
ปัจจุบันนี้ หลายสิ่งรอบที่มีผลกระทบกับตัวเราทั้งทางตรง และ ทางอ้อม ล้วนแล้วมีการพยากรณ์ค่าในอนาคตด้วยกันทั้งนั้น
ไม่ว่าจะเป็น การพยากรณ์อุณหภูมิ 24 ชั่วโมงข้างหน้า ที่ช่วยให้เราพอจะคาดการณ์ได้ว่า จะหนาว หรือ จะร้อน การพยากรณ์ปริมาณฝุ่น PM2.5 ที่เป็นภัยต่อระบบทางเดินหายใจ การพยากรณ์ปริมาณน้ำฝน ที่ส่งผลต่อการวางแผนใช้ชีวิต หรือ กระทั่งการพยากรณ์จำนวนรถยนต์บนท้องถนน ซึ่งส่งผลต่อการวางแผนเดินทางของเราเป็นอย่างมาก
นอกจากนั้นแล้ว ในโลกของธุรกิจ ก็ยังมีการพยากรณ์เชิงตัวเลขมากมาย ไม่ว่าจะเป็น การประมาณการยอดขาย (Sale Forecasting) การประมาณการสินค้าคงคลัง (Inventory Forecasting) หรือ การประมาณการรายจ่าย (Cost Forecasting) ซึ่งทั้งหมดนี้ก็ล้วนแล้วแต่เป็นการพยากรณ์ตัวเลขในอนาคตทั้งสิ้น
และเราเมื่อพูดถึงอนาคต ทุกคนต่างทราบกันดีว่า เป็นเรื่องที่ไม่แน่นอน การพยากรณ์ก็เช่นกัน แต่เราจะมีวิธีการ หรือ เครื่องมือชนิดใดบ้าง ที่จะมาช่วยให้การพยากรณ์เชิงตัวเลขเหล่านี้ มีความแม่นยำมากขึ้น น่าเชื่อถือมากขึ้น พร้อมทั้ง ลดความคลาดเคลื่อนของตัวเลขคาดการณ์ลง ทุกท่านสามารถหาคำตอบได้จากบทความนี้เลยครับ
Time Series Forecasting คืออะไร ?
ในการพยากรณ์ตัวเลข เราสามารถใช้ประโยชน์จากข้อมูลในอดีตมาพิจารณาว่า ค่าที่ควรจะเป็น ในอนาคตควรเป็นเท่าใดได้ โดยส่วนใหญ่แล้ว ค่าในอนาคต มักจะมีความสัมพันธ์กับค่าที่เกิดขึ้นจริงในอดีต (Historical data) ดังนั้น ในบทความนี้ เราจึงเลือกเครื่องมือที่จะมาตอบโจทย์การพยากรณ์นี้ เป็นเครื่องมือที่มีชื่อเรียกว่า Time-Series Forecasting (หรือ เรียกแบบไทย ๆ ว่า การพยากรณ์แบบอนุกรมเวลา) โดยเครื่องมือชนิดนี้ จะให้ความสำคัญ กับ ลำดับการเกิดขึ้นของข้อมูล (Order) และ ค้นหาแนวโน้ม (Trend) รวมถึง ฤดูกาล (Seasonal) ที่เกิดขึ้นบนข้อมูลในอดีต และนำมาเป็นปัจจัยในการพยากรณ์ตัวเลขในอนาคต
Time-series Dataset หน้าตาเป็นอย่างไร ?
