
บทความนี้ถูกคุ้มครองด้วย Creative Commons License
เนื้อหาส่วนมากของบทความนี้ได้รับการแปล สังเคราะห์ และเรียบเรียงจากหนังสือ Interpretable Machine Learning โดย Christoph Molnar
Most content in this article is translated, compiled, and summarized from the Interpretable Machine Learning by Christoph Molnar
ในบทความที่แล้ว เราได้พูดถึงหลักการของการคำนวน Shapley value ซึ่งสามารถใช้วิเคราะห์ผลกระทบจากฟีเจอร์ของโมเดลต่าง ๆ ได้โดยไม่ต้องทราบถึงรายละเอียดภายในของโมเดล สำหรับบทความนี้ เราจะมาพูดถึงตัวอย่างการใช้งาน Shapley ในการตีความโมเดลพร้อมกับ จุดเด่นและข้อด้อยของเทคนิคนี้กันครับ
การตีความ
เราอาจกล่าวได้ว่า Shapley value คือ ขนาดของผลกระทบ ϕj ที่ค่าของฟีเจอร์ตัวที่ j ส่งผลให้การทำนายของจุดข้อมูลที่พิจารณาต่างจากค่าเฉลี่ยของทั้งชุดข้อมูล กล่าวคือ ถ้าสมมติว่าโมเดลที่เราใช้ทำนายเป็นโมเดลเชิงเส้นที่มีสมการในรูป
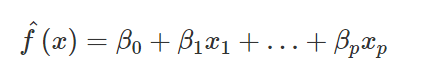
ค่าผลกระทบของ ϕj ที่ค่าของฟีเจอร์ตัวที่ j จะถูกเขียนได้เป็น
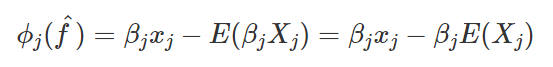
ซึ่งคือผลต่างของส่วนค่าทำนายที่ได้จากฟีเจอร์นั้น (ค่าฟีเจอร์นั้นคูณด้วยน้ำหนัก) กับค่าเฉลี่ยของส่วนค่าทำนายที่ได้จากฟีเจอร์นั้นครับ นอกจากนี้ถ้าหากนำค่าผลกระทบจากทุกฟีเจอร์มารวมกัน จะได้ว่ามีค่าเท่ากับผลต่างของค่าทำนายจุดนั้นกับค่าเฉลี่ยการทำนายของโมเดลพอดี ดังสมการ
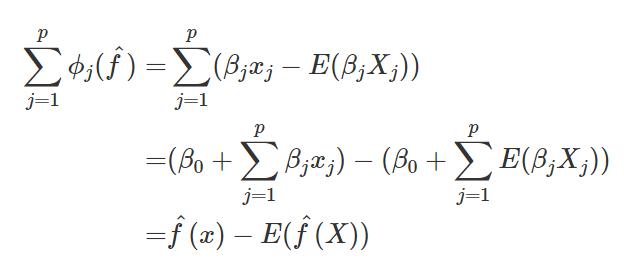
ตัวอย่างการใช้งาน
Shapley value สามารถใช้วิเคราะห์ได้ทั้งโจทย์ประเภท classification (ถ้าหากเราพิจารณาโมเดลที่ใช้งาน probability ในการ classify) และโจทย์ประเภท regression
โจทย์ประเภท classification
รูปด้านล่างเป็นตัวอย่างการใช้งาน Shapley value เพื่อวิเคราะห์ผลการทำนาย โรคมะเร็งปากมดลูกจากชุดข้อมูล cervical cancer ด้วยโมเดล random forest
