นับตั้งแต่บริษัท OpenAI ได้ทำการเปิดตัว ChatGPT ให้บุคคลทั่วไปได้ใช้งาน ในช่วงเดือนพฤศจิกายน 2022 ที่ผ่านมา และตามมาด้วยเครื่องมืออื่น ๆ ในลักษณะคล้ายคลึงกันจากบรรดาบริษัทยักษ์ใหญ่ในวงการเทคโนโลยี อาทิ Google Bard, Microsoft Bing รวมถึง Git Copilot ซึ่งเครื่องมืออัจฉริยะที่เกิดขึ้นใหม่นี้ ล้วนเข้ามามีบทบาทในการอำนวยความสะดวกในทำงานด้านต่าง ๆ ของมนุษย์ให้เป็นเรื่องง่ายดายมากยิ่งขึ้น ส่งผลให้เกิดการตื่นตัวของผู้คนเป็นวงกว้าง ต่อการมาถึงของเทคโนโลยีปัญญาประดิษฐ์ (Artificial Intelligence; AI) ทางด้านภาษาที่สามารถจับต้องได้จริงเหล่านี้ โดยบริษัทน้อยใหญ่ในหลากหลายอุตสาหกรรมล้วนแล้วแต่ต้องการนำความฉลาดของ AI ดังกล่าวมาประยุกต์ใช้เพื่อตอบโจทย์ของตนเอง
สิ่งที่อยู่เบื้องหลังเครื่องมืออัจฉริยะดังกล่าวมาข้างต้นนั้น เรียกว่า แบบจำลองทางภาษาขนาดใหญ่ (Large Language Model; LLM) ซึ่งเป็นขั้นกว่าของแบบจำลองทางภาษา (Language Model) ดั้งเดิม โดยเป็นแบบจำลองทางสถิติจากคลังข้อมูลของคำในภาษาที่สนใจ จะแสดงถึงความน่าจะเป็นในการเกิดของคำลำดับต่อ ๆ ไป ซึ่งมักพบได้ในงานที่เกี่ยวข้องกับการประมวลผลภาษาธรรมชาติ (Natural Language Processing; NLP) โดยสิ่งที่ทำให้ LLM มีความพิเศษขึ้นมานั้นคือ ปริมาณที่มหาศาลของข้อมูลที่แบบจำลองใช้ในการเรียนรู้ รวมถึงจำนวนพารามิเตอร์ที่ใช้ในแบบจำลองนั้น ๆ ที่มีจำนวนมากกว่าหลายพันล้านตัว ซึ่งตัวอย่างของ LLM ที่น่าสนใจ ได้แก่ GPT-3, GPT-3.5 และ GPT-4 ของบริษัท OpenAI ที่เป็นขุมพลังเบื้องหลัง ChatGPT นอกจากนี้ยังมี PaLM 2 และ Llama 2 ซึ่งเป็นแบบจำลองเวอร์ชันล่าสุดของ บริษัท Google และบริษัท Meta ตามลำดับ อีกทั้ง ยังรวมไปถึงแบบจำลองอื่น ๆ ที่มีการนำเสนออยู่บนเว็บไซต์ Hugging Face อีกด้วย

การทำงานของ LLM ในมุมมองของผู้ใช้งานนั้น ค่อนข้างเข้าใจง่าย มีความตรงไปตรงมา นั่นคือ เมื่อผู้ใช้ป้อนข้อความ (Input Text) เข้าไปแล้ว แบบจำลองจะทำการประมวลผล และสร้างข้อความตอบกลับ (Output Text) ส่งคืนให้ผู้ใช้ ซึ่งมีความหมายที่สอดคล้องกับข้อความที่ผู้ใช้ใส่เข้าไป ด้วยหลักการนี้ ส่งผลให้เกิดการต่อยอดนำแบบจำลองไปประยุกต์ใช้ในงานที่หลากหลาย อาทิ การทำ Chatbot อย่าง ChatGPT หรือ Google Bard ทั้งนี้ เพื่อให้แบบจำลองทำงานได้อย่างมีประสิทธิภาพ ต้องมีการเลือกใช้ ข้อความ/คำสั่ง/ตัวอย่าง (ซึ่งในที่นี้เรียกว่า Prompt) ให้เหมาะสมเฉพาะงานนั้น ๆ รวมถึงต้องมีความชัดเจน สำหรับเป็น Input Text เพื่อให้แบบจำลองตอบข้อมูลกลับมาได้อย่างถูกต้อง ครบถ้วน ตรงตามวัตถุประสงค์ของผู้ใช้ ดังนั้น จึงก่อให้เกิดอีกสายงานหนึ่งขึ้นมาสำหรับการออกแบบและพัฒนา Prompt โดยเฉพาะ ซึ่งมีชื่อเรียกว่าการทำ Prompt Engineering
อย่างไรก็ตาม ในการใช้งานจริงผู้ใช้ไม่ได้ต้องการแค่เพียงนำ LLM ไปใช้ในการสร้างข้อความต่อจาก Prompt ที่กำหนดให้เท่านั้น หากยังต้องการใช้งานร่วมกับชุดข้อมูลของตนเองโดยเฉพาะ อาทิ การให้แบบจำลองตอบคำถามโดยอ้างอิงจากกลุ่มของบทความที่มีอยู่ หรือการสร้าง Chatbot โดยอ้างอิงจากข้อมูลความสัมพันธ์ของลูกค้าในระบบ Customer Relationship Management (CRM) ของบริษัท รวมถึงการสรุปความจากหนังสือที่กำหนด นอกจากนี้ ยังมีความต้องการนำผลลัพธ์ที่ได้ไปใช้ต่อในงานอื่น ๆ เช่น การนำไปวิเคราะห์ต่อด้วย Machine Learning Algorithm รวมถึงการส่งอีเมล์หรือการโพสต์ลงโซเชียลมีเดียไปยังกลุ่มเป้าหมายโดยอัตโนมัติ อีกทั้งการเรียกใช้งาน API จากบริการภายนอกต่าง ๆ ดังนั้น การที่จะสร้างแอปพลิเคชันที่ประยุกต์ใช้งาน LLM และนำผลลัพธ์ไปใช้งานต่ออย่างมีประสิทธิภาพตั้งแต่ต้นน้ำถึงปลายน้ำนั้น นอกจากความต้องการผู้เชี่ยวชาญในการใช้งาน LLM ซึ่งอาจหมายความถึง Prompt Engineer แล้ว ยังต้องมีนักพัฒนาที่มีความเชี่ยวชาญในอีกหลากหลายส่วน เพื่อช่วยกันสร้างแอปพลิเคชันดังกล่าวให้สำเร็จ ส่งผลให้ผู้ประกอบการที่มีความสนใจใช้งาน LLM แต่ไม่มีทีมงานที่มีความเชี่ยวชาญเป็นจำนวนมากพอต้องสูญเสียโอกาสในจุดนี้ไป ด้วยข้อจำกัดดังกล่าว จึงมีผู้พัฒนาเฟรมเวิร์คตัวหนึ่งออกมาเพื่อให้การสร้างแอปพลิเคชันจาก LLM นั้น เป็นเรื่องที่ง่ายยิ่งขึ้น โดยเฟรมเวิร์คนั้นมีชื่อว่า “LangChain”
LangChain คืออะไร?
