
ความไม่ซื่อสัตย์ในการดำเนินธุรกิจนั้นไม่ใช่สิ่งที่แปลกใหม่ ถึงแม้ว่าประวัติศาสตร์จะได้สอนเราว่าการทุจริตไม่ส่งผลดีในระยะยาว แต่ก็ยังมีข่าวอื้อฉาวด้านการเงินมากมายเกิดขึ้นในหลายประเทศ การปฏิวัติอุตสาหกรรม 4.0 ที่กำลังเกิดขึ้นอยู่ ณ ตอนนี้ ในมุมหนึ่งก็ยิ่งทำให้เกิดการฉ้อโกงกันง่ายขึ้น แต่ในอีกมุมหนึ่งก็ได้ทำให้เกิดเครื่องมือใหม่ ๆ ที่สามารถนำมาช่วยตรวจจับบริษัทที่ไม่ซื่อสัตย์ที่มีวิถีปฏิบัติคดโกงได้
งานวิจัยโดย Joanna Wyrobek จาก Department of Corporate Finance, Cracow University of Economics ประเทศโปแลนด์ ได้ทำการตรวจสอบว่า มีความเป็นไปได้หรือไม่ที่จะสร้างโมเดล machine learning ให้มีประสิทธิภาพในการนำงบการเงินรายปีของบริษัทหนึ่ง ๆ มาใช้ระบุว่าบริษัทเดียวกันนี้มีธุรกรรมที่ฉ้อโกงอย่างมีนัยสำคัญในปีเดียวกันหรือไม่ โดยธุรกรรมที่ฉ้อโกงนี้อาจจะ แต่ไม่จำเป็นต้อง ส่งผลต่องบการเงินในปีเดียวกันโดยตรงก็ได้ เพราะถึงแม้ธุรกรรมการโกงจะไม่ได้มีผลต่องบการเงินของบริษัทโดยตรง แต่พฤติกรรมการโกงนี้ก็อาจมีผลต่องบการเงินในทางอ้อม ซึ่งจะทำให้เกิด pattern บางอย่างที่สามารถนำ machine learning หรือ AI มาตรวจจับได้
สร้างโมเดล Machine Learning
