
บทความนี้ถูกคุ้มครองด้วย Creative Commons License
เนื้อหาส่วนมากของบทความนี้ได้รับการแปล สังเคราะห์ และเรียบเรียงจากหนังสือ Interpretable Machine Learning โดย Christoph Molnar
Most content in this article is translated, compiled, and summarized from the Interpretable Machine Learning by Christoph Molnar
ในบทความก่อนหน้า เราได้กล่าวถึงเทคนิค LIME ซึ่งเป็นหนึ่งในวิธีวิเคราะห์ผลกระทบของฟีเจอร์ต่างๆ กับคำทำนายของโมเดลทุกประเภท โดยอาศัยการใช้งานโมเดลตัวแทน (surrogate model) เพื่อศึกษาพฤติกรรมของโมเดลที่สนใจวิเคราะห์ในบริเวณใกล้เคียงของจุดข้อมูล (data point) ที่ต้องการพิจารณา สำหรับบทความนี้เราจะมาพูดถึงอีกเทคนิคหนึ่งที่สามารถเลือกใช้เพื่อวิเคราะห์ผลกระทบของฟีเจอร์ได้ในทำนองเดียวกัน นั่นคือการคำนวณ Shapley value
Shapley value
Shapley value เป็นการคำนวณภายใต้หลักทฤษฎีเกม (game theory) ในรูปแบบทฤษฎีเกมแบบร่วมมือ (coalitional game theory) โดยในหลักการดังกล่าว เราจะมองค่าของฟีเจอร์แต่ละตัวเป็น “ผู้เล่น” (player) ของเกม และผลจากการทำนายของโมเดลเป็น “ผลลัพธ์” (payout) ของเกม Shapley value เป็นค่าที่ระบุว่าควรจะแบ่งผลลัพธ์ของเกมให้แก่ผู้เล่นแต่ละคนอย่างไรให้ยุติธรรมโดยอ้างอิงจากสัดส่วนการมีส่วนร่วม (contribution) ของผู้เล่นแต่ละคน เมื่อนำหลักการดังกล่าวมาใช้กับการวิเคราะห์โมเดล ค่านี้จึงสามารถใช้เพื่อบอกว่าแต่ละฟีเจอร์จะส่งผลกระทบต่อการทำนายของโมเดลมากน้อยอย่างไร
หลักการทำงาน ของ Shapley value
ท่านผู้อ่านลองพิจารณาสถานการณ์ต่อไปนี้ดูครับ
สมมุติว่าท่านได้ฝึกโมเดล machine learning เพื่อทำนายราคาห้องพักของคอนโด เมื่อใช้โมเดลดังกล่าว ทำนายราคาห้องขนาดพื้นที่ 50 m2 อยู่ชั้น 2 มีสวนอยู่ใกล้เคียง พบว่ามีราคาทำนายอยู่ที่ €300,000 (3 แสนยูโร หรือ ประมาณ 11.5 ล้านบาท) และท่านต้องการทราบว่าแต่ละฟีเจอร์ส่งผลอย่างไรต่อการทำนายดังกล่าวนี้:
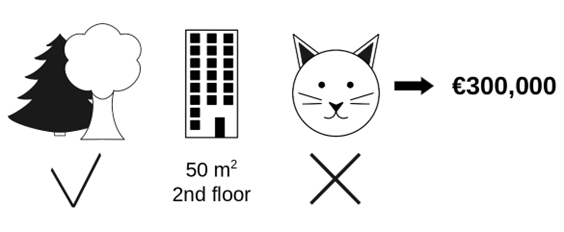
หากโมเดลที่ท่านเลือกใช้เป็นโมเดลประเภท linear regression ผลกระทบของแต่ละฟีเจอร์ต่อการทำนายสามารถถูกตีความได้จากผลคูณของสัมประสิทธิ์ (weight) กับค่าของแต่ละฟีเจอร์ อย่างไรก็ดีกรณีของโมเดลที่มีความซับซ้อน เราจำเป็นต้องหาเทคนิคอื่นเพื่อตอบคำถามดังกล่าว ซึ่งอาจเป็นเทคนิค LIME ที่เคยได้พูดถึงไปในบทความก่อนหน้า