LangChain เปิดตัวในเดือนตุลาคม 2022 โดยเป็นโครงการภายใต้การดูแลของหัวเรือใหญ่อย่างคุณ Harrison Chase เพื่อสร้างเฟรมเวิร์คที่เป็น Open Source สำหรับอำนวยความสะดวกในการนำ LLM มาพัฒนาเป็นแอปพลิเคชัน โดยคำว่า LangChain มาจากการรวมกันของคำ 2 คำ ได้แก่ คำว่า “Lang” ซึ่งย่อมาจาก “Language” ที่แปลว่า “ภาษา” และคำว่า “Chain” ที่แปลว่า “ห่วงโซ่” เนื่องจาก ในการทำงานของ LangChain นั้น จะนำแบบจำลองทางภาษาขนาดใหญ่ (LLM) มาเชื่อมโยงกับส่วนประกอบอื่น ๆ เข้าด้วยกันคล้ายกับการล่ามโซ่
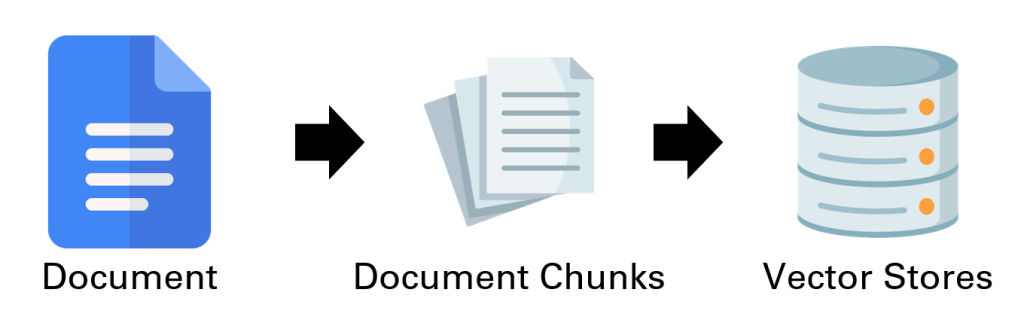
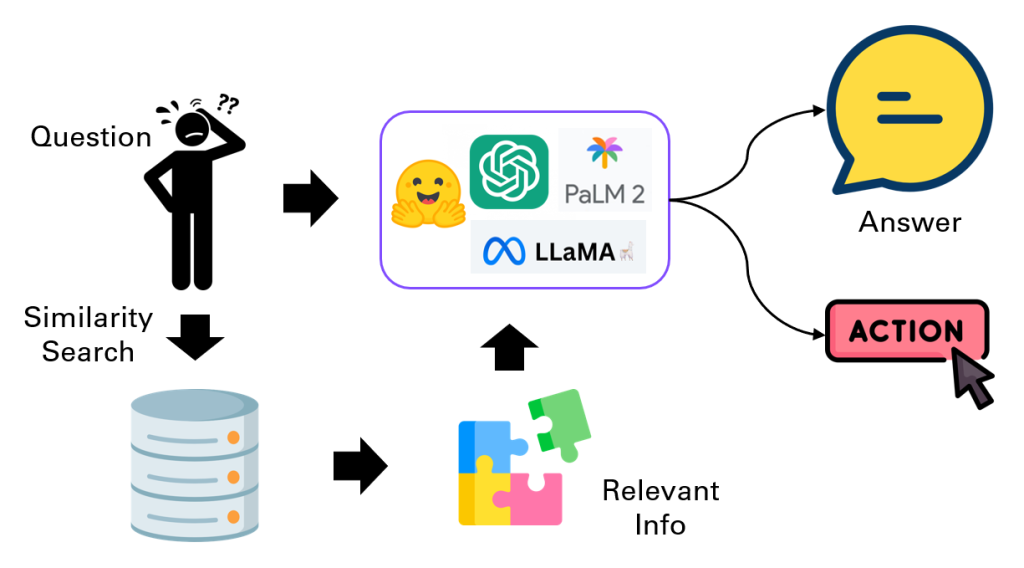
ก่อนจะลงไปที่รายละเอียดส่วนประกอบต่าง ๆ ของ LangChain นั้น ก่อนอื่นจะขอเริ่มจากการอธิบายหลักการทำงานอย่างง่ายของมันก่อน เพื่อที่ผู้อ่านจะได้เห็นถึงภาพรวมของ LangChain ได้ดีขึ้น เริ่มจากการจัดการกับข้อมูลของผู้ใช้ โดย LangChain จะแบ่งข้อมูลเอกสารออกเป็นชิ้น ๆ (Chunks) จากนั้นจึงทำการแปลงข้อมูลที่เป็นตัวอักษรในแต่ละ Chunk ให้กลายเป็นเวกเตอร์ของตัวเลขซึ่งสามารถนำไปคำนวนต่อได้โดยง่ายโดยใช้ Embedding Model และจัดเก็บไว้บนพื้นที่สำหรับจัดเก็บข้อมูลในรูปแบบเวกเตอร์ (Vector Stores) ในการทำงานจริง LangChain จะรับข้อความเข้ามาในระบบ จากนั้นจะนำข้อความดังกล่าวเข้าสู่แบบจำลองโดยตรงทางหนึ่ง และอีกทางหนึ่งคือการนำข้อความดังกล่าวไปแปลงเป็นเวกเตอร์และค้นหาเวกเตอร์ที่ใกล้เคียงที่สุดในฐานข้อมูล ก่อนจะแปลงเวกเตอร์นั้นกลับออกมาเป็นข้อความแล้วนำเข้าสู่แบบจำลองอีกทางหนึ่ง โดยการนำข้อความเข้าสู่แบบจำลองที่กล่าวมานั้น จะเป็นการนำเข้าร่วมกับคำสั่งแม่แบบ (Prompt Template) ที่ LangChain เตรียมไว้ เพื่อให้ได้รับผลลัพธ์ 2 อย่างด้วยกัน คือ (1) คำตอบที่ได้รับจากข้อความนั้น ๆ และ (2) การตัดสินใจเลือกสิ่งที่ระบบจะดำเนินการต่อไป (ในที่นี้เรียกว่าการทำ Action) เช่น การส่งอีเมล์ การเรียกใช้ API หรือการนำไปวิเคราะห์อื่น ๆ
สำหรับแนวคิดที่สำคัญของ LangChain นั้น ประกอบด้วย 3 ส่วน ดังนี้
- Components คือ การมีอยู่ของส่วนประกอบต่าง ๆ ที่จำเป็นต่อการสร้างแอปพลิเคชัน อาทิ
- เครื่องมือในนำเข้าเอกสาร (Document Loaders) และเครื่องมือในการแบ่งข้อมูลออกเป็น Chunks (Text Splitters)
