
วันนี้ เราจะมาทำความรู้จักกับกลไกสำหรับการปกป้องความลับของข้อมูลส่วนบุคคลด้วย Differential Privacy
โดยหลักการของ differential privacy คือการเพิ่มสิ่งรบกวนทางคณิตศาสตร์ (noise) เข้าไปในข้อมูลเพื่อไม่ให้สามารถบ่งชี้ตัวตนของบุคคลได้ ซึ่งวิธีที่ง่ายที่สุดในการปกป้องความเป็นส่วนบุคคล คือการละเว้นข้อมูลทั้งหมดที่สามารถนำไปประกอบชี้ตัวตนบุคคลได้ เช่น ชื่อ นามสกุล อายุ เพศ วันเดือนปีเกิด ฯลฯ แต่โดยส่วนใหญ่แล้ว วิธีดังกล่าวจะทำให้เสียข้อมูลและอาจจะทำให้ไม่สามารถนำชุดข้อมูลไปใช้ต่อได้เลย
ซึ่งเคล็ดลับของ differential privacy คือการเพิ่ม noise ด้วยหลักการทางคณิตศาสตร์
โดยสามารถชี้วัดได้ว่า
- ข้อมูลตัวตนบุคคลยังคงเป็นความลับอยู่มากเท่าไร
- ข้อมูลยังมีคุณสมบัติเดิมอยู่มากเท่าไร และ
- ผลการวิเคราะห์ยังคงมีความถูกต้องอยู่มากเท่าไร
การประกาศผลสถิติสามารถเปิดเผยข้อมูลส่วนบุคคลได้
คุณเคยคิดบ้างไหมว่า การประกาศผลสถิติไม่ได้เปิดเผยข้อมูลส่วนบุคคลใด ๆ
แต่ในความเป็นจริง ใคร ๆ หรือสาธารณะอาจจะรู้มากกว่าที่คุณคิดได้ ในบทความนี้ เราจะมาทำความเข้าใจกันว่า เราจะต้องทำอย่างไร เพื่อไม่ให้การประกาศผลการวิเคราะห์ใด ๆ เปิดเผยข้อมูลส่วนบุคคลในชุดข้อมูลของเรา
เรามาดูตัวอย่างง่ายๆ กันครับ สมมุติว่าเรามีชุดข้อมูลน้ำหนักของผู้ป่วยจากข้อมูลประวัติการรักษาพยาบาลในตารางที่ 1 ด้านล่าง และเราได้ทำการวิเคราะห์สุขภาพประชาชนไทยโดยคำนวนค่าเฉลี่ยน้ำหนัก และประกาศผลให้เป็นข้อมูลสาธารณะ
| ชื่อ | น้ำหนัก |
|---|---|
| Anand | 60 |
| Ben | 70 |
| Champ | 80 |
| Dao | 40 |
ค่าเฉลี่ยน้ำหนัก : 62.5
โดยข้อมูลในตารางถือว่าเป็นข้อมูลส่วนบุคคล และค่าเฉลี่ยน้ำหนักเป็นข้อมูลสาธารณะ ถ้าคุณ Anand Ben และคุณ Champ เปิดเผยข้อมูลตนเอง เราสามารถคำนวนน้ำหนักของคุณ Dao ( ) จากค่าเฉลี่ยได้ โดย
) จากค่าเฉลี่ยได้ โดย

ทั้งนี้ คุณ Dao ไม่ได้ยินยอมหรือมีความประสงค์ที่จะเปิดเผยข้อมูลส่วนตัวของตนเองให้เป็นสาธารณะ ดังนั้น การประกาศค่าเฉลี่่ยน้ำหนักในครั้งนี้ จึงเป็นการละเมิดความลับข้อมูลส่วนบุคคลของคุณ Dao
เราอยากที่จะประกาศผลการวิเคราะห์หรือค่าเฉลี่ยโดยที่สาธารณะไม่สามารถทราบน้ำหนักของคุณ Dao ได้ แม้กระทั่งมีการเปิดเผยข้อมูลใด ๆ เพราะฉะนั้น สาธารณะจะไม่สามารถแยกตารางชุดข้อมูลจริงออกจากตารางชุดข้อมูลปลอมได้ เช่น ถ้าค่าเฉลี่ยน้ำหนักที่เราประกาศคือ 63.75 และมีชุดข้อมูลในตารางที่ 2 ซึ่งแตกต่างจากตารางที่ 1 ที่ค่าน้ำหนักของคุณ Dao จุดเดียว