โดย Wyrobek ได้รวบรวมข้อมูลงบการเงินของ 54 บริษัทที่ถูกลิสต์ไว้ใน Wikipedia ว่าได้มีการฉ้อฉลทางบัญชีครั้งใหญ่ที่สุดในศตวรรษที่ 20 และได้เลือกอีก 58 ตัวอย่างบริษัท “ซื่อสัตย์” ที่อยู่ในอุตสาหกรรมเดียวกันกับ 54 บริษัทแรก, มีขนาดใกล้เคียงกัน, และมีประเภทกิจกรรมการดำเนินธุรกิจที่ใกล้เคียงกัน ซึ่ง Algorithm จะถูกฝึกสอนด้วยงบการเงิน 1,317 ฉบับ บริษัทที่ถูกคัดเลือกมาทำโมเดลนี้ส่วนใหญ่ลิสต์อยู่ในตลาดหุ้น NYSE หรือไม่ก็ NASDAQ ซึ่งถูกระบุปีที่บริษัทได้ลงมือทำการโกงโดยอาศัยข้อมูลการตรวจสอบของ SEC (Securities and Exchange Commission) และข่าวตีพิมพ์เกี่ยวกับการติดสินบน, การหลีกเลี่ยงภาษี, และกลโกงอื่น ๆ ที่กระทำโดยบริษัทเหล่านี้

ข้อมูลที่ใช้สำหรับงานวิจัยนี้เอามาจากเว็บไซต์ของ SEC โดยจะเป็นฐานข้อมูลการสืบสวนของ SEC และงบการเงินประจำปี (รายงาน 10-K) แต่สำหรับข้อมูลในบางปีที่ขาดหาย และข้อมูลของบริษัทที่ไม่ได้ลิสต์อยู่ในตลาดหลักทรัพย์นั้น จะใช้ฐานข้อมูลจาก Thompson Reuters Worldscope โดยใช้งบการเงินทุกงบ (งบดุล, งบกำไรขาดทุน, และงบกระแสเงินสด) และอัตราส่วนทางการเงินต่าง ๆ รวมแล้วมีทั้งหมด 298 ตัวแปร
ผลการวิเคราะห์
ตารางในรูปที่ 1 แสดงผลจากการเทรนโมเดล ซึ่งจะเห็นได้ว่า accuracy ของ algorithms ที่ดีที่สุดนั้นสูงเกือบ 95% การที่โมเดลของงานวิจัยนี้มีประสิทธิภาพดีนั้น มองในมุมหนึ่ง ก็เป็นเพราะว่า ผู้วิจัยเลือกใช้เฉพาะกรณีอื้อฉาวฉ้อโกงบัญชีที่มีนัยสำคัญที่สุดในศตวรรษที่ 20 ซึ่งเป็นเคสที่มีความชัดเจนในการโกงมากที่สุด