
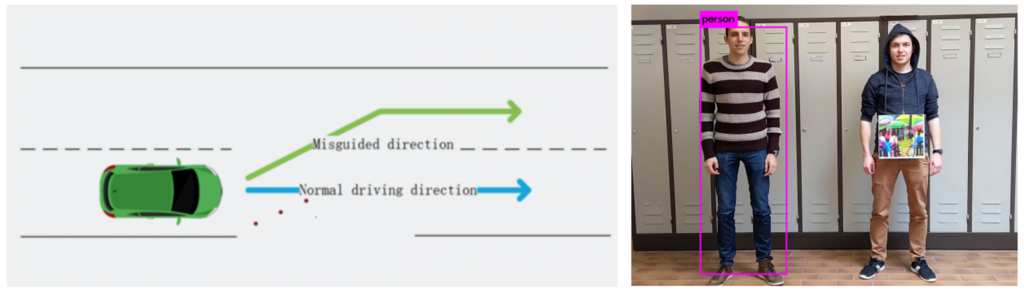
ความปลอดภัยของการเรียนรู้ของเครื่อง (Machine Learning Security) เป็นหลักการป้องกันการโจมตีแบบจำลองการเรียนรู้ของเครื่อง (Machine Learning Model) ระหว่างที่ถูกนำไปใช้งานจริง จากผู้ไม่หวังดีที่ต้องการใช้ประโยชน์จากการแก้ไขหรือหลอกล่อแบบจำลองให้ทำนายผลลัพธ์ให้เป็นไปตามที่ผู้ไม่หวังดีต้องการ เช่น กลุ่มนักวิจัยสามารถหลอกระบบ Autopilot ของรถยนต์ Tesla ให้เลี้ยวผิดเลนด้วยการติดสติกเกอร์บนถนน [1] หรือการแขวนภาพวาดเพื่อให้เครื่องตัวจับคนทำงานผิดพลาด [2] เป็นต้น
สำหรับเนื้อหาความปลอดภัยของการเรียนรู้ของเครื่องเป็นส่วนหนึ่งของหัวข้อการเรียนรู้ของเครื่องอย่างมีความรับผิดชอบ (Responsible Machine Learning) ที่เน้นศึกษาอันตรายและความเสี่ยงที่อาจเกิดขึ้นการใช้งานของแบบจำลองการเรียนรู้ของเครื่อง ตลอดจนแนวทางการปฏิบัติเพื่อช่วยความพร้อมในการรับมือกับความเสี่ยงดังกล่าวได้อย่างมีประสิทธิภาพ
องค์ประกอบของมาตรฐานความปลอดภัย
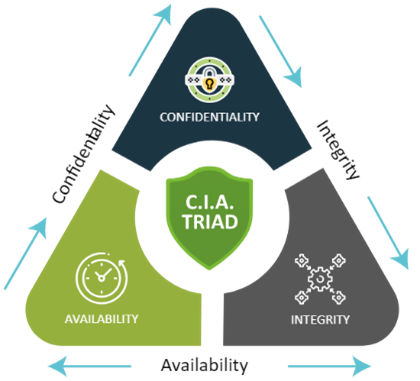
หลักการ C-I-A เป็นทฤษฎีเบื้องต้นของความมั่นคงและปลอดภัยทางไซเบอร์ (Cyber Security) โดยมีเป้าหมายหลักในการวางโครงสร้างด้านความปลอดภัยข้อมูล ดังนี้
- Confidentiality: การที่ข้อมูลและแบบจำลองการเรียนรู้ของเครื่องจะต้องเข้าถึงได้โดยผู้ที่มีสิทธิเท่านั้น ถ้าไม่อย่างนั้นแล้ว ข้อมูลและแบบจำลองอาจถูกเปิดเผย (Disclosure)
- Integrity การที่ข้อมูลและแบบจำลองการเรียนรู้ของเครื่องมีความถูกต้องและถูกแก้ไขโดยผู้ที่มีสิทธิเท่านั้น ถ้าไม่อย่างนั้นแล้ว ข้อมูลและแบบจำลองอาจถูกดัดแปลง (Alterations)
- Availability การที่ข้อมูลและโมเดลการเรียนรู้ของเครื่องพร้อมใช้งานตลอดเวลา ถ้าไม่อย่างนั้นแล้ว ข้อมูลและแบบจำลองอาจถูกทำลาย (Destruction)
บทความนี้ ผู้เขียนขอยกตัวอย่างการโจมตีที่เป็นไปได้ทั้งหมด 4 รูปแบบ โดยที่ผู้ไม่หวังดีมีเป้าหมายในการพยายามทำให้แบบจำลองการเรียนรู้ทำนาย “อนุมัติ” (deny = 0) แทนที่ควรจะต้องทำนาย “ปฏิเสธ” (deny = 1) ซึ่งผู้เขียนเรียบเรียงมาจากวิชา Introduction to Responsible Machine Learning จาก George Washington University, USA (ที่นี่)