ในอีกเทคนิคหนึ่ง เราอาจใช้ Shapley value ที่จะกล่าวถึงในรายละเอียด โดยการประยุกต์ใช้ Shapley value เพื่อหาผลกระทบของฟีเจอร์ จะมองว่า
- “เกม” (game) เกมหนึ่ง คือ การทำนายค่าของข้อมูลรายการหนึ่ง
- “ผลประโยชน์” (gain) คือ ผลต่างระหว่างผลการทำนายจริงจากโมเดล กับค่าเฉลี่ยของการทำนายจากข้อมูลทุกรายการที่มี
- “ผู้เล่น” (players) แต่ละคนในเกม คือ ค่าของฟีเจอร์แต่ละประเภทที่ทำงานร่วมกันให้ได้ผลประโยชน์ที่โมเดลทำนายให้มา
จากสถานการณ์ตัวอย่าง ค่าฟีเจอร์ของการมีพื้นที่ 50 m2 การที่อยู่ชั้น 2 การมีสวนอยู่ใกล้ และการห้ามเลี้ยงสัตว์ เป็นฟีเจอร์ที่ส่งผลกระทบร่วมกันที่ทำให้ค่า 300,000 ยูโร ถูกทำนายขึ้นมาสำหรับห้องที่กำลังพิจารณา หากโมเดลของเราทำนายราคาเฉลี่ยของทุกห้องในชุดข้อมูลอยู่ที่ 310,000 ยูโร ความต่างของราคาทำนายกับราคาทำนายเฉลี่ยที่คิดเป็น -10,000 ยูโร อาจเกิดจากเพราะการที่มีพื้นที่ห้าสิบตารางเมตรซึ่งส่งผล +10,000 ยูโร ร่วมกับการอยู่ชั้นสองซึ่งส่งผล +0 ยูโร ร่วมกับการมีสวนอยู่ใกล้ซึ่งส่งผล +30,000 ยูโร และร่วมกับการห้ามเลี้ยงสัตว์ซึ่งส่งผล -50,000 ยูโร นี่เป็นเพียงรูปแบบคำอธิบายเดียวที่เป็นไปได้ Shapley value เป็นการพิจารณารูปแบบคำอธิบายที่เป็นไปได้หลากหลายนี้ เพื่อใช้พิจารณาว่าฟีเจอร์แต่ละตัวส่งผลให้ราคาทำนายของแต่ละรายการขยับห่างออกจากราคาทำนายเฉลี่ยทุกรายการมากน้อยอย่างไร
การคำนวณ Shapley value ของแต่ละฟีเจอร์
Shapley value ของแต่ละค่าฟีเจอร์คือตัวเลขแสดงมีส่วนร่วมเฉลี่ยของค่าฟีเจอร์หนึ่ง (contribution) เมื่อคำนวณจากทุกกลุ่มย่อยของค่าฟีเจอร์ (coalitions) ที่เป็นไปได้
| หมายเหตุ กลุ่มย่อยของค่าฟีเจอร์ (coalitions) ในที่นี้คือกลุ่มของฟีเจอร์ที่เรากำลังพิจารณา ไม่ได้หมายถึงฟีเจอร์ที่ใช้ในโมเดลทั้งหมด ซึ่งหมายความว่าเมื่อเราทำการพิจารณา เราจะสนใจค่าของแต่ละฟีเจอร์ภายในกลุ่ม ในขณะที่ค่าฟีเจอร์อื่นนอกกลุ่มยังคงถูกใช้เป็น input ในการทำงานของโมเดล เพียงแค่ไม่ได้สนใจว่าจะมีค่าเป็นอย่างไร |
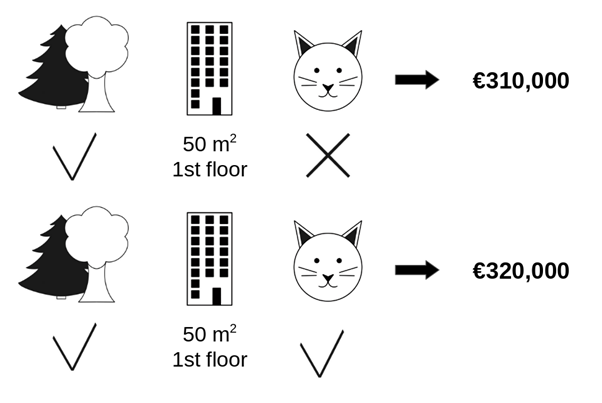
