
อย่างที่เราได้เคยพูดคุยกันในบทความก่อนๆ แล้ว ในปัจจุบันข้อมูลที่มีลักษณะเป็นข้อความ (text) นั้นมีอยู่เป็นปริมาณมากแต่การประมวลผลข้อมูลเหล่านี้ไม่สามารถทำได้อย่างตรงไปตรงมาและจำเป็นต้องมีการแปรรูปให้อยู่ในลักษณะที่เหมาะสมแก่การนำไปคำนวณได้เสียก่อน ตัวอย่างหนึ่งของเทคนิคการแปรรูปข้อความเพื่อนำไปใช้วิเคราะห์ต่อนั้นก็คือ การทำ TF-IDF เพื่อค้นหาความสำคัญของคำแต่ละคำภายในข้อความ และนำผลลัพธ์มาใช้เป็นตัวแทนของข้อความนั้นๆ (ในรูปแบบของเวกเตอร์ที่แต่ละมิติคือค่า TF-IDF ของแต่ละคำ) อย่างไรก็ดี ในบริบทการประยุกต์ใช้อื่นๆ เช่นในการตรวจสอบความคล้ายคลึงของข้อความ (text similarity) หรือ การนำข้อไปจำแนกหมวดหมู่ (text classification) นั้น การใช้เทคนิค TF-IDF ดังที่ได้ยกตัวอย่างไปนี้ อาจจะไม่เหมาะสมเสมอไป
หลักการในลักษณะของ TF-IDF นั้น เป็นการพิจารณาข้อมูลโดยใช้ตัวคำภายในข้อความโดยตรง เช่น การเปรียบเทียบความคล้ายคลึงของข้อความจากคำที่ปรากฏภายในข้อความหรือการใช้การเปรียบเทียบสัดส่วนการมีอยู่ (occurrence) ของจำนวนคำที่ไม่ซ้ำ (unique words) โดยให้ถือว่าคำคนละคำนั้นแตกต่างกันโดยสิ้นเชิงและไม่มีการนำความใกล้เคียงหรือเกี่ยวข้องกันของคำมาร่วมพิจารณาด้วยเลย ซึ่งหากเรามองจากลักษณะคำในความเป็นจริงแล้ว จะเห็นว่าคำที่สะกดแตกต่างกันนั้น อาจจะมีความหมายที่คล้ายคลึงหรือเหมือนกัน เช่น คำว่า “หมา” และคำว่า “สุนัข” นอกจากนี้ ถึงแม้ว่าคำที่เรานำมาเปรียบเทียบกันอาจมีความหมายที่แตกต่างกัน แต่ระดับของความแตกต่างระหว่างคำคู่หนึ่งก็อาจมีค่าต่างจากความแตกต่างของคำอีกคู่หนึ่ง เช่นถ้าหากเราจะพิจารณาความหมายของคำว่า “ส้ม” กับคำว่า “แอปเปิล” นั้น เราก็จะพบว่าคำทั้งสองมีความหมายที่ใกล้เคียงกันมากกว่าคำว่า “ส้ม” กับคำว่า “สุนัข” เป็นต้น
ในกรณีเช่นนี้นั้น สิ่งที่เราต้องการคือการสร้างตัวแทนเชิงความหมายของคำหรือข้อความต่างๆ ขึ้นมาในรูปของปริมาณเชิงคณิตศาสตร์ เช่น เวกเตอร์ ที่เราจะสามารถนำมาเปรียบเทียบกันได้ โดยคำที่มีความหมายเหมือน/คล้ายกันจะมีค่าของเวกเตอร์ที่ใกล้เคียงกัน และ คำที่มีความหมายไม่คล้ายกันจะมีค่าของเวกเตอร์ที่แตกต่างกัน

แน่นอนว่ากระบวนการการสร้างตัวแทนของข้อความเหล่านี้นั้นถือเป็นอีกหนึ่งเทคนิคด้านการประมวลผลภาษาธรรมชาติ (Natural Language Processing: NLP) สำหรับบทความนี้เราจะมาพูดถึงเทคนิคพื้นฐานในการสร้างตัวแทนเชิงความหมายของคำและข้อความ (word embedding) โดยจะพูดถึงโมเดล 2 โมเดลในตระกูล Word2Vec ได้แก่โมเดล Continuous Bag of Words (CBOW) และ โมเดล Skip-gram
การแปลงข้อมูลข้อความเป็นข้อมูลตัวแทนเชิงคณิตศาสตร์
