเราสามารถแยกได้ว่า Log ใดอยู่ Template เดียวกันได้อย่างแม่นยำ จะได้สามารถแยกส่วนที่เป็น Template กับ Parameter ออกจากกันได้อย่างง่ายดาย ทำให้มี Algorithm จำนวนมากถูกสร้างขึ้นมาโดยมีพื้นฐานจากแนวคิดดังกล่าว เช่น Drain, Prefix-graph
Drain
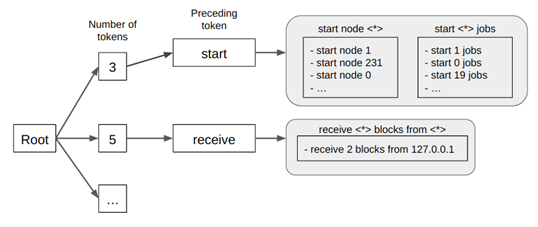
Drain (He et al., 2017) เป็น Algorithm ในการ Parse log โดยใช้ต้นไม้ความลึกคงที่ (Fixed depth tree) ซึ่งโครงสร้างของต้นไม้จะใช้เพื่อค่อยแยกแต่ละ Template ออกจากกัน จากที่แสดงในรูปที่ 1 จะเห็นว่า Template ของ Log จะถูกเก็บอยู่ที่ใบ (Leaf node) ของต้นไม้ แม้ว่าในแต่ละใบอาจจะมีมากกว่าหนึ่ง Template แต่การใช้โครงสร้างดังกล่าวเป็นการลดจำนวน Template ที่จำเป็นต้องคำนึงในแต่ละรอบการวิเคราะห์ Log ได้
การ Parse log โดยใช้ Drain นั้นจะเริ่มที่ราก (Root node) ของต้นไม้ จากนั้นเดินทางตามทิศทางของกิ่งต้นไม้ที่ตรงตามเงื่อนไขของ Log ที่มีไปเรื่อยๆ จนกว่าจะถึงใบ หลังจากนั้นจะเป็นการค้นหาต่อว่า Log ใหม่ที่ถูกใส่เข้ามานั้นมีความคล้ายกับ Template ใดที่อยู่ในใบนั้นมากที่สุด ซึ่งสามารถแบ่งเป็น 2 กรณี
- Log ใหม่สามารถหา Template ที่คล้ายกันได้ จะถูกเพิ่มเข้าไปใน Template นั้น แล้วทำการอัพเดท Template ให้ถูกต้อง โดยใช้แนวคิด Heurictic ที่กล่าวข้างต้น
- Log ใหม่ไม่สามารถหา Template ที่คล้ายกันได้ Template ใหม่จะถูกสร้างขึ้น
ข้อดี
- ไม่จำเป็นต้องสำรวจข้อมูลเพื่อเขียนกฏเหมือนกับวิธีแบบ Rule-based
- หลังจากที่ Drain ได้ Parse log ไปเรื่อยๆ ต้นไม้จะเริ่มมีความซับซ้อนมากขึ้น แต่ด้วยความที่เป็นต้นไม้ความลึกคงที่ ทำให้การ Parse log นั้นไม่ได้เสียเวลาเพิ่มมากนักเมื่อเทียบกับข้อมูลจำนวนมากที่ถูกใส่เข้ามา
ข้อเสีย
- จากรูปที่ 1 จะเห็นว่าเงื่อนไขแรกในการแตกกิ่งต้นไม้คือ จำนวนคำใน Log ซึ่งถ้า Log ใน Template เดียวกันแต่มีจำนวนคำที่ต่างกัน อาจจะทำให้การ Parse เกิดความผิดพลาดได้ และเงื่อนไขต่อ ๆ ไป ในการแตกกิ่งนั้นมักจะเป็นการตรวจสอบคำที่อยู่ในแต่ละตำแหน่งใน Log ว่าตรงกับเงื่อนไขหรือไม่ ด้วยเงื่อนไขในการแตกกิ่งดังกล่าวอาจจะสามารถจัดการกับ Log ที่มีความซับซ้อนต่ำได้อย่างไม่ยาก ในทางกลับกัน Log ที่มีความซับซ้อนสูง หรือจำนวนคำไม่คงที่ก็ยังเป็นปัญหาที่ท้าทายสำหรับ Drain
Machine-learning-based
