ในปัจจุบันการตรวจจับวัตถุด้วยรูปภาพ (Image Detection) เป็นเทคโนโลยีที่ใช้คอมพิวเตอร์ในการระบุและวิเคราะห์วัตถุที่อยู่ในรูปภาพ ซึ่งการใช้งานนั้นสามารถประยุกต์ใช้ในหลายรูปแบบ ตัวอย่างเช่น การระบุใบหน้าในภาพถ่ายที่เวลาพนักงานต้องเข้าตึกหรือที่เห็นตามหนัง การระบุสินค้าในคลังสินค้า รวมไปถึงในปัจจุบันที่รถยนต์สามารถขับแบบอัตโนมัติได้ก็จะมีการนำเทคโนโลยีนี้มาใช้งานด้วยเช่นกัน ดังนั้นในบทความนี้เราจะมาอธิบายถึงภาพรวมเพื่อให้เห็นภาพว่ามันคืออะไรครับ
ประเภทของการตรวจจับวัตถุด้วยรูปภาพ
ก่อนอื่นเลย คนที่เข้ามาใหม่หรือยังไม่คุ้นชินกับเรื่องรูปเท่าไหร่ อาจจะมีคำถามว่าเราทำ Image Detection ไปทำไม แล้วมีตัวอย่างให้เห็นภาพชัด ๆ ไหม
การตรวจจับวัตถุสามารถแบ่งออกเป็นสามประเภทหลักๆขึ้นอยู่กับเป้าหมายในการใช้งานโดยจะมี
- Image Classification เป็นการใช้ AI ให้มันบอกเราว่ารูปที่มีมันคือรูปของอะไร เช่น รูปตัวอย่างดังต่อไปนี้

แน่นอนว่าทุกคนรู้ว่ามันคือ แมว แต่สำหรับ AI นั้น เราต้องส่งรูปเข้าไปพร้อมกับผลลัพธ์ว่า นี่คือรูปแมวนะ เพื่อให้มันเรียนรู้เรื่อย ๆ และนี่คืองานหลักของสิ่งที่เรียกว่า Image Classification
- ต่อมาถ้าเราต้องการรู้เพิ่มเติมว่า แล้วแมวมันอยู่ตรงไหนของรูปหล่ะ ? ถ้าได้โจทย์มาเป็นแบบนี้ จะเป็นโจทย์อีกแนวที่เรียกว่า Image Detection โดยมันจะบอกถึงตำแหน่งของรูปด้วย เช่น

จากรูป เราจะทราบเลยว่าน้องหมาอยู่ตรงไหนของรูป รวมถึงน้องแมว และน้องเป็ด ทำให้เราได้ insight เพิ่มเติมจากผลลัพธ์ (ซึ่งจะเป็นงานหลักของเราในบทความนี้) จากงานแนวนี้นั้นจะเพิ่มเติมจาก Image Classification ตรงที่เราต้องบอก AI ไปด้วยว่า แมวอยู่พิกัดตรงนี้ในรูปนะ
- และอีกโจทย์คือ ในบางครั้งเราอยากจะแค่เอาเฉพาะส่วนของรูปที่สำคัญ ในโจทย์นี้จะเป็น Image Segmentation ดังรูปด้านล่างครับ