ในขั้นตอนแรกในการสร้างเวกเตอร์ตัวแทนของข้อความนั้น เราจะต้องทำการรวบรวมและสร้างรายการของคำศัพท์ (Vocabulary) เพื่อพิจารณาจำนวนคำที่เป็นเอกลักษณ์ไม่ซ้ำกับคำอื่น (unique word) ที่ปรากฏอยู่ในข้อความที่เราทำการพิจารณาทั้งหมดก่อนเป็นอันดับแรก จากนั้นจึงแปลงคำแต่ละคำภายในข้อความให้อยู่ในลักษณะของเวกเตอร์ของคำ (word vector) ซึ่งเวกเตอร์ดังกล่าวจะมีจำนวนมิติเท่ากับจำนวนคำใน Vocabulary และแต่ละมิติจะเป็นตัวแทนของคำนั้นๆ ดังนั้น word vector ของแต่ละคำจะมีค่าของมิติที่เป็นตัวแทนของคำนั้นเป็น 1 และค่าในมิติอื่น ๆ เป็น 0
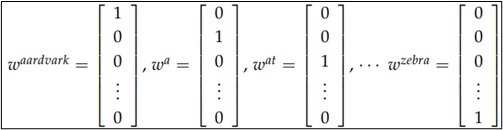
หมายเหตุ: ในขั้นตอนนี้ เราอาจจะเพิ่มมิติขึ้นอีกมิติหนึ่งสำหรับใช้แทนคำที่ไม่ได้อยู่ใน vocabulary แต่ อาจจะพบได้ในอนาคต โดยปกติแล้วคำเหล่านี้จะถูกเรียกรวมๆ ว่า UNK (unknown)
เนื่องจาก word vector เหล่านี้ เป็นตัวแทนของคำที่แตกต่างกันจึงยังไม่ได้สื่อความหมายของคำคำนั้นอย่างที่เราต้องการ ขั้นตอนต่อไปหลังจากสร้างเวกเตอร์ตัวแทนของคำจึงเป็นการแปลงเวกเตอร์นั้นให้สามารถใช้งานเป็นตัวแทน ความหมาย ของคำคำนั้นแทน ทั้งนี้ส่วนมากแล้วเวกเตอร์ที่ใช้แทนความหมายของคำนั้นจะมีจำนวนมิติลดลงมาก (คำที่เป็นเอกลักษณ์ในข้อความทั้งหมดที่นำมาพิจารณามักจะมีอยู่เป็นจำนวนมาก word vector เหล่านี้จึงมักจะมีจำนวนมิติสูง)
เทคนิคในตระกูล Word2Vec
เทคนิคประเภทหนึ่งในการสร้างเวกเตอร์ความหมายของคำคือเทคนิคในตระกูล Word2Vec ซึ่งมีแนวคิดหลักว่า
ความหมายของคำคำหนึ่งในประโยคนั้นมีความสัมพันธ์กับความหมายของคำที่อยู่รอบข้าง
โดยตัวอย่างแนวคิดที่เกิดขึ้นจากแนวคิดหลักนี้ ได้แก่ (1) ความหมายของคำคำหนึ่งนั้นอาจสามารถถูกทำนายได้จากบริบทของคำที่อยู่รอบข้าง และ (2) คำที่อยู่รอบข้างของคำคำหนึ่งก็อาจสามารถถูกทำนายได้จากคำคำนั้นเช่นกัน แนวคิดทั้งสองอย่างนี้ ได้ถูกนำไปพัฒนาเป็นโมเดล ชื่อ Continuous Bag of Words (CBOW) และ Skip-gram ตามลำดับ โดยทั้งสองโมเดลนี้ได้ถูกนำไปใช้งานอย่างแพร่หลาย
โมเดล Continuous Bag of Words (CBOW)
ในการใช้งานโมเดล CBOW นั้น ผู้ใช้จะทำการสร้างเครื่องข่ายสมองแบบตื้น (shallow neural network) โดยจะใช้งาน word vector เป็น input layer ซึ่งเชื่อมต่อเข้ากับ hidden layer จำนวน 1 ชั้น (เราสามารถกำหนดจำนวน node ใน layer นี้ได้ตามต้องการ แต่โดยปกติจะมีจำนวนน้อยกว่าจำนวนมิติของเวกเตอร์ที่เป็น input ซึ่งก็คือเวกเตอร์ตัวแทนของคำหรือ word vector นั่นเอง) และทำการต่อเข้าสู่ output layer ที่มีจำนวนมิติเท่ากับ Input layer จากนั้นจึงทำการฝึกฝนโมเดล (training) ในรูปแบบของการทำ classification