เรามาดูตัวอย่างของข้อมูลประเภท Time-Series กัน ว่ามีหน้าตาและลักษณะเป็นอย่างไร โดยในบทความนี้ เราจะใช้ข้อมูลจำนวนผู้โดยสารสายการบินแห่งหนึ่งกันครับ
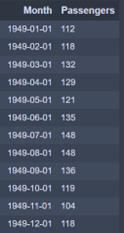
จากตัวอย่างใน ภาพที่ 1 จะเห็นว่า ข้อมูล Time-series มีการเรียงตัวกันเป็นลำดับของข้อมูลที่ครบถ้วน โดยจัดเก็บเป็นรายเดือนเริ่มต้นตั้งแต่ปี 1949 ไปจนถึง 1960 รวมทั้งสิ้น 144 เดือน ดังนั้นข้อมูลชุดนี้จึงจะเป็นข้อมูลที่สะอาดและพร้อมใช้งานครับ
แต่ถ้าหากข้อมูลที่เรามีอยู่มีบางส่วนขาดหายไป เช่น ไม่มีข้อมูลในบางเดือน เราจำเป็นต้องมีการเติมข้อมูลเดือนที่หายไป เข้าไปก่อนที่จะนำไปใช้งาน โดยการเติมข้อมูลที่หายไปสามารถทำได้หลากหลายวิธี แต่วิธีที่ง่ายที่สุด อาจจะเป็นการอนุมานว่า ข้อมูลเดือนที่หายไปนั้น เป็นเพราะไม่มีผู้โดยสารเครื่องบินสายการบินนี้เลย ทำให้ไม่มีข้อมูลเดือนดังกล่าว และแทนค่าจำนวนผู้โดยสารเท่ากับ 0 ไปเลยก็ได้ครับ ทั้งนี้ก็ขึ้นอยู่กับข้อมูลและความเข้าใจในข้อมูลชุดนั้น ๆ ของเจ้าของข้อมูลครับ
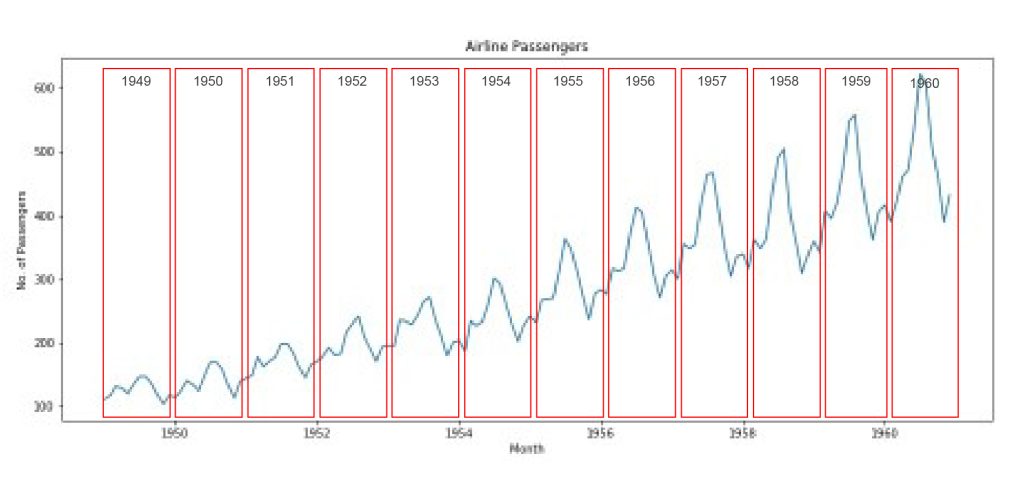
ทีนี้ เรามาลองดูข้อมูลกันต่อใน ภาพที่ 2 ซึ่งจะเป็นกราฟเส้นแสดงการเปลี่ยนแปลงของจำนวนผู้โดยสารในแต่ละเดือน กราฟนี้ทำให้เราเห็นว่า จำนวนผู้โดยสารของสายการบินนี้ มีรูปแบบการเปลี่ยนแปลงที่ค่อนข้างชัดเจน (มี Pattern) นั่นคือ เริ่มต้นปีด้วยการไต่ระดับขึ้นไปจนถึงจุดพีคที่ช่วงกลางปี จากนั้นลดลงในช่วงปลายปี อยากให้ทุกท่านสังเกตภายในแต่ละกรอบสีแดง ซึ่งจะแสดงรูปแบบของจำนวนผู้โดยสารรูปแบบคล้ายคลึงกัน ซ้ำ ๆ วนไปทุก ๆปี ทำให้เราเกิดความคิดว่า จำนวนผู้โดยสารของสายการบินนี้ น่าจะสามารถคาดการณ์ได้ ดังนั้น เราจึงจะมาดูกันต่อว่า เราจะทำให้หุ่นยนต์ หรือ คอมพิวเตอร์ ตีความและพยากรณ์โดยอ้างอิงจากสิ่งเหล่านี้ได้เหมือนกับเราซึ่งเป็นมนุษย์ได้อย่างไรกันล่ะ เรามาดูกันครับ
Prophet: Time Series Forecasting Model from Facebook (Meta)
พระเอกของเราในวันนี้คือ โมเดลที่ใช้ชื่อว่า Prophet ซึ่งเป็นโมเดลที่ทางทีมวิจัยของ Facebook เป็นผู้พัฒนาขึ้นมา แต่ก่อนที่เราจะไปดูวิธีการใช้งานเจ้า Prophet ผมขอพาคุณผู้อ่านทุกท่านมารับชมกรรมวิธีเบื้องหลัง ซึ่งเป็นแก่นแกนของ Prophet กันก่อน
Seasonal Decomposition
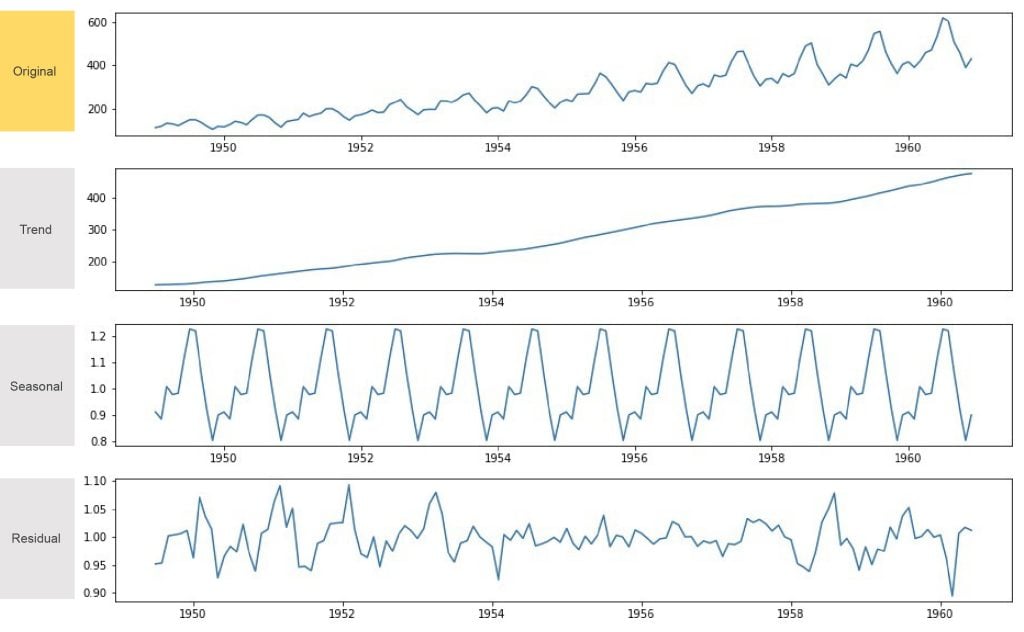