มาทดสอบ (evaluate) โมเดล คงจะเป็นเรื่องที่น่าแปลกใจมากถ้า ดันมีกรณีที่โมเดลนี้ไม่สามารถตรวจจับเคสที่มีการโกงอย่างชัดเจนเหล่านี้ได้ แต่ถ้ามองในอีกมุมหนึ่งแล้ว การโกงเหล่านี้ในหลายเคสก็ไม่ได้ส่งผลกระทบโดยตรงต่องบการเงินของบริษัท แต่โมเดลก็ยังคงสามารถตรวจจับได้
Algorithms ที่ประสบความสำเร็จมากที่สุดในที่นี้คือ gradient-boosted decision trees (XGB) และ random-forest (RF) โดยที่ XGB มี accuracy = 93.5%, precision = 67.3%, และ recall = 92.0% ส่วน random forest นั้นมี accuracy = 94.7%, precision = 80.0%, และ recall = 76.1% ผู้วิจัยพบว่าหนึ่งในโมเดล “ดั้งเดิม” ที่ชื่อว่า linear discriminant analysis (LDA) นั้นก็ค่อนข้างที่จะมีประสิทธิภาพดีเช่นกัน โดยมี accuracy = 92.2%, precision = 68.3%, และ recall = 68.7%
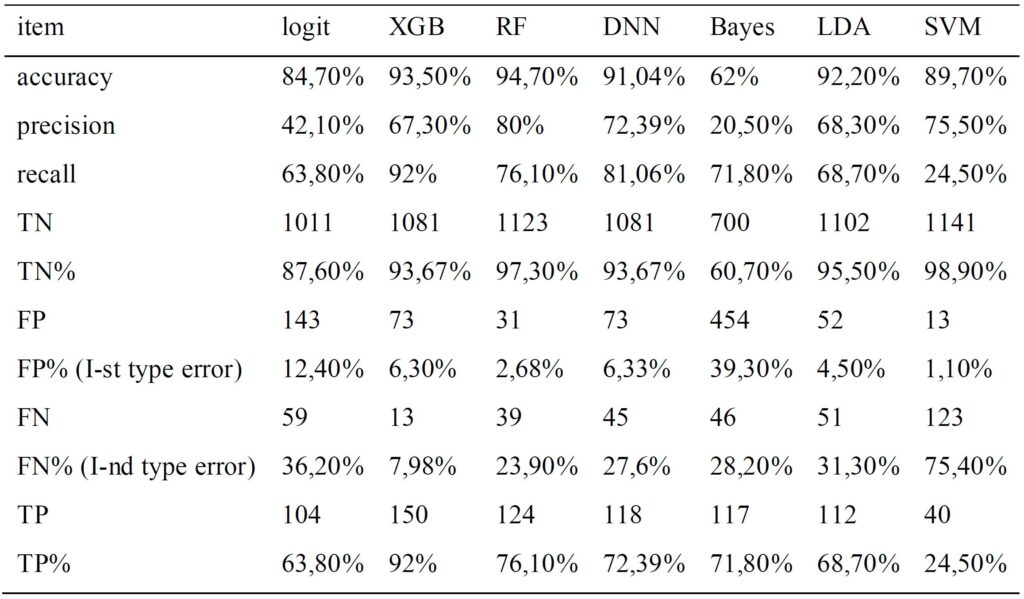
ลองมาดูที่พารามิเตอร์ต่าง ๆ ใน confusion matrix กันบ้าง จะพบว่า XGB นั้นมี 1st type error (% False Positive) เท่ากับ 6.30% และมี 2nd type error (% False Negative) เท่ากับ 7.98% ซึ่งหมายความว่า algorithm นี้มองผิดว่าบริษัทที่ซื่อสัตย์เป็นบริษัทที่ไม่ซื่อสัตย์เพียงแค่ 7 เคสใน 100 และมองผิดว่าบริษัทที่คดโกงเป็นบริษัทที่เชื่อถือได้ 8 เคสใน 100 เคส ส่วนใน random forest algorithm นั้นมี 1st type error (% False Positive) เท่ากับ 