ในบางกรณีการใช้กฏทั่วไปอาจจะไม่ครอบคลุมข้อมูล Log ที่เกิดขึ้น และวิธีแบบ Heuristic อาจจะยังไม่ได้รับมือกับ Log ที่มีความซับซ้อนสูงได้ การใช้โมเดลที่ผ่านการเรียนรู้จากข้อมูล Log จำนวนมากจึงเป็นอีกแนวทางหนึ่งที่ทำได้ ข้อสังเกตของการใช้ Machine learning คือ จำเป็นต้องมีชุดข้อมูลสำหรับสอนโมเดล ในกรณี Log นั้นอาจจะมีจำนวนข้อมูลมากก็จริง แต่ก็ไม่มีการกำกับข้อมูลว่า Log นั้นอยู่ใน Template ใด และด้วยจำนวนข้อมูลที่มหาศาลทำให้การสร้างชุดข้อมูลนั้นอาจทำได้ยาก ดังนั้นวิธีการใช้ Machine learning ที่จะกล่าวต่อไปนี้ทั้งหมดจะเป็นวิธีที่ไม่จำเป็นต้องใช้ชุดข้อมูลที่มีการกำกับแล้ว หรือใช้เพียงเล็กน้อยเท่านั้น
LogStamp
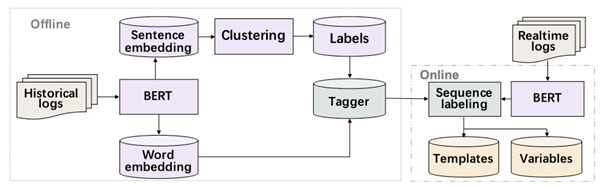
LogStamp (Tao et al. 2022) เป็นโมเดลที่สามารถเรียนรู้ได้เองโดยไม่จำเป็นต้องกำกับข้อมูล ซึ่งการทำงานของ LogStamp นั้นเป็นไปดังรูปที่ 2 เริ่มจาก Historical logs หรือคือข้อมูล Log ที่มีอยู่ โดยไม่มีการกำกับข้อมูล ข้อมูลดังกล่าวจะถูกนำไปหา Sentence embedding และ Word embedding ผ่านการใช้ Bidirectional Encoder Representations from Transformers (BERT) ซึ่งเป็นโมเดลทางภาษาที่ใช้กันอย่างแพร่หลายมากในช่วงปี 2018 ซึ่งการหา Embedding นั้นเหมือนเป็นการวิเคราะห์ความหมายของ Log โดยใช้โมเดลทางภาษา ผลลัพธ์ที่ได้จะเป็น Vector ที่สามารถนำมาคำนวนทางคณิตศาสตร์ได้ ซึ่ง Sentence embedding ที่ได้ออกมานั้นจะเป็นความหมายถึง Log ในระดับประโยค ซึ่งจะถูกนำไปใช้ในการจับกลุ่ม (Clustering) กลุ่มที่ได้นั้นจะถูกตีความว่าเป็น Template ของ Log ดังกล่าวทันที ซึ่ง Log ที่อยู่ในกลุ่มเดียวกัน ก็คือเกิดมาจาก Template เดียวกันนั่นเอง ซึ่ง Template ที่ได้จากวิธีนี้จะถือว่าเป็นการกำกับข้อมูล Log ไปในตัวเลย ซึ่งวิธีการใช้โมเดลในการกำกับข้อมูลแทนคนแบบนี้มีชื่อเรียกกว่า Pseudo-labeling
หลังจากที่ได้ข้อมูลที่มีการกำกับเรียบร้อยมาแล้ว จะใช้ Word embedding หรือก็คือความหมายของ Log ในระดับคำ ร่วมกับ Template ที่ได้มาจากขั้นตอนก่อนหน้าในการสอนโมเดล Machine learning ที่ทำหน้าที่ทำนายว่าคำแต่ละคำใน Log คือใดที่เป็นส่วนของ Parameter หรือเป็นส่วนของ Template ซึ่งหลังจากสอนโมเดลเรียบร้อยแล้ว จึงจะสามารถนำไปใช้ Parse Log ที่เข้ามาใหม่ได้
ข้อดี
- ไม่จำเป็นต้องกำกับข้อมูล Log ก็สามารถสร้างโมเดลสำหรับ Log parser ได้
ข้อเสีย
- เนื่องจากไม่มีการกำกับข้อมูลโดยมนุษย์เลย จึงมีโอกาสที่การทำ Pseudo-labeling นั้นจะทำให้เกิดข้อมูลที่ผิดออกมาได้ ซึ่งอาจส่งผลให้การทำงานของโมเดลนั้นแย่ลง
LogPPT
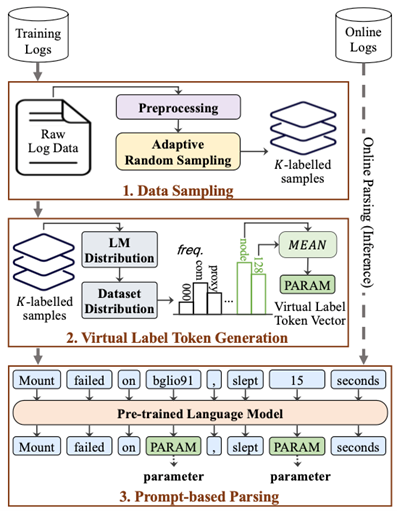
LogPPT (V. Le & Zhang 2023) เป็นอีกวิธีที่ไม่จำเป็นต้องใช้ข้อมูลจำนวนมากในการสอนโมเดล ซึ่งแนวคิดของ LogPPT คือการกำกับข้อมูลเพียงเล็กน้อย ที่มีความหลากหลายมากพอนั้น เพียงพอที่จะสอนโมเดลทางภาษาในการทำ Log parser ได้