รูปแบบการโจมตี 1: การโจมตีด้วยข้อมูลพิษ (Data Poisoning Attacks)
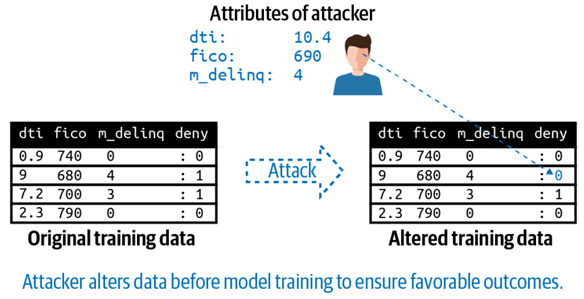
ผู้ไม่หวังดีเข้าถึงข้อมูลที่ใช้ฝึกฝนแบบจำลองและทำการแก้ไขข้อมูลดังกล่าว ซึ่งการโจมตีดังกล่าวเกิดได้จากการที่ผู้ไม่หวังดีเจาะระบบแล้วสวมรอยเป็นนักวิทยาศาสตร์ข้อมูลหรือผู้ที่มีสิทธิ์เข้าถึงข้อมูลดังกล่าว จากนั้นจึงทำการแก้ไขข้อมูลก่อนที่จะถูกนำไปฝึกฝนและพัฒนาแบบจำลอง ทำให้แบบจำลองทำนายผลลัพธ์เอนเอียงไปในทางที่ต้องการ จากตัวอย่าง ผู้ไม่หวังดีทำการเปลี่ยนคำตอบของคุณสมบัติที่ใกล้เคียงกับผู้ไม่หวังดีจาก “ปฏิเสธ” ให้เป็น “อนุมัติ” ทำให้เมื่อแบบจำลองดังกล่าวถูกนำไปใช้งานจริง แบบจำลองจะทำนายให้ “อนุมัติ” ให้กับผู้ไม่หวังดี เช่น การโจมตีโมเดลประเมินความเสี่ยงในการให้สินเชื่อ เป็นต้น
แนวทางการป้องกัน
- กำหนดสิทธิการเข้าถึงข้อมูล (Role-Based Access Control) เพื่อการควบคุมการเข้าถึงข้อมูลสำคัญ เป็นการป้องกันในกรณีที่ถูกสวมรอยและสามารถจำกัดความเสียหายของข้อมูลและแบบจำลองทั้งหมด
- ตรวจสอบการทำงานของแบบจำลองว่ามีการเรียนรู้ที่เที่ยงตรง ไม่ทำนายเอนเอียงไปยังคุณสมบัติใดคุณสมบัติหนึ่ง ผ่านเครื่องมือตรวจสอบอคติ เช่น Aequitas และ AIF360 เป็นต้น
- การวิเคราะห์ความคลาดเคลื่อนของตัวอย่าง (Residual Analysis) โดยสังเกตคุณสมบัติของกลุ่มข้อมูลที่ได้รับประโยชน์จากการทำนายของแบบจำลอง ว่ามีการกระจายตัวที่ผิดปกติหรือไม่
- การเทียบผลจากแบบจำลองเทียบกับการทำนายโดยผู้เชี่ยวชาญ (Self-reflection) เพื่อตรวจสอบผลทำนายว่า ผิดแปลกไปจากความเป็นจริงหรือไม่
รูปแบบการโจมตี 2: การโจมตีประตูหลังและลายน้ำ (Backdoors and Watermarks)
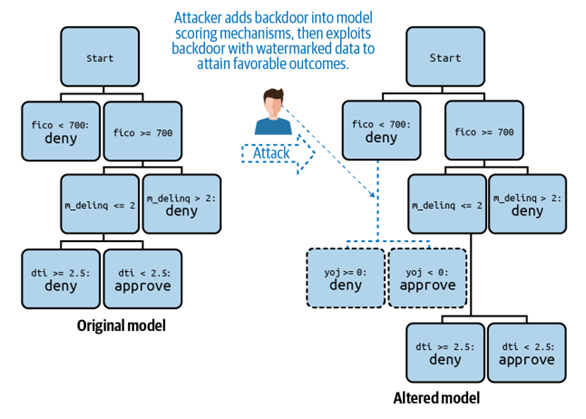
ผู้ไม่หวังดีเข้าถึงโค้ดแบบจำลองที่ถูกใช้งานจริงและสามารถแก้ไขโค้ดดังกล่าวได้ ซึ่งการโจมตีดังกล่าวเกิดได้จากการที่ผู้ไม่หวังดีเจาะระบบแล้วสวมรอยเป็นนักวิทยาศาสตร์ข้อมูลหรือผู้ที่มีสิทธิ์เข้าถึงข้อมูลโค้ดแบบจำลองที่ถูกใช้งาน จากตัวอย่าง ผู้ไม่หวังดีเพิ่มเงื่อนไขพิเศษเข้าไปยังแบบจำลองต้นไม้ตัดสินใจ (Decision Tree) ทำให้แบบจำลองทำนายผลจาก “ปฏิเสธ” เป็น “อนุมัติ” ได้หาก ค่า “yoj” ต่ำกว่า 0