2.68% และมี 2nd type error (% False Negative) เท่ากับ 23.9% และสำหรับ LDA นั้น 1st type error (% False Positive) เท่ากับ 4.5% และ 2nd type error (% False Negative) เท่ากับ 31.3%
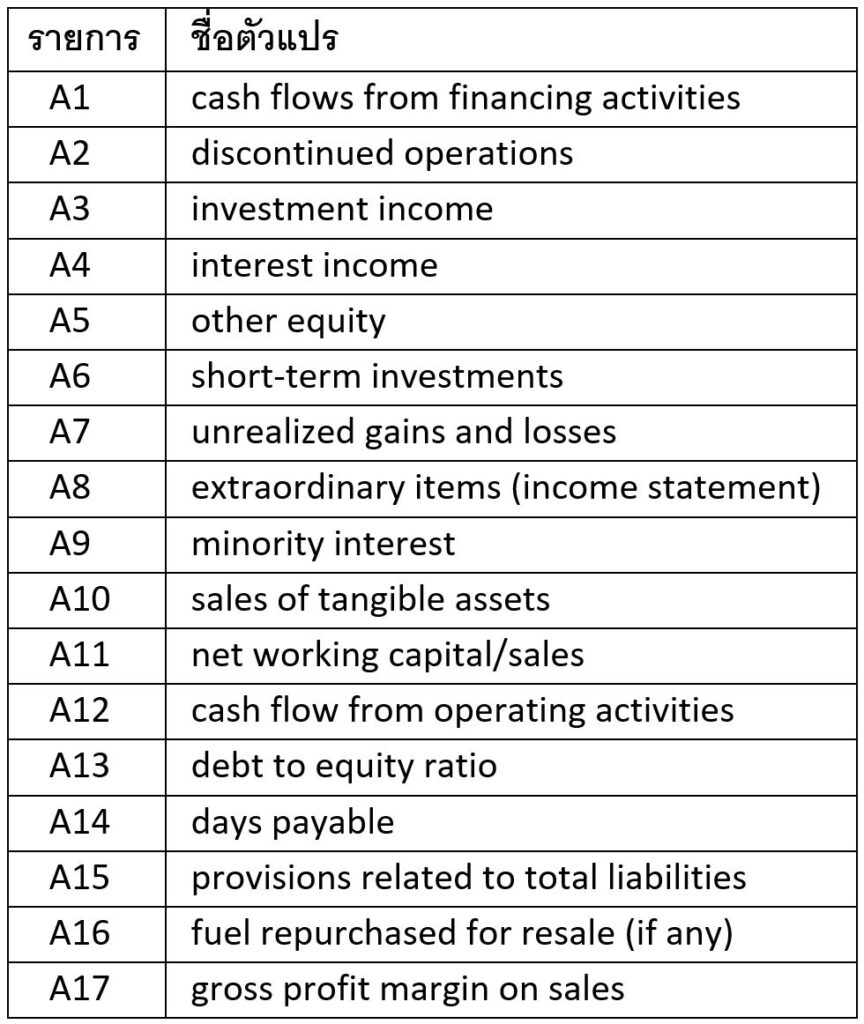
วิธีหนึ่งในการทำความเข้าใจผลลัพธ์ของโมเดล คือการดูตัวแปรที่ถูก algorithms ต่าง ๆ เลือกนำมาใช้เป็นหลัก 15 ตัวแปร จากทั้งหมด 289 ตัวแปร ผู้อ่านสามารถดูรายละเอียดได้ในหัวข้อที่ 4.1 ของเปเปอร์ต้นฉบับ ส่วนในบทความนี้จะขอกล่าวอย่างสรุปดังนี้
ใน algorithms ต่าง ๆ ทั้งหมดที่งานวิจัยชิ้นนี้ใช้ พบว่าบริษัทที่ไม่ซื่อสัตย์ จะมีค่าของตัวแปรต่าง ๆ เหล่านี้สูงกว่าในบริษัทปกติทั่วไป:
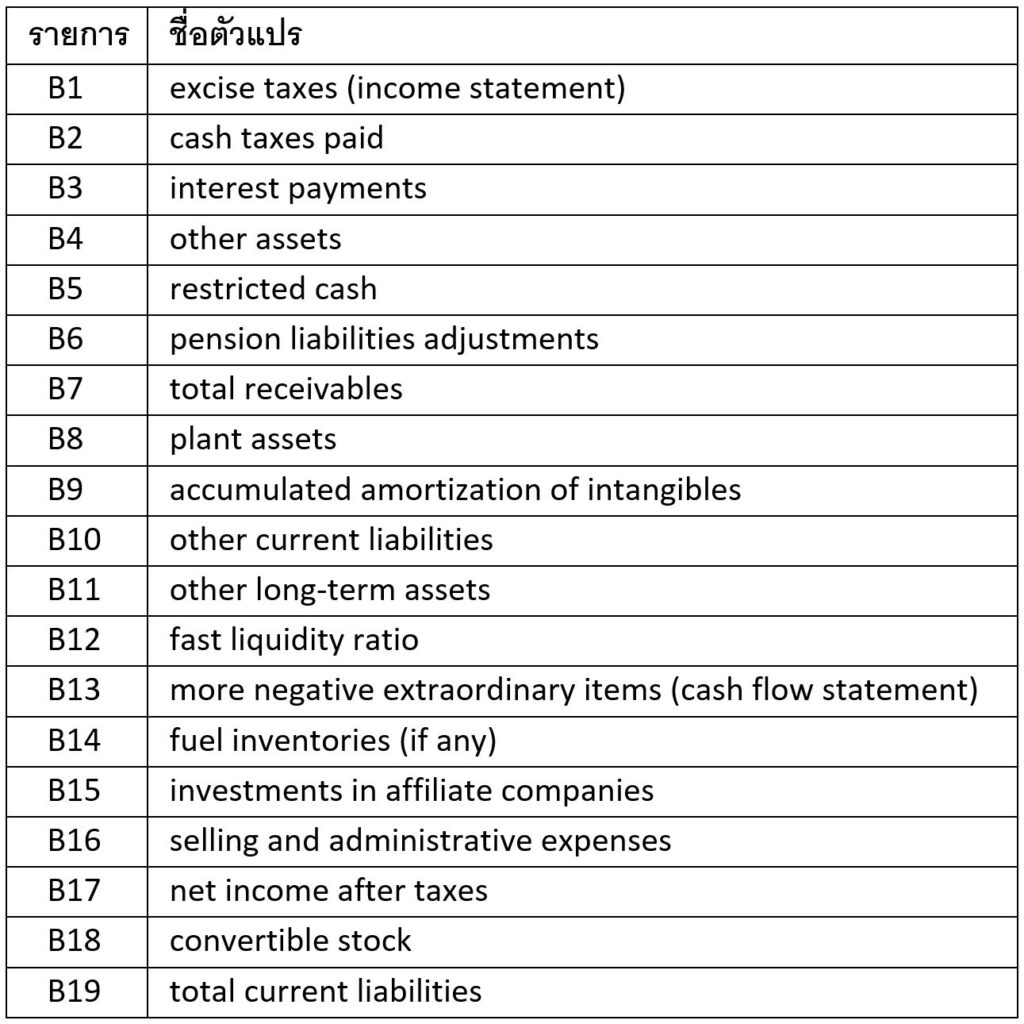
และมีค่าของตัวแปรต่าง ๆ เหล่านี้ต่ำกว่าในบริษัทปกติทั่วไป:
รายการที่ A1 ถึง A10 บ่งชี้ว่า ในงบการเงินของบริษัทที่ไม่ซื่อสัตย์โดยส่วนมาก มักจะมีรายการลงทุนต่าง ๆ และกำไร/ขาดทุนพิเศษที่ไม่เกี่ยวข้องกับธุรกิจหลัก
ส่วนรายการ A13 นั้นบ่งชี้ว่าบริษัทที่คดโกงมักจะมีหนี้สูง ทำให้มีความเสี่ยงที่จะล้มละลายสูง ซึ่งอาจส่งผลให้มีแรงกดดันไปยังผู้บริหารให้กระทำการในสิ่งที่ไม่มีจรรยาบรรณเพื่อปกป้องบริษัทจากการล้มละลาย
นอกจากนี้แล้ว รายการที่ B1 และ B2 ยังบ่งชี้ว่าบริษัทที่คดโกงมักจะมีการชำระภาษีต่ำกว่าบริษัททั่วไปอีกด้วย