| ชื่อ | น้ำหนัก |
|---|---|
| Anand | 60 |
| Ben | 70 |
| Champ | 80 |
| Dao | 50 |
สาธารณะจะไม่สามารถทราบได้ว่า ค่าเฉลี่ยดังกล่าวเป็นของตารางที่ 1 หรือ 2 เพราะค่าเฉลี่ยที่ประกาศจะไม่ตรงกับค่าเฉลี่ยที่คำนวนได้จากทั้งสองตาราง เราจึงเรียกสองตารางที่แตกต่างจากกันเพียงค่าเดียวว่า Neighbors ซึ่งเป็นคุณสมบัติสำคัญของตารางชุดข้อมูลสำหรับการนิยามของ differential privacy
เราจะเห็นได้ว่าค่าน้ำหนักเฉลี่ย 63.75 ขาดความถูกต้อง เพราะค่าดังกล่าว ไม่ตรงกับค่าเฉลี่ยที่สามารถคำนวนได้จากทั้ง 2 ตาราง โดยการประกาศค่าเฉลี่ยน้ำหนักเป็น 63 จะทำให้ผลการวิเคราะห์มีความถูกต้องมากขึ้นหากข้อมูลจริงคือข้อมูลในตารางที่ 1 เพราะค่าเฉลี่ยที่ประกาศไปใกล้เคียงกับค่าเฉลี่ยของตารางที่ 1 มากกว่าตารางที่ 2 แต่ในขณะเดียวกัน สาธารณะจะมีความมั่นใจมากขึ้นว่า น้ำหนักของคุณ Dao ใกล้ 40 มากกว่า 50 ดังนั้น การคุ้มครองและปกป้องข้อมูลส่วนบุคคลในกรณีนี้ จึงมี tradeoff ระหว่างความถูกต้องของผลการวิเคราะห์และความลับของข้อมูลส่วนบุคคล
Differential Privacy และ Laplace Mechanism
เป้าหมายของการทำ differential privacy คือการทำให้สาธารณะไม่สามารถแยกตารางใด ๆ ก็ตามที่เป็น neighbors ออกจากกันได้ โดยหลักการในทางคณิตศาสตร์คือการเพิ่ม noise เข้าไปในผลการวิเคราะห์ ( )
)
(1) 
โดย  คือน้ำหนักของแต่ละบุคคล และ
คือน้ำหนักของแต่ละบุคคล และ  คือจำนวนบุคคลทั้งหมด
คือจำนวนบุคคลทั้งหมด
การเลือก มีอยู่หลายวิธี วิธีพื้นฐานสำหรับค่าที่เป็นตัวเลขคือ Laplace mechanism
Laplace mechanism คือการสุ่มค่า noise จาก Laplacian distribution ซึ่งมีลักษณะต่อไปนี้
(2) 
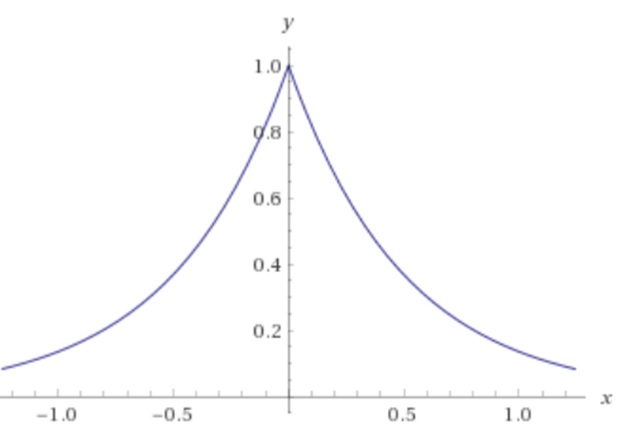
ตัวอย่างของ Laplace distribution จะอยู่ในรูปที่ 1

โดยปกติในการสุ่มค่า noise เราจะเลือก  ให้เท่ากับ 0 เมื่อ เท่ากับ 0 ค่าคาดหมายจึงเท่ากับ 0 และค่าความแปรปรวนจึงเท่ากับ
ให้เท่ากับ 0 เมื่อ เท่ากับ 0 ค่าคาดหมายจึงเท่ากับ 0 และค่าความแปรปรวนจึงเท่ากับ  เพราะฉะนั้น ถ้าค่าของ
เพราะฉะนั้น ถ้าค่าของ  ยิ่งสูง โอกาสที่เราจะดึงค่าที่ใหญ่สำหรับค่าของ noise ก็จะสูงขึ้นด้วย
ยิ่งสูง โอกาสที่เราจะดึงค่าที่ใหญ่สำหรับค่าของ noise ก็จะสูงขึ้นด้วย
