
ตลอดไม่กี่ปีที่ผ่านมา โลกของปัญญาประดิษฐ์ได้พัฒนาไปอย่างรวดเร็ว โดยเฉพาะในด้านของโมเดลภาษา (Large Language Models – LLMs) ที่มีทั้งขนาดของโมเดลและปริมาณข้อมูลในการฝึกสอนเพิ่มขึ้นอย่างมาก การเติบโตนี้ทำให้โมเดลมีความสามารถมากขึ้นเรื่อย ๆ แต่ก็ต้องแลกมาด้วยต้นทุนด้านการประมวลผลที่สูงขึ้นตามไปด้วย
หนึ่งในแนวทางที่ช่วยให้โมเดลมีความสามารถสูงขึ้นโดยไม่สูญเสียประสิทธิภาพคือแนวคิด Mixture-of-Experts (MoE) ซึ่งเป็นวิธีการแบ่งโมเดลออกเป็นกลุ่มของ “ผู้เชี่ยวชาญ” (experts) หลายตัว และมี “ตัวเลือก” (router) คอยตัดสินใจว่าในแต่ละรอบการประมวลผลจะใช้ผู้เชี่ยวชาญตัวใดบ้าง วิธีนี้ช่วยให้ระบบทำงานได้รวดเร็วขึ้น ใช้พลังคำนวณอย่างคุ้มค่า และยังคงให้ผลลัพธ์ที่มีคุณภาพสูง
Mixture‑of‑Experts คืออะไร?
Mixture-of-Experts (MoE) คือสถาปัตยกรรมของระบบประสาทเทียมที่ประกอบด้วย “ผู้เชี่ยวชาญ” (experts) หลายตัว ซึ่งแต่ละตัวมักเป็นเครือข่ายประสาทแบบฟีดฟอร์เวิร์ด (Feed-Forward Neural Network: FFNN) ที่มีความถนัดแตกต่างกัน แนวคิดนี้ตั้งอยู่บนสมมติฐานว่า “เราไม่จำเป็นต้องใช้โมเดลขนาดใหญ่ทั้งหมดทุกครั้งในการประมวลผลข้อมูล” แต่สามารถเลือกใช้เฉพาะผู้เชี่ยวชาญบางส่วนที่เหมาะสมกับข้อมูลนั้นแทนได้
สถาปัตยกรรม MoE มีองค์ประกอบหลักอยู่สองส่วน ได้แก่
- ผู้เชี่ยวชาญ (Experts) – โมเดลย่อยที่ทำหน้าที่เฉพาะด้าน เช่น การประมวลผลโทเคนบางประเภท หรือการเข้าใจบริบทบางรูปแบบ
- เครือข่ายตัวเลือก (Router หรือ Gating Network) – ระบบที่คำนวณความน่าจะเป็นและเลือกผู้เชี่ยวชาญที่เหมาะสมที่สุดกับข้อมูลแต่ละส่วน