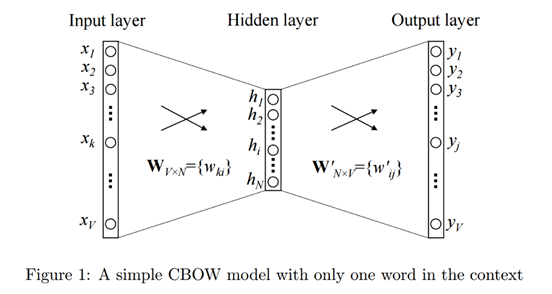
(ในรูปใช้คำเพียงคำเดียวเป็นบริบท) (ที่มารูปภาพ)
กล่าวคือสำหรับแต่ละคำในประโยคหรือข้อความที่จะวิเคราะห์นั้น ในขั้นตอนของการฝึกฝนโมเดลจะนำเอา word vectors ของคำที่อยู่รอบๆ คำดังกล่าวภายในระยะของบริบท (context size) ที่กำหนดมาใช้เป็น input ในการทำ classification และใช้ word vector ของคำที่กำลังพิจารณาซึ่งมีตำแหน่งอยู่ที่ตรงกลาง (center word) ของบริบทเป็นเป้าหมายในการทำนาย (output)

| (สำหรับผู้สนใจที่มีความรู้พื้นฐานเกี่ยวกับการทำงานของ neural network ) ภายในโมเดลนี้ เมื่อพิจารณาคำแต่ละคำในข้อความ ตัว word vectors ของคำรอบข้างภายในระยะที่เรากำหนดไว้ว่าให้เป็นบริบทของคำคำหนึ่ง จะถูกนำมาใช้เป็น input ในการคำนวณ เช่น สมมุติว่า vocabulary ของเรามีคำที่แตกต่างกันทั้งหมด V คำ และเรากำหนดว่าเราจะใช้งานคำรอบๆ ทั้งสองฝั่งของคำที่พิจารณารวมเป็นจำนวน C คำ เราจะมี word vector (ของคำที่เป็นบริบท) จำนวน C เวกเตอร์ ที่มีขนาด V มิติ มาเป็น input (ดังที่แสดงใน input ของรูปที่ 2) โดยเวกเตอร์เหล่านี้จะถูกนำมาคำนวณผ่าน hidden layer เพื่อหา “embedded vectors” ของแต่ละคำบริบท ซึ่งผลลัพธ์จะอยู่ในรูปของเวกเตอร์ที่มีขนาดเท่ากับจำนวน node ของ hidden layer (กรณีนี้กำหนดให้เป็น N มิติ) จากนั้น embedded vectors ของคำบริบทเหล่านี้ทุกคำจะถูกนำมาเฉลี่ยเพื่อนำไปคำนวณ “score vector” ผลลัพธ์ที่ได้ใน output layer จึงเป็นเวกเตอร์ที่มีขนาด V มิติเท่ากับ input ซึ่งจะถูกนำไปผ่านฟังก์ชัน Softmax เพื่อทำนายความน่าจะเป็น (probability) ของ word vectors ต่างๆ ที่จะเป็น output ของโมเดลนี้ ผลลัพธ์การจากการทำนายนี้จะถูกนำไปเปรียบเทียบกับเป้าหมายที่ต้องการเพื่อช่วยเหลือโมเดลในการปรับแก้น้ำหนัก (weights) ต่างๆ ที่ใช้กับตัวแปรของสมการภายใน neural network นี้เพื่อปรับผลลัพธ์ที่ได้ให้แม่นยำมากขึ้น เช่นเดียวกับการ train โมเดลของ neural network ตามปกติ |
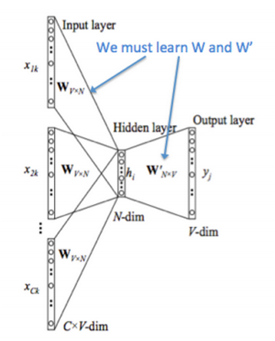
โมเดล Skip-gram
สำหรับการฝึกฝนด้วยโมเดล Skip-gram นั้น เราจะทำการสร้าง shallow neural network ในลักษณะเดียวกับที่ใช้งานในโมเดล Continuous Bag of Words (CBOW) โดยมีขนาด input layer และ output layer เท่ากัน และมี hidden layer เป็นจำนวน 1 ชั้น เช่นเดียวกับที่แสดงในรูปที่ 1 แต่การฝึกฝนโมเดล Skip-gram นั้นจะต่างจากการโมเดล CBOW เพราะแทนที่จะใช้ word vectors ของคำต่างๆ ในบริบทของคำแต่ละคำมาเพื่อทำนายคำดังกล่าว โมเดล Skip-gram เลือกที่จะใช้คำหนึ่งๆ ในการทำนายคำทุกคำที่อยู่ในบริบทของคำนั้นแทน
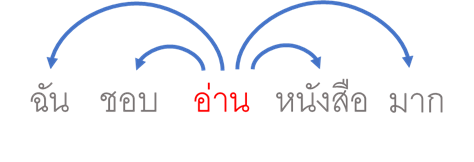