หากเราต้องการพิจารณาผลของค่า “ห้ามเลี้ยงสัตว์” เมื่อถูกใส่เข้ามาใช้กับโมเดลเพิ่มในกลุ่มฟีเจอร์ย่อยที่เดิมมีค่า “อยู่ใกล้สวน” และ “มีพื้นที่ 50 ตารางเมตร” อยู่ก่อนแล้ว กล่าวคือ เรากำลังพิจารณาว่าสำหรับห้องที่อยู่ใกล้สวนและมีพื้นที่ 50 ตารางเมตร ถ้าหากเราเพิ่มข้อบังคับว่า “ห้ามเลี้ยงสัตว์” จะมีผลกระทบต่อราคาอย่างไร โดยอาศัยขั้นตอนดังต่อไปนี้
- กำหนดกลุ่มย่อยของค่าฟีเจอร์ (coalition) ที่ต้องการพิจารณา ในกรณีสมมุตินี้ เลือกเป็นกลุ่มย่อยของค่าฟีเจอร์ที่ประกอบด้วย “มีพื้นที่ 50 m2” และ “อยู่ใกล้สวน”
- ค่าฟีเจอร์นอกกลุ่มย่อยของค่าฟีเจอร์ ให้ใช้ค่าสุ่ม(sample)จากข้อมูลรายการอื่นมาใช้แทน ในที่นี้ฟีเจอร์ย่อยที่อยู่นอกกลุ่ม ได้แก่ ชั้นของห้องพัก ซึ่งจากการสุ่มได้ค่าเป็น “ชั้น 1”
- นำค่าฟีเจอร์ที่ต้องการพิจารณาผลกระทบ คือ “ห้ามเลี้ยงสัตว์” เข้าสู่กลุ่มย่อยของค่าฟีเจอร์ดังกล่าวและทำการพิจารณา พบว่าราคาทำนายอยู่ที่ 310,000 ยูโร
- จากนั้น ดำเนินการสุ่มค่าฟีเจอร์การอนุญาตเลี้ยงสัตว์มาจากข้อมูลรายการอื่น (ห้องอื่น) เพื่อทำนายราคาห้องพักของคอนโดอีกรอบหนึ่ง ซึ่งอาจได้ค่า “อนุญาตเลี้ยงสัตว์” หรือ “ห้ามเลี้ยงสัตว์” ก็ได้ ในที่นี้เมื่อสุ่มค่าการอนุญาตเลี้ยงสัตว์จากข้อมูลรายการอื่น พบว่าได้ค่า “อนุญาตเลี้ยงสัตว์” ซึ่งส่งผลให้ราคาทำนายกลายเป็น 320,000 ยูโร
- จากการคำนวณนี้ เราจะประเมินได้ว่าผลกระทบของค่า “ห้ามเลี้ยงสัตว์” นั้นมีค่า €310,000 – €320,000 = -€10,000
แน่นอนว่าผลกระทบของค่าฟีเจอร์ “ห้ามเลี้ยงสัตว์” ที่ได้จากการประเมินด้วยวิธีนี้จะมีค่าที่แตกต่างกันออกไป แล้วแต่ว่าจะสุ่มค่าของฟีเจอร์จากข้อมูลของห้องไหน ดังนั้นหากต้องการให้ประเมินผลกระทบได้อย่างแม่นยำ จำเป็นต้องคำนวณด้วยแนวทางนี้ซ้ำหลายครั้ง แล้วนำค่าผลกระทบที่ได้มาหาค่าเฉลี่ย
เมื่อคำนวณผลกระทบตามแนวทางที่กล่าวมาจนครบทุกฟีเจอร์ในกลุ่มที่เป็นไปได้ Shapley value ของแต่ละฟีเจอร์คือค่าเฉลี่ยของผลกระทบของค่าฟีเจอร์นั้น (marginal contributions) ที่ได้จากการพิจารณาทุกกลุ่มย่อยของค่าฟีเจอร์ที่เป็นไปได้ อย่างไรก็ดีเนื่องจากระยะเวลาที่ต้องใช้เพื่อคำนวณค่าดังกล่าวจะเพิ่มขึ้นอย่างทวีคูณ (exponential growth) เมื่อมีจำนวนฟีเจอร์ที่ต้องการวิเคราะห์มากขึ้น ดังนั้นเพื่อให้เวลาที่ใช้ในการคำนวณนั้นไม่นานจนเกิดไป วิธีหนึ่งที่ทำได้คือจำกัดให้คำนวณค่าผลกระทบจากการสุ่มเพียงไม่กี่ครั้ง (sample) สำหรับแต่ละกลุ่มย่อยของค่าฟีเจอร์ที่เป็นไปได้