ด้วยการเลือกใช้เฉพาะบางส่วนของโมเดลในแต่ละครั้ง ทำให้ MoE สามารถลดการใช้ทรัพยากรในการประมวลผลลงได้อย่างมาก เมื่อเทียบกับโมเดลแบบหนาแน่น (Dense Models) ที่ต้องทำงานทุกส่วนพร้อมกัน ขณะเดียวกัน ผู้เชี่ยวชาญแต่ละตัวก็สามารถเรียนรู้รูปแบบเฉพาะของข้อมูลได้ลึกขึ้น ทำให้โมเดลโดยรวมมีความยืดหยุ่นและฉลาดมากขึ้น
หลักการทำงานและวิวัฒนาการของ MoE
แนวคิดของ Mixture-of-Experts (MoE) ทำงานโดย “กระจายงานให้ผู้เชี่ยวชาญเพียงบางส่วน” สำหรับการประมวลผลข้อมูลแต่ละครั้ง กล่าวคือ เครือข่ายตัวเลือก (router) จะประเมินคะแนนของผู้เชี่ยวชาญแต่ละตัวผ่านฟังก์ชัน softmax จากนั้นจะเลือกผู้เชี่ยวชาญที่มีคะแนนสูงสุดมาทำงานกับอินพุตนั้น วิธีนี้เรียกว่า “conditional computation” ซึ่งช่วยลดภาระในการประมวลผลลงได้มาก เพราะโมเดลไม่จำเป็นต้องเปิดใช้งานพารามิเตอร์ทั้งหมดเหมือนในโมเดลแบบหนาแน่น (dense models)
แนวคิดของ MoE ปรากฏครั้งแรกตั้งแต่ช่วงต้นทศวรรษ 1990 ในนิพนธ์ชื่อ Adaptive Mixtures of Local Experts และกลับมาได้รับความสนใจอีกครั้งเมื่อ Noam Shazeer และคณะ เสนอแนวคิด Sparsely-Gated MoE ในปี 2017 สำหรับงานจำลองภาษาแบบลำดับ (sequence modeling) โมเดลนี้ใช้ผู้เชี่ยวชาญจำนวนมากในชั้นฟีดฟอร์เวิร์ด (feed-forward layer) แต่เลือกใช้งานเพียงบางส่วนในแต่ละครั้ง ทำให้สามารถเพิ่มจำนวนพารามิเตอร์โดยรวมได้หลายเท่า โดยไม่ต้องเพิ่มภาระการคำนวณตามไปด้วย
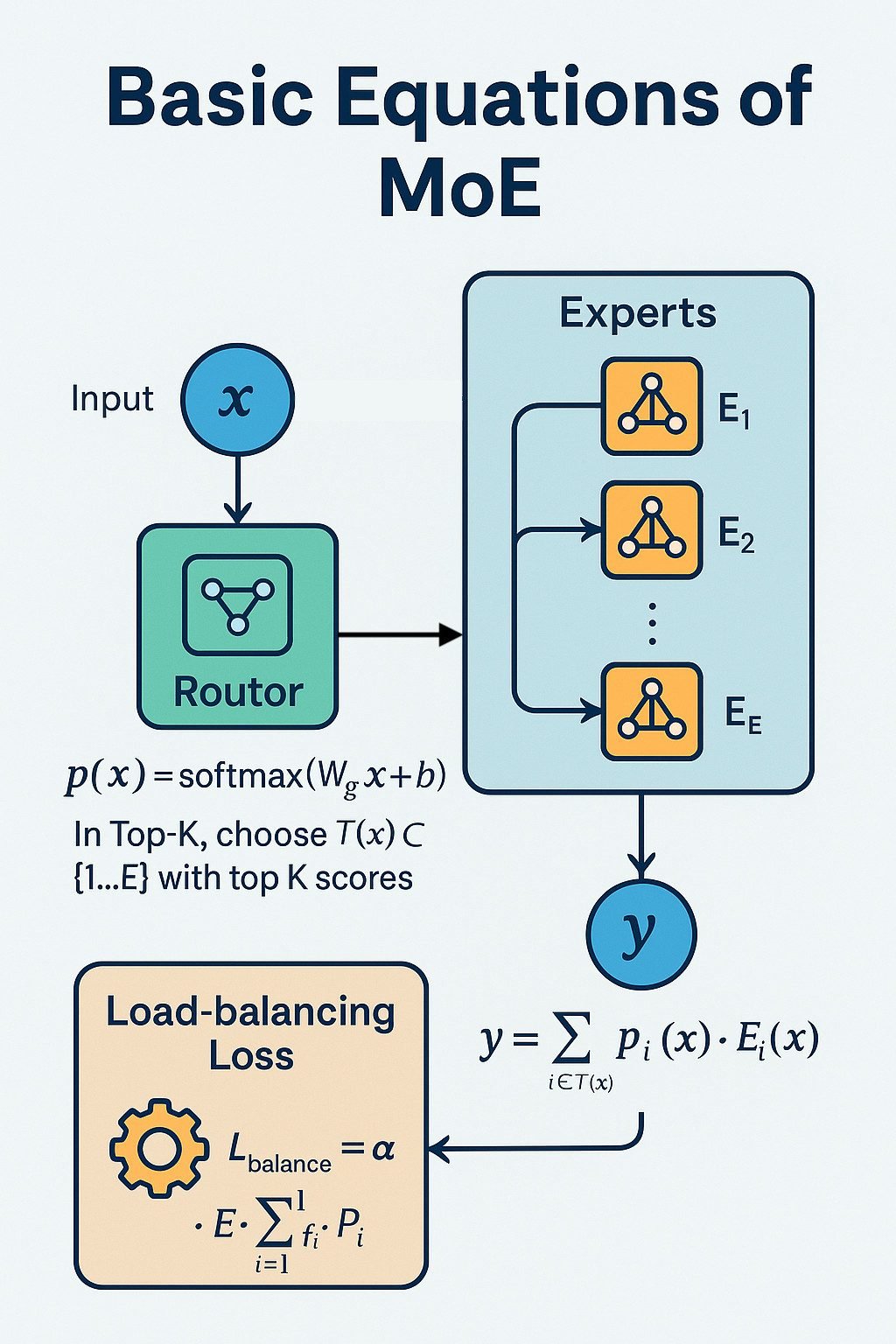
จากภาพ แสดงโครงสร้างพื้นฐานของ MoE – Router เลือกผู้เชี่ยวชาญที่เหมาะสมจากหลายโมดูลเพื่อประมวลผลอินพุตอย่างมีประสิทธิภาพ โดย
- กำหนดให้ x เป็นเวกเตอร์อินพุต และมีผู้เชี่ยวชาญทั้งหมด E ตัว