เราสามารถนิยามตัวชี้วัด differential privacy และหา bound ของ noise ได้ โดยเราจำเป็นจะต้องนิยามความแตกต่างในผลการวิเคราะห์สถิติที่มากที่สุดจากบรรดาสองตารางที่เป็น neighbors ทั้งหมดก่อน
(3) 
โดย  คือผลการวิเคราะห์สถิติ ซึ่งคือค่าเฉลี่ยน้ำหนักในตัวอย่างที่กล่าวไว้เบื่องต้น
คือผลการวิเคราะห์สถิติ ซึ่งคือค่าเฉลี่ยน้ำหนักในตัวอย่างที่กล่าวไว้เบื่องต้น  และ
และ  คือตารางที่เป็น neighbors
คือตารางที่เป็น neighbors
เมื่อเรารวมทั้งสามสมการด้านบน เราจะได้สมการสำหรับการหา noise ด้วย Laplace mechanism ผลการวิเคราะห์สถิติที่เราประกาศให้สาธารณะ ( ) สำหรับตารางที่เราสนใจจึงมีรูปแบบในสามการ (4)
) สำหรับตารางที่เราสนใจจึงมีรูปแบบในสามการ (4)
(4) ![\begin{equation*}y = f\left ( T \right ) + Lap\left [ \frac{GS\left ( f \right )}{\varepsilon } \right ]\end{equation*}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-703c61b245758b98b703989a14dc07f6_l3.svg "Rendered by QuickLaTeX.com")
โดย  เป็นตัวแปรที่มีค่าระหว่าง 0 กับ 1 จากสมการ (4) เมื่อค่าของ ใกล้ 1 การแจกแจงของค่า noise จะยิ่งแคบ (รูปที่ 2) และทำให้โอกาสที่จะสุ่มค่า noise ที่เล็กมากขึ้น ในทางกลับกัน ถ้าค่าของ ใกล้ 0 การแจกแจงของค่า noise จะยิ่งกว้าง (รูปที่ 3) และทำให้มีโอกาสมากขึ้นที่ค่า noise ใหญ่
เป็นตัวแปรที่มีค่าระหว่าง 0 กับ 1 จากสมการ (4) เมื่อค่าของ ใกล้ 1 การแจกแจงของค่า noise จะยิ่งแคบ (รูปที่ 2) และทำให้โอกาสที่จะสุ่มค่า noise ที่เล็กมากขึ้น ในทางกลับกัน ถ้าค่าของ ใกล้ 0 การแจกแจงของค่า noise จะยิ่งกว้าง (รูปที่ 3) และทำให้มีโอกาสมากขึ้นที่ค่า noise ใหญ่
 ใหญ่
ใหญ่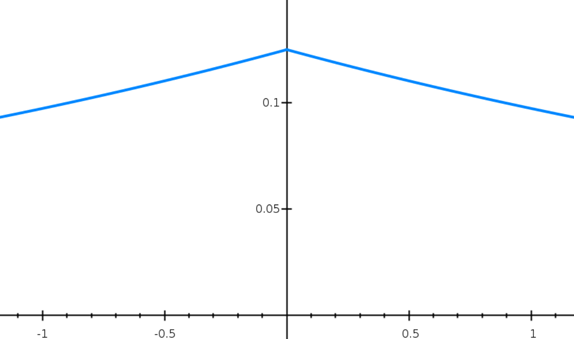 เล็ก
เล็กโดยทั่วไป ผู้ใหญ่จะหนักระหว่าง 30 และ 150 กิโลกรัม ซึ่งความแตกต่างที่มากที่สุดในสองตารางที่เป็น neighbors จึงเท่ากับ 150 – 30 หรือ 120 กิโลกรัมโดยประมาณ เพราะฉะนั้น ความแตกต่างในผลการวิเคราะห์สถิติ (ค่าเฉลี่ย) ที่มากที่สุด จึงเท่ากับ  จากตัวอย่างชุดข้อมูลที่มีอยู่ 4 คน ดังนั้น ด้วยค่าของ ที่เท่ากับ 0.1 noise จะถูกสุ่มมาจาก