- พื้นที่สำหรับจัดเก็บข้อมูลในรูปแบบเวกเตอร์ (Vector Stores)
- แบบจำลอง ได้แก่ LLM และ Embedding Model
- คำสั่งแม่แบบ (Prompt Template)
- เครื่องมือ (Tools) สำหรับการทำ Action ต่าง ๆ
- Chains คือ การเชื่อมโยงส่วนประกอบต่าง ๆ ที่จำเป็นเข้าด้วยกันตามลำดับ มีจุดหมุ่งหมายเพื่อให้บรรลุงานที่ต้องการ เช่น การสรุปความหนังสือ หรือการทำ Chatbot
- Agents คือ การใช้ประโยชน์จาก LLM ในการเลือก Action ที่จะดำเนินการต่อ ซึ่งจะแตกต่างจากสิ่งที่ดำเนินการใน Chain ที่ผู้ใช้จะต้องกำหนดเองว่าในแต่ละขั้นตอนต้องทำอะไร แต่ในส่วนของ Agents แบบจำลองจะพิจารณาและกำหนดให้ว่าจะดำเนินการใด และเรียงลำดับอย่างไร
LangChain Framework
ในการทำงานของ LangChain นั้น แต่ละส่วนประกอบในเฟรมเวิร์คจะมีหน้าที่ที่แตกต่างกันออกไป ดังนี้
- LangChain Libraries: ไลบรารี่สำหรับใช้งาน LangChain ซึ่งใช้ได้ในทั้งภาษา Python และ JavaScript โดยมีหน้าที่หลักในการเป็นตัวกลางเพื่อสื่อสารกับผู้ใช้ และผสานส่วนประกอบต่าง ๆ เข้าด้วยกัน รวมถึงการเชื่อมโยงกับ Chains และ Agents
- LangChain Templates: เทมเพลตตัวอย่างในการพัฒนาแอฟพลิเคชันสำหรับงานต่าง ๆ อาทิ การทำ Chat Bot และการวิเคราะห์ขั้นสูงอื่น ๆ โดยผู้ใช้สามารถเริ่มต้นในการพัฒนาผลิตภัณฑ์ของตนเองได้ โดยอ้างอิงจากเทมเพลตเหล่านี้
- LangServe: เครื่องมือสำหรับการพัฒนา REST API สำหรับแต่ละ Chains ที่สร้างขึ้น เพื่อให้แอปพลิเคชันสามารถเข้าถึงได้จากภายนอก
- LangSmith: แพลตฟอร์มสำหรับนักพัฒนาเพื่อใช้ในการปรับแต่งแอปพลิเคชันให้สมบูรณ์และทำงานได้อย่างราบรื่น โดยมีฟังก์ชันจำเป็นที่หลากหลาย อาทิ การติดตามสถานะการทำงาน (Monitoring) การประเมินผลการทำงาน (Evaluation) การทดสอบระบบ (Testing) และการแก้ไขจุดบกพร่อง (Debugging)
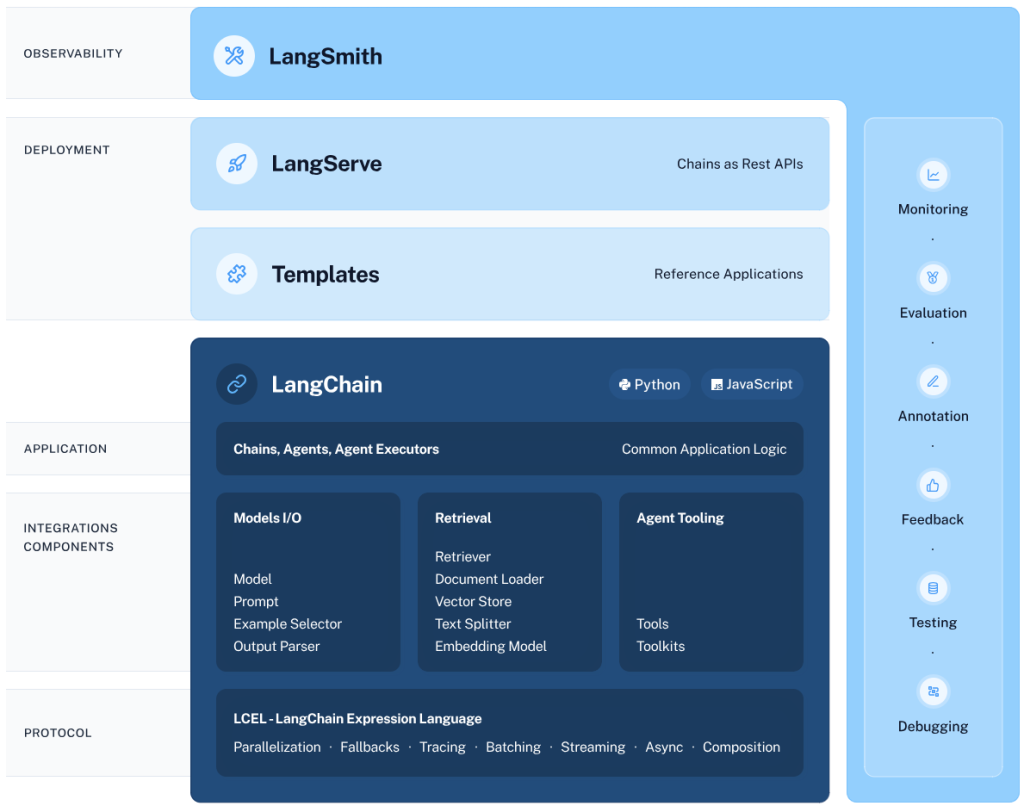