โดยปกติแล้วโมเดลทางภาษานั้นจะมีคลังคำศัพท์อยู่ในตัวที่ครอบคลุมข้อมูลที่ใช้สอนโมเดลนั้น เพื่อจะให้โมเดลทางภาษาสามารถทำ Log parser ได้ จึงต้องเพิ่มคำพิเศษ “PARAM” ให้กับโมเดล ซึ่งคาดหวังว่าเมื่อโมเดลเจอส่วนของ Log ที่เป็น Parameter ให้โมเดลตอบเป็นคำพิเศษนี้ออกมา แต่ถ้าเจอส่วนที่เป็น Template ให้ตอบด้วยคำเดิมออกมา อย่างไรก็ตามคำที่อยู่ในคลังคำศัพท์ทั้งหมดของโมเดลทางภาษานั้นโมเดลจะเข้าใจความหมายของคำนั้นจากการเรียนรู้จากข้อมูลที่สอน แต่การเพิ่มคำศัพท์ใหม่เข้าไป ทำให้โมเดลไม่อาจเข้าใจความหมายของคำนี้ได้เลย ดังนั้น LogPPT จึงจำเป็นข้อมูลที่ใช้สอนโมเดลเล็กน้อย เพื่อให้สามารถเข้าใจความหมายของคำพิเศษที่เพิ่มเข้าไปได้ จากการทดลองของ LogPPT พบว่าถ้ามีข้อมูลเพียง 8-32 Log ที่ถูกเลือกมาโดย Adaptive Random Sampling ซึ่งจะได้ข้อมูลที่กระจายตัวความครอบคลุมข้อมูลทั้งหมด ก็สามารถสอนโมเดลให้สามารถทำ Log parser ได้แล้ว
ข้อดี
- ใช้ข้อมูล Log สำหรับสอนโมเดลจำนวนไม่มาก
- สามารถจัดการ Log ที่มีความซับซ้อนได้
ข้อเสีย
- ในการ Parse log ใช้เวลาค่อนข้างนานกว่าวิธีแบบ Heuristic หรือ Rule-based
- ควบคุมการทำงานของ Log parser ได้ยากกว่าวิธีแบบ Heuristic หรือ Rule-based
Prompt-based
ในยุคปัจจุบันนั้นโมเดลทางภาษาได้พัฒนาไปอีกขั้น เห็นได้จากการมาของ Generative AI เช่น ChatGPT, Bart และอื่น ๆ อีกมากมาย ที่สามารถตอบคำถามของมนุษย์ได้ดีอย่างมาก ทำให้มีการทดลองใช้โมเดลเหล่านี้ในการทำ Log parser ด้วย จากการทดลองของ V. Le & Zhang (2023) ได้ลองใช้ Prompt ที่มีความซับซ้อนต่างกันในการทำ Log parser ดังรูปที่ 4 พบว่าการใช้ Prompt มีความละเอียดมากกว่านั้นทำให้ผลของ Log parser ออกมาดีกว่า นอกจากนั้นยังมีการทดลองเกี่ยวกับ Few-shot prompt หรือ Prompt ที่มีตัวอย่างให้ ซึ่งผลที่ได้ก็คือยิ่งมีตัวอย่างที่มากทำให้ผลของ Log parser ดีขึ้นตามไปด้วย
อย่างไรก็ตามการทำ Prompt engineer นั้นมีการศึกษามากขึ้น ซึ่งอาจจะมีวิธีในการออกแบบ Prompt ให้ได้ผลลัพธ์ออกมาดียิ่งขึ้น เช่น Chain-of-thought (CoT) หรือ Retrieval-Augmented Generation (RAG) ซึ่งวิธีเหล่านี้อาจจะสามารถพัฒนาการทำ Log parser ได้ดียิ่งขึ้นไปอีก

ข้อดี
- ไม่จำเป็นต้องมีข้อมูล Log สำหรับสอนโมเดล และไม่ต้องสร้างโมเดลด้วยตนเอง
- สามารถจัดการ Log ที่มีความซับซ้อนได้
ข้อเสีย
- ในการ Parse log ใช้เวลาค่อนข้างนาน และอาจเสียค่าใช้จ่ายในการทำ Log parser
- ความยาว Prompt ส่งผลต่อประสิทธิภาพของ Log parser (การใช้ prompt ที่ละเอียด หรือมีตัวอย่างให้โมเดล จะทำให้ความยาว Prompt มากขึ้น)ในทางกลับกันจะทำให้เสียเวลาการประมวลผล และค่าใช้จ่ายมากขึ้นตามไปด้วย