จากตัวอย่างชุดข้อมูลที่มีอยู่ 4 คน ดังนั้น ด้วยค่าของ ที่เท่ากับ 0.1 noise จะถูกสุ่มมาจาก ![Lap\left [ \frac{30}{0.1} \right ] = Lap\left [ 300 \right ]](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-e9250e745d02ddc18b31259a34d56233_l3.svg "Rendered by QuickLaTeX.com") ซึ่งมีลักษณะในรูปที่ 4 ค่าของ noise จึงมีโอกาสที่จะใหญ่มากและทำให้ผลวิเคราะห์ผิดไปจากความเป็นจริงมาก แต่เมื่อชุดข้อมูลเป็น big data และมีข้อมูลของคนจำนวนมาก ค่าของ noise จะเล็กลง โดยถ้าเรามีข้อมูลน้ำหนัก 1,000 คน ค่าของ noise จะถูกสุ่มมาจาก
ซึ่งมีลักษณะในรูปที่ 4 ค่าของ noise จึงมีโอกาสที่จะใหญ่มากและทำให้ผลวิเคราะห์ผิดไปจากความเป็นจริงมาก แต่เมื่อชุดข้อมูลเป็น big data และมีข้อมูลของคนจำนวนมาก ค่าของ noise จะเล็กลง โดยถ้าเรามีข้อมูลน้ำหนัก 1,000 คน ค่าของ noise จะถูกสุ่มมาจาก ![Lap\left [ \frac{\frac{120}{1000}}{0.1}\right ] = Lap\left [ 1.2 \right ]](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-56667ac575db86285742f777cb40ac31_l3.svg "Rendered by QuickLaTeX.com") ซึ่งมีลักษณะในรูปที่ 5
ซึ่งมีลักษณะในรูปที่ 5
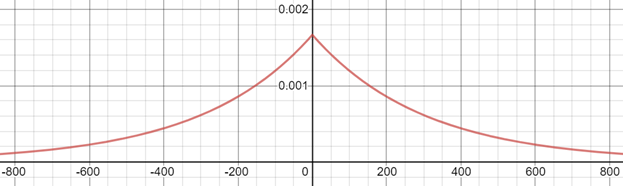
![Lap\left [ 300 \right ] =\frac{1}{600}e^{-\frac{|x|}{300}}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-6f3308129f41837fe538633c2c946d43_l3.svg "Rendered by QuickLaTeX.com")
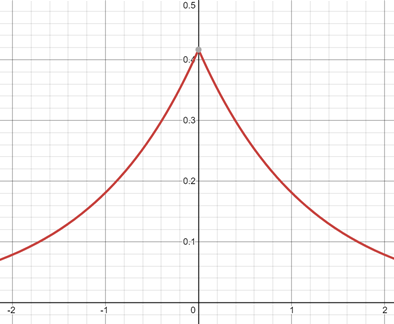
![Lap\left [ 1.2 \right ] = \frac{1}{2.4}e^{-\frac{|x|}{1.2}}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-b47f139944118705cb85a3b1af756358_l3.svg "Rendered by QuickLaTeX.com")
เราสามารถหา bound ของ noise จาก Laplace mechanism โดยการอ้างอิง Chebyshev’s Inequality ซึ่งจำกัดโอกาสและความห่างของค่าสุ่มจากค่าคาดหมาย
(5) ![\begin{equation*}\textup{Pr}\left [|\mathbf{X} - E\left [ \mathbf{X} \right ]| \geq \ksigma \right ]\leq \frac{1}{k^2}\end{equation*}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-c2db36b56899a812cbe302b2bfe09e6e_l3.svg "Rendered by QuickLaTeX.com")
โดย  คือค่าสุ่ม และ
คือค่าสุ่ม และ  คือค่าเบี่ยงเบนมาตรฐาน สำหรับตัวอย่างข้อมูลน้ำหนัก 1,000 คน ซึ่งค่าคาดหมายของ noise เท่ากับ 0 และค่าเบี่ยงเบนมาตรฐานสามารถคำนวณจากรากที่สองของค่าความแปรปรวนซึ่งเท่ากับ