ส่วนประกอบที่กล่าวมาข้างต้นจะร่วมกันทำงานตั้งแต่การพัฒนาแอปพลิเคชัน จนไปถึงการปรับแต่ง และการนำไปใช้ โดยเริ่มต้นการพัฒนาโดยใช้ LangChain Libraries ซึ่งสามารถอ้างอิงตัวอย่างจาก LangChain Templates เพื่อเป็นแนวทางและปรับใช้เป็นของตนเอง จากนั้นทำการแปลง Chains ที่สร้างขึ้นให้เป็น API ได้อย่างสะดวกโดยใช้ LangServe และสุดท้าย LangSmith จะเป็นตัวช่วยในการติดตาม ทดสอบ และประเมินผลการทำงานของแอปพลิเคชัน รวมไปถึงการแก้ไขสิ่งผิดปกติที่เกิดขึ้น
โมดูลของ LangChain
ตามที่กล่าวมาในหัวข้อที่แล้ว ผู้ใช้สามารถสร้างแอปพลิเคชันผ่านการใช้งาน LangChain Library ซึ่งประกอบไปด้วยโมดูลต่าง ๆ สำหรับการพัฒนาในแต่ละส่วนประกอบ ดังนี้
- Model I/O
ส่วนประกอบสำคัญที่สุดในการสร้างแอปพลิเคชันที่มีเบื้องหลังเป็นแบบจำลองทางด้านภาษา ก็คือตัว “แบบจำลอง” โดยในโมดูลนี้จะเป็นส่วนของการจัดการแบบจำลองเหล่านั้น รวมไปถึงเครื่องมืออื่น ๆ ที่จำเป็น ได้แก่- Models: แบบจำลองที่ใช้งานบน LangChain มีอยู่ด้วยกัน 2 ชนิด คือ (1) LLM พื้นฐาน ซึ่งใช้ในการเติมข้อความให้สมบูรณ์ต่อจากข้อความที่กำหนด (2) Chat Model ซึ่งถูกพัฒนาต่อมาจาก LLM อีกที ให้เข้าใจบทสนทนา และสามารถตอบข้อความในลักษณะเดียวกันกลับไปได้
- Prompts: ตัวอย่าง ข้อความ/ชุดคำสั่ง ซึ่งจัดทำขึ้นสำหรับสร้างข้อความนำเข้า (Input Text) เพื่อเป็นแนวทางให้แบบจำลองมีการตอบสนองที่ถูกต้อง เข้าใจบริบทของข้อความ และสร้างข้อความผลลัพธ์ที่สอดคล้องกัน
- Output Parsers: ส่วนในการแยกผลลัพธ์ที่ได้จากแบบจำลอง และนำมาจัดรูปแบบให้อยู่ในลักษณะเฉพาะตามที่ผู้ใช้ต้องการ
- Retrieval
ในการพัฒนาแอปพลิเคชันจากแบบจำลองทางภาษาของตนเองนั้น นอกเหนือจากชุดข้อมูลเดิมที่ใช้ในการสร้างแบบจำลองแล้ว ผู้พัฒนาส่วนใหญ่ยังต้องการนำชุดข้อมูลของตนเองมาเป็นส่วนประกอบสำคัญในการตัดสินใจของแบบจำลองนั้น ๆ ดังนั้น เครื่องมือสำหรับการนำเข้าและจัดการข้อมูลภายนอกจึงมีความจำเป็น ซึ่งถูกนำเสนอในโมดูลนี้ โดยประกอบไปด้วยเครื่องมือที่หลากหลาย อาทิ- เครื่องมือในนำเข้าเอกสาร (Document Loaders)
- เครื่องมือในการแบ่งข้อมูลออกเป็น Chunks (Text Splitters)
- เครื่องมือในการแปลงรูปแบบเอกสาร (Document Transformers)
- แบบจำลองในการแปลงข้อความให้อยู่ในรูปแบบของเวกเตอร์ (Text embedding models)
- พื้นที่สำหรับจัดเก็บข้อมูลในรูปแบบเวกเตอร์ (Vector Stores)
- Agents
แนวคิดสำคัญอย่างหนึ่งของ LangChain คือ Agents โดยเป็นการใช้ LLM ในการพิจารณาและตัดสินใจว่าจะดำเนินการ (เรียกว่า การทำ Action) อะไรบ้าง และเรียงลำดับอย่างไร ส่งผลให้เกิดความยืดหยุ่นและความหลากหลายในการดำเนินการกว่าการกำหนดเองโดยผู้ใช้ ทั้งนี้ สิ่งที่ต้องระบุให้ Agent ได้แก่- Tools: เครื่องมือในการทำ Action ต่าง ๆ รวมไปถึงการเข้าถึงทรัพยากรภายนอก อาทิ การค้นหาเว็บไซต์ การรันคำสั่งเพื่อวิเคราะห์ขั้นสูง การส่งอีเมล์ และการเข้าถึง API ภายนอก
- User Input: วัตถุประสงค์ของผู้ใช้ อาทิ การคำค้นหาคำที่ต้องการ หรือการสรุปความเอกสาร
- Intermediate Steps: ประวัติการดำเนินการของ Agents ก่อนหน้า ที่เกี่ยวข้องกับการทำงานของ Agents ในปัจจุบัน
- Chains
การร้อยเรียงส่วนประกอบต่าง ๆ เข้าด้วยกันใน LangChain ไม่ว่าจะเป็น LLM หรือ Tools ต่าง ๆ รวมถึงเครื่องมือสำหรับการจัดการข้อมูล จะใช้สิ่งที่เรียกว่า Chains ในการกำหนดลำดับการเรียกใช้ส่วนประกอบที่กล่าวมาข้างต้น โดยผู้ใช้สามารถสร้าง Chains ได้ 2 วิธี ดังนี้- การใช้งาน The LangChain Expression Language (LCEL) ซึ่งเป็นรูปแบบของคำสั่งเฉพาะใน LangChain สำหรับการสร้างและจัดการ Chains ได้โดยง่าย ซึ่งรองรับการทำงานชั้นสูง เช่น การทำงานแบบขนาน การสร้างทางเลือกสำรอง และการดำเนินการซ้ำในกรณีที่มีข้อผิดพลาด
- การสร้าง Chains แบบดั้งเดิมด้วยคลาสที่ชื่อว่า “Chain” ในไลบรารี่ โดยไม่ต้องอาศัย LCEL
- Memory
หน่วยความจำเป็นส่วนสำคัญของการพัฒนาแอปพลิเคชัน LLM เนื่องจากประวัติบทสนทนาในอดีตสามารถใช้ในการอ้างอิงเพื่อการตัดสินใจในปัจจุบันได้ ดังนั้น LangChain จึงนำเสนอโมดูล Memory เพื่อใช้จัดการในส่วนนี้ โดยเมื่อผู้ใช้ดำเนินการบน Chains จะมีสิ่งที่เกิดขึ้นกับ Memory 2 ประการ ได้แก่- หลังจากที่ผู้ใช้แอปพลิเคชันป้อนข้อความ (Input Text) เข้ามา ระบบจะยังไม่นำข้อความนั้นไปดำเนินการต่อทันที แต่จะมีการไป “อ่าน” ประวัติข้อความที่คล้ายคลึงกันใน Memory เพื่อนำมาใช้ในการขยายความของข้อความข้างต้น
- หลังจากที่มีการดำเนินการกับข้อความที่ถูกขยายความมาแล้ว ระบบจะทำการ “เขียน” ข้อความดังกล่าว กับผลลัพธ์ที่ได้ ลงใน Memory
- Callbacks
สุดท้ายนี้ ใน LangChain ยังมีโมดูล Callbacks สำหรับอำนวยความสะดวกในการเชื่อมต่อกับแต่ละขั้นตอนในแอปพลิเคชันที่สร้างขึ้น เพื่อบันทึกการทำงาน ตรวจสอบสถานะต่าง ๆ รวมถึงดำเนินงานอื่น ๆ ได้อย่างง่ายดาย
บทส่งท้าย
ปฏิเสธไม่ได้ว่า ในปัจจุบัน AI ได้เข้ามามีบทบาทสำคัญในชีวิตประจำวันของเรามากขึ้นเรื่อย ๆ โดยเฉพาะอย่างยิ่งการประยุกต์ใช้ LLM ในงานด้านต่าง ๆ ที่เกี่ยวข้องกับข้อมูลทางภาษา ซึ่งเป็นหนึ่งในชนิดของข้อมูลที่มีอยู่เป็นปริมาณมหาศาลบนโลก ดังนั้น ถ้าองค์กรใดสามารถนำพลังของ AI ดังกล่าวมาต่อยอดได้อย่างมีประสิทธิภาพก่อนนั้นย่อมได้เปรียบกว่าอย่างแน่นอน อย่างไรก็ตาม ด้วยความต้องการความเชี่ยวชาญของนักพัฒนาในหลากหลายแขนงในการสร้างแอปพลิเคชันจาก LLM ทำให้เกิดข้อจำกัดของการทำงานดังกล่าวในองค์กรขนาดเล็ก แต่ทว่าการมีอยู่ของเฟรมเวิร์ค “LangChain” จะเข้ามาอุดรอยรั่วในส่วนนี้ได้ ทำให้การพัฒนาแอปพลิเคชันที่ขับเคลื่อนด้วย LLM นั้นเป็นเรื่องที่ง่ายกว่าเดิม ทั้งนี้ ในบทความนี้เพียงแค่เป็นการกล่าวถึงที่มาและความสำคัญ รวมถึงแนวคิดเบื้องต้นของ LangChain เท่านั้น ซึ่งในโอกาสหน้าผู้เขียนจะพาผู้อ่านไปทำความเข้าใจ LangChain ให้มากยิ่งขึ้น ผ่านการใช้งานจริง
บทความโดย อาทิตย์ สกุลเมือง
ตรวจทานและปรับปรุงโดย ปริสุทธิ์ จิตต์ภักดี
เอกสารเพิ่มเติม
- Langchain’s official document: https://python.langchain.com/docs/
- LangChain Explained in 13 Minutes | QuickStart Tutorial for Beginners: https://www.youtube.com/watch?v=aywZrzNaKjs&t
- LangChain 101: The Complete Beginner's Guide: https://www.youtube.com/watch?v=P3MAbZ2eMUI&t
- A Complete LangChain Guide: https://nanonets.com/blog/langchain/#installation-and-setup
- A brief guide to LangChain for software developers: https://www.infoworld.com/article/3705097/a-brief-guide-to-langchain-for-software-developers.html



Data Management Training and Development Manager at Big Data Institute (Public Organization), BDI