แนวทางการป้องกัน
- ตรวจสอบการเข้ามาที่ผิดปกติของข้อมูล (Anomaly Detection) เพื่อเช็คว่า แบบจำลองได้รับค่าตัวแปรของข้อมูลตัวใดผิดแปลกไปกว่าที่ควรจะเป็นหรือไม่
- จัดทำระบบจัดเก็บการเปลี่ยนแปลง (Version Control) เพื่อบันทึกว่า แบบจำลองที่ใช้งานอยู่ถูกแก้ไขโดยใคร ในช่วงเวลาไหนบ้าง เพื่อใช้ตรวจสอบว่า การแก้ไขมาจากบุคคลที่มีสิทธิ์ในการเข้าถึงเท่านั้น
- การจัดทำเอกสารของแต่ละแบบจำลอง (Documentation) เพื่อบันทึกว่า ข้อมูลที่เกี่ยวข้อง รูปแบบการทำนายผล และสิ่งที่ต้องพึงระวังของแต่ละแบบจำลอง เพื่อให้พนักงานใหม่ที่ถูกมอบหมายให้ดูแลแบบจำลองดังกล่าวในอนาคต เข้าใจถึงการทำงานและสามารถตรวจจับความผิดปกติของแบบจำลองได้
รูปแบบการโจมตี 3: การโจมตีด้วยข้อมูลเทียม (Adversarial Example Attacks)
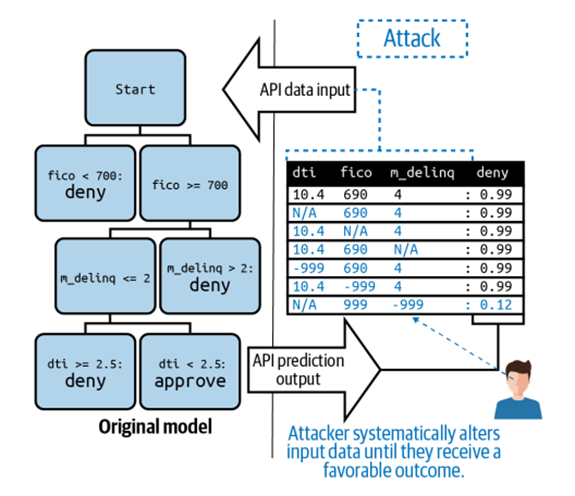
ในกรณีที่แบบจำลองเปิดให้ใช้ได้อย่างสาธารณะ ไม่จำกัดจำนวนครั้งในการใช้งานและผู้ใช้งานไม่ต้องระบุตัวตน ผู้ไม่หวังดีสามารถทดลองปรับค่าตัวแปรนำเข้าจนกว่าจะได้ผลลัพธ์ที่ต้องการ ทำให้เข้าใจตรรกะทางธุรกิจของแบบจำลองดังกล่าว ว่าให้ความสำคัญกับตัวแปรหรือลักษณะข้อมูลแบบใด
แนวทางการป้องกัน
- เพิ่มระบบการยืนยันตัวตนการใช้งาน (Authentication) เพื่อทำการบันทึกสำหรับตรวจสอบย้อนหลังว่า ผู้ใช้คนไหน ใช้งานผิดปกติ และมีเจตนาในการโจมตีแบบจำลอง
- เพิ่มการควบคุมการใช้งาน (Throttling) เพื่อทำให้ผลการทำนายออกมาช้าลง ทำให้ผู้ไม่หวังดีใช้เวลาในการโจมตีนานขึ้น ซึ่งช่วยให้ทางผู้พัฒนาสามารถเข้าไปตรวจสอบกิจกรรมและหาทางป้องกันได้ทัน
รูปแบบการโจมตี 4: การโจมตีเพื่อสร้างแบบจำลองตัวแทน (Surrogate Model Inversion Attacks)
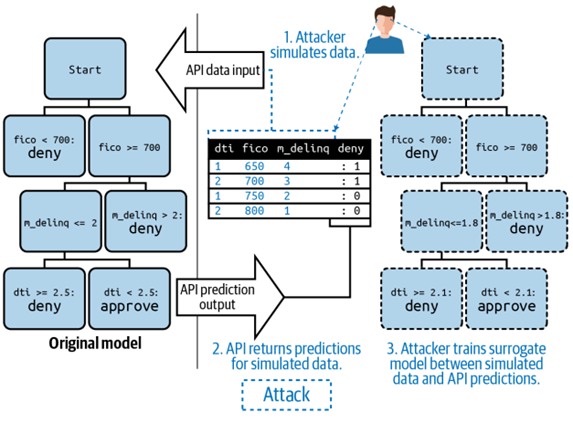
ในกรณีที่แบบจำลองเปิดให้ใช้ได้อย่างสาธารณะ ไม่จำกัดจำนวนครั้งในการใช้งานและผู้ใช้งานไม่ต้องระบุตัวตน ผู้ไม่หวังดีสามารถนำตัวอย่างข้อมูลไปให้แบบจำลองทำนายผลครั้งละมาก ๆ แล้วทำการรวบรวมผลลัพธ์ที่ได้รับ จากนั้นนำข้อมูลชุดเดียวกันและผลลัพธ์ที่ได้ มาสร้างและพัฒนาแบบจำลองใหม่เอง จนได้ผลลัพธ์ที่เหมือนกัน หากสำเร็จ ผู้ไม่หวังดีจะเข้าใจตรรกะทางธุรกิจของแบบจำลองดังกล่าว ว่าให้ความสำคัญกับตัวแปรแบบใด ข้อมูลที่ถูกใช้ฝึกฝนมีข้อมูลลักษณะเป็นอย่างไร และสามารถนำแบบจำลองที่สร้างใหม่มาไปใช้งานใน application ที่เหมือนกับต้นฉบับ โดยที่ไม่ต้องเสียค่าลิขสิทธิ์การใช้งานแบบจำลองดังกล่าว