ในการพยากรณ์แต่ละค่าของโมเดล จะอ้างอิงจากหลาย ๆ ปัจจัย แต่โดยพื้นฐานแล้วมักจะมาจากการ ค้นหา แนวโน้ม (Trend) และ ฤดูกาล (Seasonal) เป็นหลัก โดยอาจจะมีปัจจัยอื่นๆเข้ามาเสริมเติมให้มีความแม่นยำมากยิ่งขึ้น ซึ่งการจะได้มาซึ่ง Trend และ Seasonal จะมีกรรมวิธีที่มีชื่อเรียกทางเทคนิคว่า Seasonal Decompose แปลเป็นภาษาที่เข้าใจง่ายๆ ก็คือ การนำข้อมูลใน ภาพที่ 2 มาแยกส่วนออกเป็น 3 ส่วน ได้แก่ Trend, Seasonal และ Residual โดยสามารถดู Fig 3 ประกอบครับ
- Trend คือ ส่วนที่บ่งบอกแนวโน้มของข้อมูลว่าจะไปในทิศทางใด ถ้ารูปแบบของข้อมูลเป็นขาขึ้น (จำนวนผู้โดยสารเพิ่มขึ้นเรื่อยๆ ทุกๆ ปี) เส้น Trend ก็จะเอียงขึ้น เป็นต้น
- Seasonal คือ ส่วนที่บ่งบอกว่า ฤดูกาล หรือ ช่วงเวลา มีผลต่อจำนวนผู้โดยสารหรือไม่ ถ้าหากฤดูกาลมีผลต่อจำนวนผู้โดยสาร ข้อมูลในส่วนของ Seasonal จะต้องมีการแสดงที่ชัดเจน ตัวอย่างเช่น ค่าของ seasonal พุ่งขึ้นสูงในช่วงเดือน 9 – 10 ของทุกๆ ปี และ ตกลงในช่วงปลายปี ทำให้เห็นว่า ฤดูกาลมีผลต่อจำนวนผู้โดยสารของสายการบินนี้นั่นเอง
- Residual คือ ส่วนที่เราอาจจะเรียกว่า Noise ของข้อมูลก็ได้ เพราะ มันคือ ส่วนที่เพิ่มเติมมาจาก 2 ส่วนแรก หากข้อมูลเป็นเหมือนเดิมเป๊ะๆ ในทุก ๆ ปี มีจำนวนผู้โดยสารแต่ละเดือนที่เท่า ๆ กัน Residual ก็จะเป็นศูนย์ แต่ในความเป็นจริงมันไม่เป็นเช่นนั้น ดังนั้น Residual ก็เปรียบเสมือนส่วนของความผันผวนที่ทำให้ข้อมูลจริงๆ เกิดการหลุดออกจาก เส้นที่เกิดจาก Trend & Seasonal นั่นเองครับ
ตัวอย่าง python code
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
## -- อ่านข้อมูล airline passenger
df = pd.read_csv('airline-passengers.csv', dtype=str)
## -- Preprocessing
df['Month'] = pd.to_datetime(df['Month'])
df['Passengers'] = df['Passengers'].astype('int32')
## -- กำหนดให้ Month เป็น Index
df.set_index('Month', inplace=True)
## -- ทำ Seasonal Decompose
result = seasonal_decompose(df['Passengers'], model='multiplicative')
## ==============================
## -- แสดงผลเป็นกราฟแบบ Fig 3
## ==============================
## -- Plot the original time series
plt.figure(figsize=(12, 8))
plt.subplot(4, 1, 1)
plt.plot(df['Passengers'], label='Original')
plt.legend(loc='upper left')
## -- Plot the trend component
plt.subplot(4, 1, 2)
plt.plot(result.trend, label='Trend')