รูปด้านล่างแสดงกลุ่มย่อยของค่าฟีเจอร์ทั้งหมดที่เป็นไปได้ ซึ่งจำเป็นต้องใช้เพื่อคำนวณ Shapley value ของการ “ห้ามเลี้ยงสัตว์” คั่นแต่ละกลุ่มย่อยด้วยเครื่องหมาย “|” กลุ่มย่อยของค่าฟีเจอร์อาจมีจำนวนค่าฟีเจอร์ในกลุ่มเป็นเท่าใดก็ได้ ตัวอย่างเช่น ในแถวแรกของรูปแสดงกลุ่มย่อยของค่าฟีเจอร์ที่ไม่มีค่าฟีเจอร์ใดเลย ในขณะที่แถวที่สอง สาม และ สี่ แสดงกลุ่มย่อยของค่าฟีเจอร์ ที่มีจำนวนค่าฟีเจอร์หนึ่ง สอง และสาม ตามลำดับ กล่าวคือ กลุ่มย่อยของค่าฟีเจอร์ที่เป็นไปได้ทั้งหมด ในสถานการณ์ตัวอย่างนี้ได้แก่:
- ไม่มีค่าฟีเจอร์
- อยู่ใกล้สวน
- มีพื้นที่ 50 m2
- อยู่ชั้นสอง
- อยู่ใกล้สวน และ มีพื้นที่ 50 m2
- อยู่ใกล้สวน และ อยู่ชั้นสอง
- มีพื้นที่ 50 m2 และ อยู่ชั้นสอง
- อยู่ใกล้สวน, มีพื้นที่ 50 m2 และ อยู่ชั้นสอง
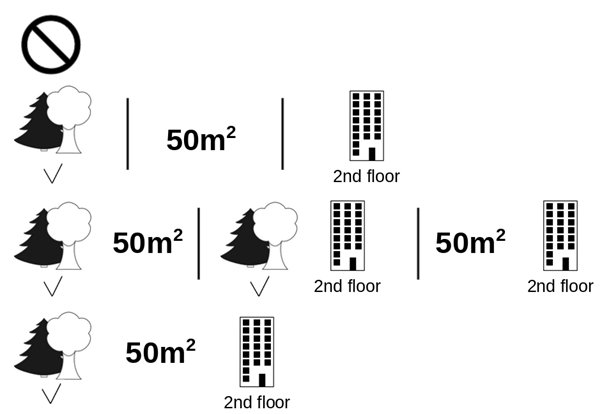
สำหรับแต่ละกลุ่มย่อยของค่าฟีเจอร์เหล่านี้ เราคำนวณหาราคาทำนายในกรณีที่บังคับและไม่บังคับค่าฟีเจอร์ “ห้ามเลี้ยงสัตว์” จากนั้นคำนวณหาค่าผลต่างของราคาทำนายในสองกรณี แล้วนำค่าผลต่างราคาทำนายที่ได้จากทุกรูปแบบกลุ่มย่อยของค่าฟีเจอร์มาเฉลี่ยแบบถ่วงน้ำหนัก (weighted average) เพื่อให้ได้ Shapley value ของค่าฟีเจอร์ “ห้ามเลี้ยงสัตว์”
เป็นอย่างไรบ้างครับ ในบทความนี้เราพูดถึงไอเดียของการคำนวณและตีความ Shapley value พอจะเห็นวิธีการใช้ประโยชน์กันบ้างแล้วใช่ไหมครับ ในบทความต่อไปเราจะมาพูดถึงตัวอย่างการใช้งาน Shapley value ในการตีความโมเดลพร้อมกับ ข้อดีและข้อเสียของเทคนิคนี้กันครับ
ข้อมูลที่เกี่ยวข้องและข้อมูลเพิ่มเติม
- Shapley, Lloyd S. “A value for n-person games.” Contributions to the Theory of Games 2.28 (1953): 307-317
- Interpretable Machine Learning โดย Christoph Molnar Chapter 9.5: Shapley Values
แปล สังเคราะห์ และ เรียบเรียง โดยปฏิภาณ ประเสริฐสม
ตรวจทานและปรับปรุงโดย พีรดล สามะศิริ




Senior Project Manager & Data Scientist
at Big Data Institute (Public Organization), BDI