แนวทางการป้องกัน
- นอกจากการเพิ่มระบบการยืนยันตัวตนการใช้งาน (Authentication) และเพิ่มการควบคุมการใช้งาน (Throttling) ในข้อก่อนหน้า ทางผู้พัฒนาควรลองโจมตีด้วยวิธีดังกล่าวด้วยตนเอง (White-hat Surrogate Models) เพื่อตรวจสอบว่า มีข้อมูลอะไรบ้างที่ผู้ไม่หวังดีสามารถเรียนรู้ได้จากการโจมตีดังกล่าว สามารถดึงตรรกะทางธุรกิจออกจากข้อมูลที่ได้รับจากการโจมตีมากน้อยเพียงใด และตัวแบบจำลองที่สร้างด้วยวิธีดังกล่าว ใช้งานได้มีประสิทธิภาพขนาดไหนเทียบกับแบบจำลองต้นฉบับ
บทส่งท้าย
จบไปแล้วนะครับ สำหรับเนื้อหาความปลอดภัยของการเรียนรู้ของเครื่องและตัวอย่างประเภทการโจมตีที่สามารถเกิดขึ้นได้ พร้อมวิธีป้องกันของแต่ละประเภทการโจมตี ซึ่งจะเห็นได้ว่า หากทางผู้พัฒนาแบบจำลองขาดความระมัดระวังเพื่อป้องการโจมตี การอาจเกิดผลเสียหายได้อย่างน่ากลัวทีเดียว
เอกสารอ้างอิง
- Examples / Responsible Machine Learning · GitLab (resources.oreilly.com/examples/0636920415947/blob/master/Attack_Cheat_Sheet.png)
- Fooling Automated Surveillance Cameras: Adversarial Patches to Attack Person Detection (https://arxiv.org/pdf/1904.08653.pdf)
- GWU_DNSC 6290: Course Outline. Introduction to Responsible Machine Learning (jphall663.github.io/GWU_rml)
- Hackers Trick Tesla Model S into Turning towards Oncoming Traffic Using Stickers on the Road (www.indiatimes.com/auto/alternative/hackers-trick-tesla-model-s-to-drive-in-the-wrong-lane-using-small-stickers-on-the-road-364797.html)
- Responsible AI – AI ที่สามารถไว้วางใจได้ (www.pwc.com/th/en/pwc-thailand-blogs/blog-20210401.html)
เนื้อหาโดย ธนกร ทำอิ่นแก้ว
ตรวจทานและปรับปรุงโดย อิสระพงศ์ เอกสินชล






Lead Technologist (Tech and Coaching) - Data Analytics Services Division (DAS), Big Data Institute (BDI)