ส่วนรายการที่ A17, B16, และ B17 รวมกันนั้นอาจจะตีความได้ว่า ถึงแม้บริษัทที่คดโกงจะมีอัตรากำไรขั้นต้น (gross profit margin) สูงกว่าปกติ และมีค่าใช้จ่ายในการขายและบริหาร (SG&A) ต่ำกว่าปกติ แต่ก็ยังคงมีอัตรากำไรสุทธิ (net profit margin) ที่ต่ำกว่าปกติ ซึ่งหมายความว่าบริษัทที่คดโกงเหล่านี้มักมีค่าใช้จ่ายอื่น ๆ ที่ไม่ใช่ cost of goods sold (CoGS) หรือ SG&A ที่สูงกว่าบริษัทปกติทั่วไป
บทสรุป
ผลการทดลองบ่งชี้ว่า บริษัทที่ไม่ยุติธรรมมักจะมีอัตรากำไรขั้นต้น (gross profit margin) สูง แต่มีอัตรากำไรสุทธิ (net profit margin) ต่ำ และมีการจ่ายภาษีที่ต่ำกว่าบริษัททั่วไป อีกทั้ง บริษัทที่ไม่ซื่อสัตย์ยังมักจะมีกิจกรรมที่เกี่ยวข้องกับการเงิน (financial operations) สูงกว่าปกติด้วย ซึ่งรวมถึงการระดมทุนเพิ่ม และการลงทุนในสินทรัพย์ทางการเงินต่าง ๆ (financial assets) นอกจากนี้แล้ว บริษัทที่ไม่ยุติธรรมยังมักจะมีอัตราส่วนสภาพคล่อง (liquidity ratios) ต่าง ๆ ที่ต่ำกว่าปกติ มีรายการพิเศษต่าง ๆ (extraordinary items) สูงกว่าปกติ มีรายการจากการดำเนินงานที่ยกเลิก (discontinued operations) และมีหนี้สูงกว่าบริษัทปกติทั่วไป
แหล่งที่มา
เรียบเรียงโดย อิสระพงศ์ เอกสินชล
ตรวจทานโดย นนทวิทย์ ชีวเรืองโรจน์

Lead Technologist (Tech and Coaching) - Data Analytics Services Division (DAS), Big Data Institute (BDI)