กล่าวคือสำหรับแต่ละคำในประโยคหรือข้อความที่นำมาพิจารณานั้น การฝึกฝนโมเดลนี้จะนำเอา word vectors ของคำนั้นมาใช้เป็นคำกลาง (center word) และทำนายการกระจายตัว (probability distribution) ของคำที่น่าจะเป็นบริบทของคำคำนี้
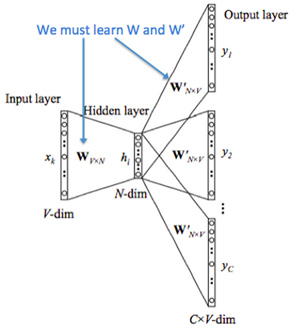
(ที่มารูปภาพ)
| (สำหรับผู้สนใจที่มีความรู้พื้นฐานเกี่ยวกับการทำงานของ neural network ) ในทำนองเดียวกันกับโมเดล CBOW ที่กล่าวไปข้างต้น สำหรับโมเดล Skip-gram นี้ word vector ของคำแต่ละคำ (เวกเตอร์ขนาด V มิติในรูปที่ 3 ด้านบน) จะถูกนำมาใช้เป็น input เพื่อนำมาคำนวณหา embedded vector (เวกเตอร์ขนาด N มิติ) โดยตัวเวกเตอร์นี้จะถูกนำไปสร้างเป็น score vector เพื่อใช้ทำนาย output โดยอยู่ในรูปของความน่าจะเป็น (probability) ของคำต่างๆ ที่เป็นไปได้ว่าจะปรากฏเป็นคำบริบทภายในระยะที่กำหนด (แสดงด้วยเวกเตอร์จำนวน C เวกเตอร์ ที่มีขนาด V มิติตามแสดงในรูป) การสร้าง score vector สามารถคำนวณได้โดยใช้ฟังก์ชัน SoftMax เช่นเดียวกันกับโมเดล CBOW โดยผลลัพธ์จากการทำนายจะถูกนำไปเปรียบเทียบกับกับคำที่ปรากฏเป็นบริบทของ input จริง และโมเดลจะทำการปรับแก้น้ำหนัก (weights) ต่างๆ ที่ใช้กับตัวแปรภายในให้เหมาะสมขึ้นต่อไป |
ถึงจุดนี้แล้วบางคนอาจจะสงสัยว่าการที่เรา train โมเดลทั้งสองตัวนี้ขึ้นมานั้น มันเกี่ยวข้องอะไรกับการหาตัวแทนเชิงความหมายของคำต่างๆ กันแน่?
ถ้าหากใครช่างสังเกตนิดนึง จะเห็นว่า ในขั้นตอนการฝึกฝนโมเดลนั้น จะมีเวกเตอร์ที่คำนวณจากค่าภายในโมเดลอยู่ตัวหนึ่งที่ชื่อว่า “embedded vector” เวกเตอร์ตัวนี้แหละครับ คือสิ่งที่เราจะนำมาใช้เพื่อเป็นตัวแทนของข้อความ โดยจะสามารถนำไปประยุกต์ใช้งานต่างๆที่ได้กล่าวไว้ตอนต้นเช่นการตรวจสอบความคล้ายคลึงของข้อความหรือการทำ classification ได้เหมือนเป็นข้อมูลเชิงปริมาณเลยครับ
ในบทความต่อไปเราจะมาดูวิธีการประยุกต์ใช้และตัวอย่างการนำผลลัพธ์ที่ได้จากการฝึกฝน neural network ทั้งสองโมเดลนี้มาใช้ โดยละเอียด และทำการเขียนโปรแกรมอย่างง่ายๆเพื่อลองใช้งาน word embedding กันดูครับ
ข้อมูลที่เกี่ยวข้องและข้อมูลเพิ่มเติม
- เอกสารประกอบการเรียนวิชา CS224n:Natural Language Processing with Deep Learning มหาวิทยาลัย Stanford
- Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
- Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” arXiv preprint arXiv:1310.4546 (2013).
เนื้อหาโดย ปฏิภาณ ประเสริฐสม
ตรวจทานและปรับปรุงโดย พีรดล สามะศิริ




Acting Assistant Vice President - Data Analytics Services Division (DAS),
Big Data Institute (BDI)