คือค่าเบี่ยงเบนมาตรฐาน สำหรับตัวอย่างข้อมูลน้ำหนัก 1,000 คน ซึ่งค่าคาดหมายของ noise เท่ากับ 0 และค่าเบี่ยงเบนมาตรฐานสามารถคำนวณจากรากที่สองของค่าความแปรปรวนซึ่งเท่ากับ  ดังนั้น โอกาสที่ค่า noise น้อยกว่า 3.4 (2 เท่าของค่าเบี่ยงเบนมาตรฐาน หรือ
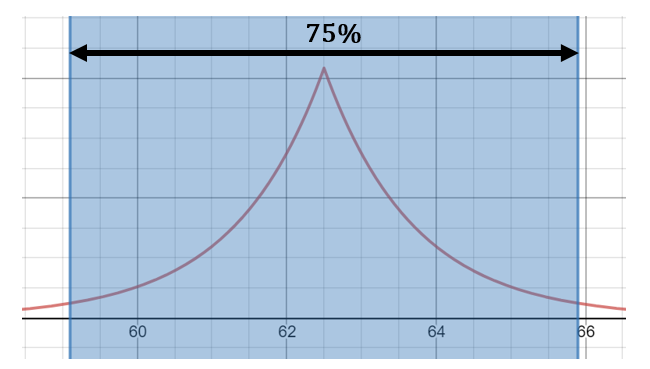
ดังนั้น โอกาสที่ค่า noise น้อยกว่า 3.4 (2 เท่าของค่าเบี่ยงเบนมาตรฐาน หรือ  ) จึงมากกว่าหรือเท่ากับ 75% ซึ่งถ้าค่าเฉลี่ยน้ำหนักเท่ากับ 62.5 กิโลกรัม ค่าเฉลี่ยที่ประกาศจะมีค่าระหว่าง 59.1 และ 65.9 กิโลกรัม ด้วยโอกาส 75%
) จึงมากกว่าหรือเท่ากับ 75% ซึ่งถ้าค่าเฉลี่ยน้ำหนักเท่ากับ 62.5 กิโลกรัม ค่าเฉลี่ยที่ประกาศจะมีค่าระหว่าง 59.1 และ 65.9 กิโลกรัม ด้วยโอกาส 75%
ทั้งนี้ เราสามารถนิยาม – differential privacy และพิสูจน์ว่า Laplace mechanism มีความเป็น – differential private ซึ่งคือคุณสมบัติ
(6) ![\begin{equation*}e^{-\varepsilon}\leq \frac{\textup{Pr}\left [ out\left ( T \right ) = y \right ]}{\textup{Pr}\left [ out\left ( T' \right ) = y \right ]}\leq e^\varepsilon\end{equation*}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-f518c402e2c6251badb54ebb447cba70_l3.svg "Rendered by QuickLaTeX.com")
โดย คือค่าสุ่มที่เป็นไปได้ทั้งหมด และ คือสองตารางที่เป็น neighbors และ  คือผลที่ได้จากกระบวนการทำ differential privacy ซึ่งสามารถตีความสมการ (6) ได้ว่า การเดาว่าผลการวิเคราะห์ มาจากตาราง หรือ เป็นสิ่งที่ยาก
คือผลที่ได้จากกระบวนการทำ differential privacy ซึ่งสามารถตีความสมการ (6) ได้ว่า การเดาว่าผลการวิเคราะห์ มาจากตาราง หรือ เป็นสิ่งที่ยาก
จากค่า ค่าของ noise จึงเท่ากับ  ด้วยความน่าเป็นไปได้
ด้วยความน่าเป็นไปได้  โดย
โดย  เราจึงสามารถเขียน
เราจึงสามารถเขียน
![\textup{Pr} \left [ out\left ( T \right ) = y \right ] = \frac{\varepsilon} {2GS\left ( f \right ) }e^{-\varepsilon \frac{|y-f\left ( T \right )|}{GS\left ( f \right )}}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-f8abb77b90913277445ec4d34748e31b_l3.svg "Rendered by QuickLaTeX.com")
และ
![\textup{Pr} \left [ out\left ( T' \right ) = y \right ] = \frac{\varepsilon} {2GS\left ( f \right ) }e^{-\varepsilon \frac{|y-f\left ( T' \right )|}{GS\left ( f \right )}}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-4fe04aa23a6d3fd17fe274c348180e55_l3.svg "Rendered by QuickLaTeX.com")