- ในกรณีที่ทำโมเดลทำงานพลาด อาจจะอธิบายได้ยากว่าอะไรเป็นสาเหตุให้โมเดลทำออกมาพลาด
บทความโดย ภูมิภพ สุวรรณาภิชาติ
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์
เอกสารอ้างอิง
- Chen, T. Y., Leung, H., & Mak, I. K. (2005). Adaptive random testing. Advances in Computer Science-ASIAN 2004. Higher-Level Decision Making: 9th Asian Computing Science Conference. Dedicated to Jean-Louis Lassez on the Occasion of His 5th Birthday. Chiang Mai, Thailand, December 8-10, 2004. Proceedings 9, 320–329.
- Fu, Y., Yan, M., Xu, J., Li, J., Liu, Z., Zhang, X., & Yang, D. (2022). Investigating and improving log parsing in practice. Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 1566–1577.
- He, P., Zhu, J., Zheng, Z., & Lyu, M. R. (2017). Drain: An online log parsing approach with fixed depth tree. 2017 IEEE International Conference on Web Services (ICWS), 33–40.
- Jiang, Z., Liu, J., Chen, Z., Li, Y., Huang, J., Huo, Y., He, P., Gu, J., & Lyu, M. R. (2023). LLMParser: A LLM-based Log Parsing Framework.
- Le, V., & Zhang, H. (2023). Log Parsing with Prompt-based Few-shot Learning. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2438–2449. https://doi.ieeecomputersociety.org/10.1109/ICSE48619.2023.00204
- Le, V.-H., & Zhang, H. (2023). Log Parsing: How Far Can ChatGPT Go?
- Ma, R., Zhou, X., Gui, T., Tan, Y., Li, nyang L., Zhang, Q., & Huang, X. (2022). Template-free Prompt Tuning for Few-shot NER. In M. Carpuat, de Marneffe, & M. Ruiz (Eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 5721–5732). Association for Computational Linguistics. https://aclanthology.org/2022.naacl-main.420
- Tao, S., Meng, W., Cheng, Y., Zhu, Y., Liu, Y., Du, C., Han, T., Zhao, Y., Wang, X., & Yang, H. (2022). LogStamp: Automatic Online Log Parsing Based on Sequence Labelling. SIGMETRICS Perform. Eval. Rev., 49(4), 93–98. https://doi.org/10.1145/3543146.3543168Zhang, T., Qiu, H., Castellano, G., Rifai, M., Chen, C., & Pianese, F. (2023). System Log Parsing: A Survey. IEEE Transactions on Knowledge & Data Engineering, 35(08), 8596–8614. https://doi.org/10.1109/TKDE.2022.3222417

Master's degree student
King Mongkut's University of Technology Thonburi