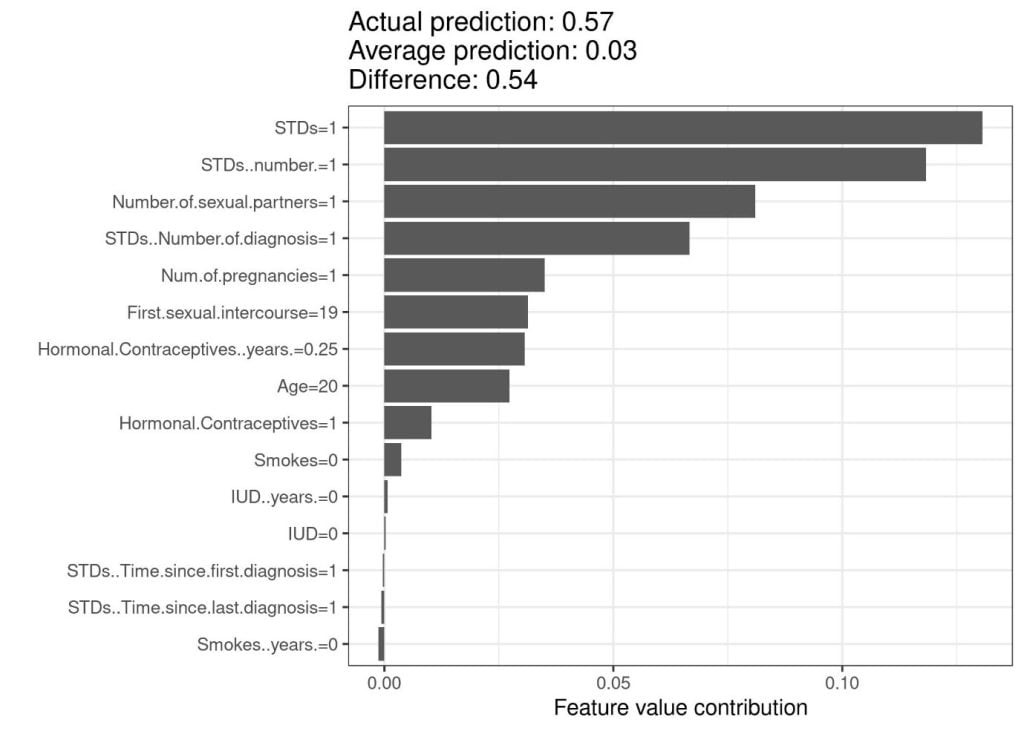
ภาพด้านบนแสดง Shapley value อิงจากค่าฟีเจอร์ของผู้หญิงคนหนึ่ง จากชุดข้อมูลมะเร็งปากมดลูก (cervical cancer dataset) ซึ่งโมเดลทำนายความน่าจะเป็นของการเป็นมะเร็งปากมดลูกอยู่ที่ 0.57 สูงกว่าความน่าจะเป็นเฉลี่ยจากข้อมูลทั้งชุดที่ 0.03 คิดเป็นผลต่างความน่าจะเป็น 0.54 โดยจากการวิเคราะห์พบว่าค่าฟีเจอร์ว่าด้วยการมีโรคติดต่อทางเพศสัมพันธ์ (STDs) ส่งผลต่อการเพิ่มขึ้นของค่าความน่าจะเป็นมากที่สุด จากภาพจะเห็นว่าผลรวมของค่าผลกระทบขตัวอย่างการใช้งานกับโจทย์ประเภท classificationองทุกค่าฟีเจอร์มีค่าเท่ากับผลต่างระหว่างค่าทำนายกับค่าทำนายเฉลี่ยจากข้อมูลทั้งชุด (0.54).
โจทย์ประเภท regression
สำหรับตัวอย่างโจทย์ประเภท regression นี้ เราอาจพิจารณาโมเดล random forest เพื่อทำนายจำนวนของจักรยานที่ถูกเช่าในหนึ่งวัน (ชุดข้อมูล bike rental dataset) ซึ่งพิจารณาข้อมูลอากาศและวันที่ประกอบการทำนาย รูปด้านล่างแสดงคำอธิบายผลกระทบของฟีเจอร์ต่างๆ ของโมเดลที่พัฒนาขึ้น
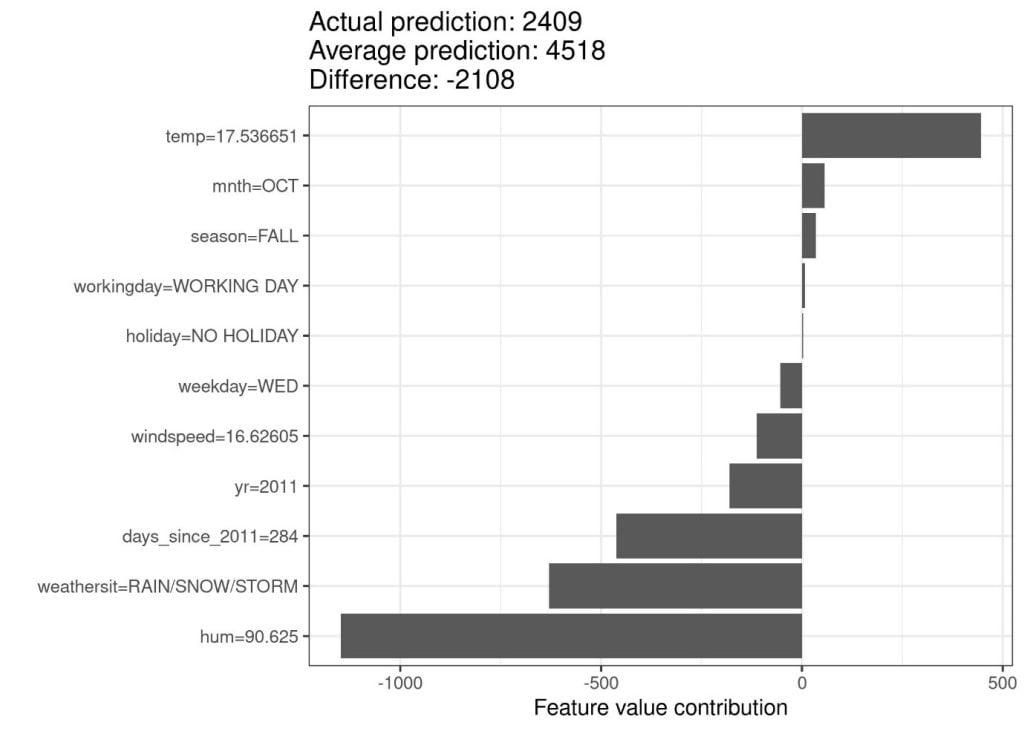
ภาพด้านบนแสดง Shapley value ของวันที่ 285 ซึ่งให้ทำนายว่ารถจักรยาน 2,409 คันจะถูกเช่า คิดเป็นจำนวนน้อยกว่าค่าเฉลี่ย (4,518 คัน) อยู่ 2,108 คัน โดยจะเห็นได้ว่าสภาพอากาศที่มีฝน, หิมะ, พายุ และความชื้นในอากาศ มีผลกระทบในเชิงลบมากที่สุด ในขณะที่อุณหภูมิเป็นผลกระทบเชิงบวกกับจำนวนรถจักรยานที่ถูกเช่า ผลรวมของ Shapley value ของทุกฟีเจอร์จะเท่ากับผลต่างระหว่างค่าทำนายกับค่าเฉลี่ยของการทำนาย (-2,108) เช่นเดียวกรณีอื่นที่ใช้ Shapley value ในการอธิบายโมเดล