เพราะฉะนั้น
![\begin{align*}\frac{\textup{Pr} \left [ out\left ( T \right ) = y \right ]}{\textup{Pr} \left [ out\left ( T' \right )= y \right ]} &= \frac{\frac{\varepsilon} {2GS\left ( f \right ) }e^{-\varepsilon \frac{|y-f\left ( T \right )|}{GS\left ( f \right )}}}{\frac{\varepsilon} {2GS\left ( f \right ) }e^{-\varepsilon \frac{|y-f\left ( T' \right )|}{GS\left ( f \right )}}}\\&= \frac{\cancel{\frac{\varepsilon} {2GS\left ( f \right )} }e^{-\varepsilon \frac{|y-f\left ( T \right )|}{GS\left ( f \right )}}}{\cancel{\frac{\varepsilon} {2GS\left ( f \right ) }}e^{-\varepsilon \frac{|y-f\left ( T' \right )|}{GS\left ( f \right )}}}\\&= e^{-\varepsilon \frac{|y-f\left ( T \right )|} {GS \left ( f \right )} + \varepsilon \frac{|y-f\left ( T' \right )|} {GS \left ( f \right )} }\\&= e^{\frac{\varepsilon}{GS\left ( f \right )}\left ( -|y-f\left ( T \right )| + |y - f\left ( T' \right )| \right )}\end{align*}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-b751f175ae36cb443e2d00b39ff5e6c6_l3.svg "Rendered by QuickLaTeX.com")
ด้วย Reverse Triangle Inequality

เราจึงได้
![\begin{align*}\frac{\textup{Pr} \left [ out\left ( T \right ) = y \right ]}{\textup{Pr} \left [ out\left ( T' \right )= y \right ]} &= e^{\frac{\varepsilon}{GS\left ( f \right )}\left ( |y - f\left ( T' \right )| -|y-f\left ( T \right )| \right ) }\\&\leq e^{\frac{\varepsilon}{GS\left ( f \right )}\left ( |\cancel{y} - f\left ( T' \right ) \cancel{-y}+f\left ( T \right )| \right ) }\\&= e^{\frac{\varepsilon}{GS\left ( f \right )}\left ( f\left ( T \right ) - f\left ( T' \right )| \right ) }\end{align*}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-296e492a467e276bce60ee3737b17341_l3.svg "Rendered by QuickLaTeX.com")
และจากนิยามในสมการ (3)

ดังนั้น