plt.legend(loc='upper left')
## -- Plot the seasonal component
plt.subplot(4, 1, 3)
plt.plot(result.seasonal, label='Seasonal')
plt.legend(loc='upper left')
## -- Plot the residual component
plt.subplot(4, 1, 4)
plt.plot(result.resid, label='Residual')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
How to train Prophet
เมื่อเราเข้าใจพื้นฐานการทำงานของ Prophet กันแล้ว ทีนี้เรามาดูกันว่า เราจะสอนเจ้า Prophet ให้เป็นเครื่องมือในการพยากรณ์อนาคตให้กับเราได้อย่างไรกัน โดยเนื้อหาในส่วนนี้จะแบ่งออกเป็น 5 Step ค่อย ๆ ทำตามไปทีละ Step นะครับ
ก่อนที่จะเริ่มต้น ผมขอใช้พื้นที่ตรงนี้ในการ Clarify Specification ของ Environment ที่ผมใช้ในการทำตัวอย่างประกอบบทความนี้ครับ เพื่อเป็น Reference ให้คุณผู้อ่านสามารถติดตั้งตาม environment ของผมได้ครับ
OS: Window 10
Python: 3.10.10
prophet: 1.1.5
numpy: 1.21.6
pandas: 2.0.1
statsmodels: 0.10.1
Step 1: Prophet Installation (ติดตั้งเจ้า Prophet กันก่อน)
ก่อนอื่นผมขอให้ทุกท่านทำการติดตั้ง Library Prophet กันก่อนครับ โดยการติดตั้งนั้นไม่ยากเลย เหมือนกับการลง Library ของ python ทั่วๆไป (หากท่านยังไม่มี Python โปรดทำการลง Python ให้เรียบร้อยก่อนครับ)
pip install prophet==1.1.5
pip install cmdstanpyเมื่อติดตั้งเสร็จแล้ว ให้ทำการ import library ตามด้านล่างนี้ และทำการ install ตัว cmdstanpy ให้เสร็จสมบูรณ์ แล้วจึงจะใช้งาน Library Prophet ได้ (ในขั้นตอนนี้อาจจะใช้เวลาในการติดตั้งค่อนข้างนานสักหน่อยครับ)
from prophet import Prophet
import cmdstanpy
cmdstanpy.install_cmdstan(compiler=True)Step 2: Data Preparation (เตรียมข้อมูลให้พร้อมสำหรับการเทรนโมเดล)
เมื่อติดตั้งเสร็จเรียบร้อยแล้ว จะสามารถใช้งาน Library Prophet ได้ โดยการใช้งานนั้นง่ายมาก ๆ เพียงทุกท่านเตรียมข้อมูลที่มี 2 Columns โดยประกอบไปด้วย 1) ds คือ ข้อมูลประเภทวันที่ และ 2) y คือ ข้อมูลประเภทตัวเลข (ค่าที่เราอยากจะพยากรณ์ เช่น ยอดขาย เป็นต้น)
อ้างอิงจากตัวอย่างด้านบน เราจะใช้ข้อมูล Airline Passenger ซึ่งเราจะทำการเปลี่ยนชื่อ Column จาก Month ให้เป็น ds และ Passengers ให้เป็น y ตามที่ prophet ต้องการครับ
df = df.rename(columns={'Month': 'ds', 'Passengers': 'y'})Step 3: Fit the Prophet model (สร้างโมเดล Prophet กันเถอะ)
เมื่อข้อมูลพร้อม เราจะทำการสร้างโมเดล Prophet ขึ้นมาจากข้อมูลของเราเตรียมไว้ ซึ่งการสร้างและเทรนโมเดลนั้นทำได้ง่ายมากครับด้วยโค้ด 2 บรรทัดนี้ครับ เพียงเท่านี้ เราก็จะได้โมเดลที่พร้อมจะทำนายอนาคตให้กับเราแล้วครับ
model = Prophet()
model.fit(df)Step 4: Make future predictions (มาพยากรณ์อนาคตกันเถอะ)
เมื่อเราได้โมเดลมาเรียบร้อยแล้ว ให้นำโมเดลนั้นมาพยากรณ์อนาคตกันครับ โดยคุณผู้อ่านสามารถใช้โค้ดจากตัวอย่างด้านล่างเพื่อพยากรณ์ค่าในอนาคตครับ โดยจาก parameter ในตัวอย่าง จะเป็นการพยากรณ์ไปอีก 24 เดือนข้างหน้า ซึ่งดูได้จาก parameter ที่เราใส่เข้าไปในฟังก์ชัน make_future_dataframe โดย periods คือ ระยะเวลาที่จะพยากรณ์ไปในอนาคต ซึ่งหน่วยของระยะเวลา จะดูจาก freq ในที่นี้ ‘M’ คือ Month หรือ เดือนนั่นเอง
future = model.make_future_dataframe(periods=24, freq=’M’)
forecast = model.predict(future)Step 5: Visualize the forecast (แสดงผลออกมาในรูปแบบกราฟ)
เพื่อให้เห็นภาพการพยากรณ์ของโมเดลที่เป็นรูปธรรม เราสามารถใช้สคริปด้านล่างนี้ ในการพล็อตกราฟ ออกมาได้ โดยในกราฟจะแสดงส่วนที่เป็นค่าจริง (Actual Value) เป็นจุดๆ อยู่บนกราฟ และ แสดงส่วนที่เป็นค่าพยากรณ์จากโมเดล (Forecasted Value) จะเป็นกราฟเส้น โดยจะแบ่งเป็น 2 ช่วง ตามสีพื้นที่แรงเงาด้านหลังเส้น ได้แก่ สีฟ้า จะเป็นช่วงข้อมูลในอดีต และ สีส้ม จะเป็นช่วงที่ทำนายไปในอนาคต
fig = model.plot(forecast)
# Customize the plot, change the color of the future period
plt.fill_between(future['ds'][len(df):], forecast['yhat_lower'][ len(df):], forecast['yhat_upper'][ len(df):], color='orange', alpha=0.3, label='Future Period')
plt.title('Airline Passengers\n Forecasting the next 2 years')
plt.xlabel('Month')
plt.ylabel('No. of Passengers')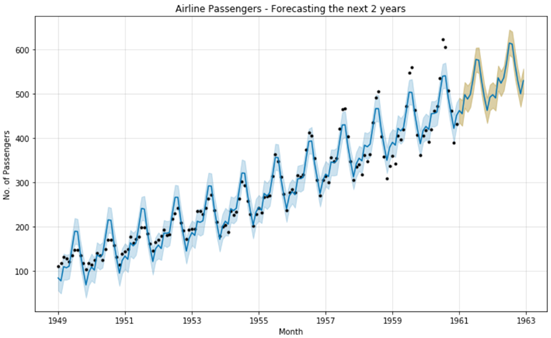
จุดแสดงถึงมูลค่าที่แท้จริง เส้นแสดงถึงมูลค่าที่คาดการณ์ไว้
พื้นที่สีน้ำเงินคือมูลค่าที่คาดการณ์ของอดีต
พื้นที่สีส้มเป็นมูลค่าที่คาดการณ์ในอนาคต
Evaluation: การวัดผลการพยากรณ์
จาก ภาพที่ 4 จะเห็นว่า เส้นพยากรณ์ของโมเดล แม้ว่าจะไม่ได้ตรงเป๊ะกับทุกๆจุดจริงๆ ที่เกิดขึ้น แต่ก็ครอบคลุมและมีแนวโน้มจะสอดคล้องไปตามทิศทางที่จุดเหล่านั้นไปอยู่ ทำให้ผลการพยากรณ์ดูจะมีความน่าเชื่อถือมากขึ้นในระดับที่น่าพอใจ
แต่เราในฐานะผู้ใช้งานผลการพยากรณ์ย่อมต้องการรู้ว่า ความแตกต่างของผลพยากรณ์ กับ ค่าจริง ๆ มีค่าเท่ากับเท่าไร (Error) ซึ่งเพื่อให้เราสามารถตีความ Error ได้ง่าย ในบทความนี้จึงเลือก Mean Absolute Error (MAE) มาใช้ในการวัดผลให้ดูกันครับ (นอกจากนี้ ทุกท่านยังสามารถศึกษาเพิ่มเติมเกี่ยวกับ metric อื่นๆ เช่น MSE หรือ RMSE ซึ่งสามารถใช้วัดผลได้เช่นกัน)
Mean Absolute Error (MAE) คือ การหาค่าเฉลี่ยของ ส่วนต่างระหว่าง ค่าจริง กับ ค่าที่ทำนาย โดยไม่สนเครื่องหมาย หรือ ที่เราเรียกกันว่า เป็นค่า absolute ของผลต่างนั้นๆ โดยสามารถเขียนออกมาเป็นสมการคณิตศาสตร์ ดังนี้

ซึ่งเราได้คำนวนค่า MAE ของโมเดล Prophet ที่เราได้มา พบว่า มีค่าอยู่ที่ 17.38 นั่นหมายความว่า โดยเฉลี่ยแล้ว โมเดลจะทำนายคลาดเคลื่อนไปจากค่าจริงอยู่ที่ประมาณ 17.38 คน หรือ ปัดเป็นตัวเลขเต็มๆ ก็คือ 18 คนนั่นเอง ซึ่งตรงจุดนี้ การจะตัดสินว่าโมเดลนี้ดีพอหรือยัง ก็ขึ้นอยู่กับผู้ใช้งานแล้ว ว่า จะยอมรับความคลาดเคลื่อนนี้ได้หรือไม่ รับได้มากน้อยเพียงใด ครับ
ตัวอย่างโค้ดสำหรับ Evaluation
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
# Evaluate the predictions
y_true = df['y'].values
y_pred = forecast['yhat'].values[:len(df)]
# Calculate evaluation metrics
mae = mean_absolute_error(y_true, y_pred)
print(f'Mean Absolute Error (MAE): {mae}')จากเนื้อหาในบทความนี้ ทุกท่านน่าจะมีความเข้าใจในการจัดการข้อมูลแบบ Time-series มากยิ่งขึ้น และ ผมหวังว่า บทความนี้จะสามารถช่วยให้ทุกท่านเข้าใจการทำงานของ Time-series forecasting model และ สามารถที่จะประยุกต์ความรู้ที่ได้ไปสร้างโมเดลต่อยอดสำหรับส่วนงานของตัวเองได้ และผมเชื่อว่าทุกท่านจะสามารถพัฒนาโมเดลพยากรณ์อนาคตที่เจ๋งๆ ออกมาได้มากมายอย่างแน่นอน เป็นกำลังใจให้ทุกท่านที่พยายามพัฒนาตัวเองอย่างต่อเนื่องครับ แล้วพบกันใหม่ในบทความหน้า จะเป็นเรื่องอะไรอย่าลืมติดตามกันเอาไว้ สำหรับบทความนี้ ผมต้องขอตัวลาไปก่อน ขอบคุณทุก ๆ ท่านที่เข้ามาอ่านกันครับ สวัสดีครับ
เนื้อหาโดย ปุริมพัฒน์ เจียรสุนันท์
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์
เอกสารอ้างอิง
https://github.com/purimpatkring/time-series-forecasting/blob/main/time_series_forecasting.ipynb

Data Scientist at Krungsri Consumer