| หมายเหตุ ในการนำ Shapley value ไปใช้นั้น ผู้ใช้จะต้องเข้าใจความหมายและตีความผลลัพธ์ได้อย่างถูกต้อง ข้อสำคัญคือ Shapley value สะท้อนผลกระทบเฉลี่ยของค่าฟีเจอร์หนึ่งผ่านการพิจารณาฟีเจอร์ดังกล่าวในหลายสถานการณ์ (กลุ่มย่อยของค่าฟีเจอร์) ไม่ใช่ความต่างของผลการทำนายที่จะเกิดขึ้นเมื่อนำฟีเจอร์ดังกล่าวออกจากโมเดล |
จุดเด่นของการใช้งาน Shapley value
- Shapley value (ผลกระทบ) จากแต่ละฟีเจอร์ของข้อมูลจุดหนึ่ง เมื่อนำมารวมกันทั้งหมดแล้วจะได้ผลต่างระหว่างค่าทำนายที่จุดนั้นกับค่าทำนายเฉลี่ยของทั้งชุดข้อมูล ทำให้สามารถอธิบายผลกระทบของฟีเจอร์ทั้งหมดกับค่าทำนายสุดท้ายได้อย่างครบถ้วนสมบูรณ์
- วิธีคำนวณ Shapley value นอกจากจะใช้เพื่อประเมินผลกระทบของค่าทำนายกับค่าทำนายเฉลี่ยของทั้งชุดข้อมูล ยังสามารถปรับใช้เพื่อเปรียบเทียบค่าทำนายกับค่าทำนายเฉลี่ยในบางส่วน (subset) ของชุดข้อมูล หรือแม้กระทั่งกับข้อมูลอีกจุดหนึ่งได้
- Shapley value เป็นวิธีการอธิบายโมเดลที่มีทฤษฎีและสมบัติทางคณิตศาสตร์รองรับ และสามารถอธิบายที่มาของผลการวิเคราะห์ได้อย่างชัดเจน ในขณะที่เทคนิคอื่นเช่นเทคนิค LIME ซึ่งใช้สมมติฐานว่าพฤติกรรมของโมเดลในพื้นที่ขนาดเล็กนั้นมีลักษณะเป็นเส้นตรงนั้นไม่ได้มีพื้นฐานทางทฤษฎีมาช่วยสนับสนุน
ข้อจำกัดของการใช้งาน Shapley value
- การคำนวณ Shapley value นั้นจำเป็นต้องใช้เวลานาน (เนื่องจาก ถ้าหากมีฟีเจอร์ทั้งหมด k ฟีเจอร์ จะมีกลุ่มฟีเจอร์ที่ต้องพิจารณาถึง 2k กลุ่ม ส่งผลให้ในส่วนมาก ในการใช้งานจริงจึงใช้เพียงค่าประมาณ Shapley value เท่านั้น
- การคำนวณ Shapley value จำเป็นต้องใช้ทุกฟีเจอร์ จึงไม่เหมาะกับการอธิบายโมเดลด้วยบางฟีเจอร์ของโมเดล ในกรณีที่ต้องการใช้ฟีเจอร์เพียงบางส่วนมาเพื่ออธิบาย เทคนิคเช่น LIME หรือ SHAP (เทคนิคการคำนวณที่ต่อยอดจากการคำนวณ Shapley value) นั้นอาจเป็นทางเลือกที่เหมาะกว่า