![\begin{align*}\frac{\textup{Pr} \left [ out\left ( T \right ) = y \right ]}{\textup{Pr} \left [ out\left ( T' \right ) = y \right ]} &\leq e^{\frac{\varepsilon}{\cancel{GS\left ( f \right )}}\cancel{GS\left ( f \right )}}\\\frac{\textup{Pr} \left [ out\left ( T \right ) = y \right ]}{\textup{Pr} \left [ out\left ( T' \right )= y \right ]} &\leq e^\varepsilon\end{align*}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-1197d2fe18590394ddc612c2d97fcf9c_l3.svg "Rendered by QuickLaTeX.com")
ด้วยวิธีพิสูจน์เดียวกัน
![\frac{\textup{Pr} \left [ out\left ( T \right ) = y \right ]}{\textup{Pr} \left [ out\left ( T' \right )= y \right ]} \geq e^{-\varepsilon}](https://bdi.or.th/wp-content/ql-cache/quicklatex.com-c07a66652b591ae9fdaffe98dea76892_l3.svg "Rendered by QuickLaTeX.com")

Laplace mechanism จึงมีความเป็น – differential private
ข้อสรุป
ค่าของ ในสมการ (6) จึงเป็นตัวชี้วัด differential privacy ที่
- วัดความยากในการนำข้อมูลผลการวิเคราะห์สถิติไปชี้ตัวตนบุคคล
- วัดความแตกต่างของข้อมูลจากข้อมูลเดิม และ
- วัดความถูกต้องของการวิเคราะห์
การเลือกค่า ε ที่ใหญ่จะทำให้ผลการวิเคราะห์มีความถูกต้องมากขึ้น แต่ในขณะเดียวกัน จะทำให้การชี้ตัวตนบุคคลได้ง่ายขึ้นด้วย ดังนั้นการเลือกค่าของ ε จึงต้องมีการประเมินความเสี่ยง ในมุมมองของข้อมูล big data การเพิ่ม noise ด้วยค่าของ ε ที่ต่ำโดยปกติ จะมีผลกระทบต่อความถูกต้องของผลการวิเคราะห์น้อยเพราะข้อมูลมีปริมาณเยอะ เราจึงสามารถใช้ประโยชน์ของ differential privacy ได้อย่างมากเลยทีเดียวครับ
แหล่งที่มาของข้อมูล
C. Dwork and A. Roth. The Algorithmic Foundations of Differential Privacy, Foundation and Trends in Theoretical Computer Science, Vol. 9, Nos. 3-4, pages 211-407, 2014.
V. Suppakitpaisarn. Differential Privacy: Definitions, Laplace Mechanism, Algorithms for Information Security and Privacy, 2018.
อ่านต่อเกี่ยวกับการปกป้องข้อมูลส่วนบุคคลด้วย การพัฒนา AI ด้วยข้อมูลส่วนบุคคล โดยหลักการของ Federated Learning
เนื้อหาโดย เบญจ์ รักตันติโชค
ปรับปรุงและแก้ไขโดย ภคภูมิ สารพัฒน์ และ ปพจน์ ธรรมเจริญพร
Vice President Research and Innovations Division (RIN)
Big Data Institute (Public Organization), BDI







Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )