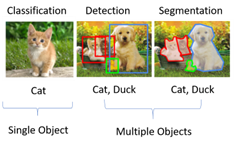
สำหรับบทความนี้เราจะโฟกัสไปที่ Image Detection (ภาพกลาง) เพื่อที่จะดูว่าตำแหน่งของรูปนั้นอยู่ตรงไหนครับ
การนำ Image Detection ไปใช้ประโยชน์
การนำ Image Detection ไปใช้ประโยชน์ จะขึ้นอยู่กับโจทย์ (Scope) เลยครับ ตัวอย่างเช่น
- Medical Sector
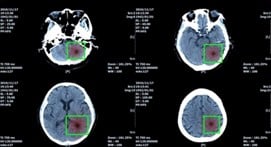
บางครั้งเวลาที่มีรูป X-ray ออกมา ในการตรวจเช็ครูปนั้นจะต้องใช้หมอเฉพาะทางที่มีจำกัด ถ้าเรามี AI คอยช่วย Focus หรือตีกรอบส่วนที่มีปัญหา จะลดเวลาในส่วนนี้มาก รวมถึงอาจจะใช้งานร่วมกับ Image Segmentation ได้ จากรูปด้านล่าง เขาวิเคราะห์เรื่องตำแหน่งของเนื้องอกในสมองครับ
- Traffic Sector
อีกตัวอย่าง เวลาที่เราขับรถบนท้องถนน ก็จะมีกล้องที่คอยเช็คความเร็วหรืออาจจะตรวจสอบว่ารถติดไหม เราสามารถนำ AI นี้ไปช่วยได้ว่ามีรถบนถนนเยอะหรือไม่แล้วไปเชื่อมกับระบบอื่นครับ (รวมไปถึงรถกำลังจะเข้าเส้นทึบไหม)

YOLOv5 คืออะไร
หลังจากที่เราเห็นภาพรวมในของ Image Detection แล้ว เชื่อว่าหลายท่านคงเริ่มอยากจะลองหัดทำและสร้างระบบขึ้นมา เราจะมาเข้าหัวข้อหลักของเราคือ YOLOv5 และแน่นอนว่า YOLO ในที่นี้ไม่ได้แปลว่า ‘You only live once’ แต่มันคือ ‘You only look once’ ซึ่งจะเป็นหลักการทำงานของมัน และในปัจจุบันมีถึง Version 8 แล้วด้วยกัน (As of Nov 2023) แต่ต้องบอกว่า YOLOv5 คือเวอร์ชั่นที่ยังคงได้รับความนิยมอย่างมากจาก Github Page ที่ยังมีการอัพเดทเรื่อยๆ โดยตัว YOLO นี้มันคือสถาปัตยกรรมที่ทาง ultralytics ได้ออกแบบไว้เพื่อทำ Image Detection ได้อย่างรวดเร็วและมีประสิทธิภาพ
แน่นอนว่าการทำ Image Detection นั้นมีหลายวิธี ไม่น่าจะเป็น R-CNN, Faster R-CNN, EfficientDet แต่ข้อดีของ YOLO คือจะมีจุดเด่นที่ความไวในการวิเคราะห์ข้อมูล ทำให้เราเลือกใช้ตัว YOLO นี้และมี Document ที่พร้อม รวมถึง Customized ให้เข้าได้ข้อมูลและเป้าหมายของเราได้
อย่างไรก็ตาม หลายคนที่เคยเล่นเรื่องรูปภาพมาอาจจะสงสัยว่า Image Detection ก็มีวิธีคลาสสิก เช่น Keypoint Detector ได้ แต่พวกวิธี SIFT มันจะมีประเด็นเรื่องของความเร็วครับ
โดยสำหรับ YOLO นี้ข้อดีคือมันเร็วอย่างที่บอกไป เนื่องจากมันจะวิเคราะห์จากรูปครั้งเดียว แล้วทำ Label ให้ครอบคลุมทั้งรูป
หลักการทำงานของมันคือจากรูป 1 รูปเต็มๆ มันจะทำการแบ่ง Grid cell ออกมาเป็น n x n grid (จากรูปน้องหมา แบ่งไป 13 grid ยิ่งแบ่งมากก็จะละเอียด trade off กับการคำนวณ)

แล้วในแต่ละ grid (เช่นบนซ้ายสุด) เราก็ต้องใส่ Label ให้มัน(ถ้ามี) เช่น
[Pc, bx, by, bh, bw, c1, c2 ,… , cn]
โดยที่ Pc คือ Probability ที่มีวัตถุอยู่ใน Grid นั้นๆ ถ้าไม่มีคือ 0 ถ้ามีคือ 1
bx, by คือตำแหน่งตรงกลางของ Object ว่าอยู่พิกัดไหน
bh, bw คือขนาดความสูงและกว้างของ Object ว่าสูง, กว้างขนาดไหน
และ c1, c2, .., cn คือ ผลลัพธ์ว่าเป็น class อะไร ถ้าโจทย์เรามีแค่ detect น้องหมา ก็จะมี class เดียว และ grid นั้นมีค่าเป็น 1 แต่ถ้ามีหลาย Object ก็จะมีเลขต่อๆไป
(เช่น Grid ตรงกลางของน้องหมา จะมี C1 = 1 โดย Grid อื่น C1 = 0)
แต่ถ้าในกรณี 1 grid มีหลาย Object ละ? ทำยังไง

จาก Label ด้านบน มันจะรับได้เฉพาะ 1 grid คือ 1 Object แต่กรณีถ้ามีหลาย Object เราจะใช้หลักการที่เรียกว่า Anchor Box โดยเราสามารถกำหนดจำนวน Box นี้ได้ (เช่น 2) ก็จะมี Label แบบด้านบน 2 อันใน 1 Gridได้ (เราสามารถกำหนดเลขนี้ได้) และตัว YOLO ก็จะคำนวณให้ว่ารูปนั้นมันใกล้ Anchor ไหนสุดจากค่า IOU ก็จะถูกกำหนดไปที่ Anchor นั้น
แต่สำหรับคนที่เริ่ม YOLO นั้น อาจจะไม่ต้องสนใจส่วนนี้ก็ได้ ตัว YOLO มันจะคำนวณมาให้เลย เราสามารถทำแค่บอกว่ามีตำแหน่ง Object อะไรในรูปพอครับ
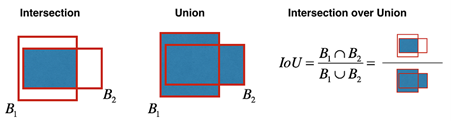
IOU & NMS
อีก Keyword ที่สำคัญคือ Intersection over Union (IOU) และ Non-max suppression (NMS) ที่ควรรู้ครับ
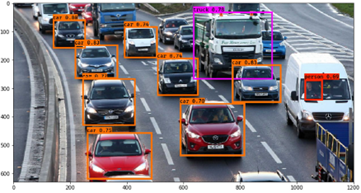
IOU จะมามีส่วนหลักๆหลายส่วนใน YOLO เช่นเวลาโมเดลทำนายออกมา มันอาจจะทำนายรูปรถเดียวกันแต่หลายกล่องได้ เช่น

เราจึงต้องใช้ metric IOU ในเลือกกล่องเดียวเป็นตัวแทนของ Object นั้นๆครับ จากวิธีการ NMS โดยหลักการคำนวณคือ หาส่วนที่ Intersect หารส่วนที่ Union กัน ถ้ากล่องใดมีค่านี้สูง (เกิน Threshold ที่กำหนด) แสดงว่ามันคือ Object เดียวกันครับ
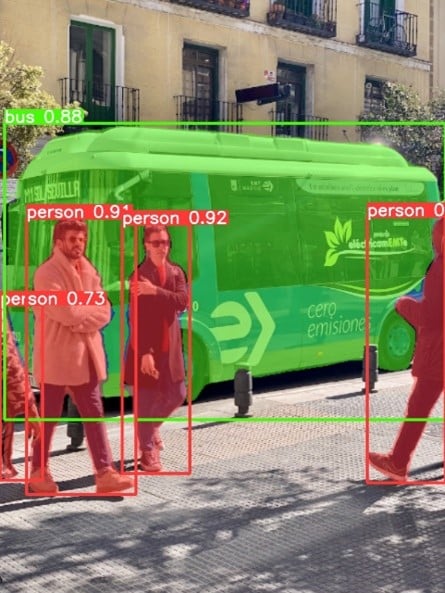
และสุดท้ายแล้ว ผลลัพธ์ของ YOLO มันก็จะบอกได้ว่า Object ในรูปมีอะไรบ้างเพื่อนำไปใช้งานต่อไปครับ
สำหรับ detail หรือคำอธิบายที่ละเอียดกว่านี้ สามารถดูได้ผ่านลิงค์นี้ ได้เลยครับ ขอบคุณครับ
เนื้อหาโดย อินทัช คุณากรธรรม
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์

Data scientist at Krungsri Consumer