- Shapley value ไม่ใช่โมเดลการทำนาย แต่เป็นตัวเลขที่ถูกใช้เพื่ออธิบายผลกระทบของแต่ละฟีเจอร์ ซึ่งไม่สามารถใช้เพื่อประเมินผลกระทบในกรณีที่ค่าฟีเจอร์เปลี่ยนแปลงไป เช่น หากเราวิเคราะห์โมเดลทำนาย credit score จากหลากหลายปัจจัย เราจะไม่สามารถประเมินได้ว่า ถ้าหากได้เงินเดือนเพิ่ม €300 แล้ว ค่า credit score จะสูงขึ้นเท่าใด
- การคำนวณ Shapley value ไม่สามารถทำได้จากตัวโมเดลเพียงอย่างเดียว แต่จะต้องสามารถเข้าถึงข้อมูลจริง หรือข้อมูลเสมือนที่มีคุณสมบัติของข้อมูลจริงได้
อย่างไรก็ดี เพื่อให้การคำนวณ Shapley value มีประสิทธิภาพ และสอดคล้องกับการนำมาใช้งานจริง เทคนิค SHAP (SHapley Additive exPlanations) ได้ถูกพัฒนาขึ้นเพื่อให้สามารถทำการคำนวณ Shapley value ได้อย่างรวดเร็วพร้อมทั้งช่วยแก้ไขข้อจำกัดของการคำนวณ Shapley value ในบางส่วน ผู้อ่านที่สนใจสามารถทดลองใช้งานได้ผ่าน ไลบรารีของ Python ได้ นอกจากการคำนวณ Shapley value แล้วนั้น ไลบรารีตัวนี้ยังมีคำสั่งอื่นๆ เพื่อช่วยให้ผู้ใช้สามารถตีความค่า SHAP ได้อย่างสะดวกขึ้นอีกด้วย ทั้งนี้ ในบทความนี้เราจะไม่ได้พูดถึงหลักการทำงานของเทคนิค SHAP เนื่องจากการที่จะเข้าใจการทำงานดังกล่าว ผู้อ่านจำเป็นต้องเข้าใจรายละเอียดเชิงคณิตศาสตร์ของการคำนวณ Shapley value เป็นอย่างดี จึงขอยกไว้พูดอธิบายหากมีโอกาสในอนาคตครับ
ข้อมูลที่เกี่ยวข้องและข้อมูลเพิ่มเติม
- Interpretable Machine Learning โดย Christoph Molnar Chapter 9.5: Shapley Values
- Lundberg, Scott M., and Su-In Lee. “A unified approach to interpreting model predictions.” Advances in Neural Information Processing Systems (2017).
แปล สังเคราะห์ และ เรียบเรียง โดยปฏิภาณ ประเสริฐสม
ตรวจทานและปรับปรุงโดย พีรดล สามะศิริ




Acting Assistant Vice President - Data Analytics Services Division (DAS),
Big Data Institute (BDI)