ค่าคะแนนการจัดเส้นทาง (gating score) ถูกคำนวณด้วยสมการ
p(x) = softmax(W_g x + b)
- ในกรณี Top-K, จะเลือกเซต T(x) ⊂ {1..E} ที่มีค่าคะแนนสูงสุด K ตัว
เอาต์พุตของชั้น MoE คำนวณได้จาก
y = Σ_{i∈T(x)} p_i(x) · E_i(x)
- เพื่อป้องกันปัญหาการกระจายงานไม่สมดุลระหว่างผู้เชี่ยวชาญ (load imbalance)
จะเพิ่ม loss เสริมแบบ load-balancing โดยมีสมการ
L_balance = α · E · Σ_{i=1}^E f_i · P_i
โดยที่ f_i คือสัดส่วนของโทเคนที่ถูกส่งไปยังผู้เชี่ยวชาญลำดับที่ i
และ P_i คือค่าเฉลี่ยของความน่าจะเป็นจาก router สำหรับผู้เชี่ยวชาญ i
ข้อดีและความท้าทายของ MoE
การออกแบบของ Mixture-of-Experts (MoE) ที่เปิดใช้งานเฉพาะส่วนของพารามิเตอร์ในแต่ละครั้ง ช่วยให้โมเดลมีจุดเด่นหลายประการ ได้แก่
- ประสิทธิภาพในการคำนวณสูง – โมเดลจะเลือกใช้เพียงผู้เชี่ยวชาญบางส่วนต่อหนึ่งอินพุต ทำให้ลดการใช้พลังงานและหน่วยความจำได้มากเมื่อเทียบกับโมเดลแบบหนาแน่น
- การกระจายการทำงานได้ดี – ผู้เชี่ยวชาญแต่ละตัวสามารถกระจายอยู่บนหลายอุปกรณ์หรือหลายเครื่องได้ ทำให้การฝึกสอนและการรันโมเดลขนาดใหญ่บนคลัสเตอร์เป็นไปได้จริง
- เกิดความเชี่ยวชาญเฉพาะด้าน – ผู้เชี่ยวชาญแต่ละตัวสามารถเรียนรู้รูปแบบข้อมูลที่แตกต่างกัน ทำให้โมเดลสามารถจัดการกับงานที่หลากหลายได้อย่างมีประสิทธิภาพมากขึ้น
- ขยายขนาดได้อย่างยืดหยุ่น – สามารถเพิ่มจำนวนผู้เชี่ยวชาญเพื่อเพิ่มขีดความสามารถของโมเดล โดยไม่ต้องเพิ่มภาระการคำนวณในสัดส่วนเดียวกัน
ความท้าทายของ MoE
แม้ MoE จะมีศักยภาพสูง แต่ก็มีข้อจำกัดและความท้าทายที่ต้องพิจารณา ได้แก่
- ความซับซ้อนในการฝึกสอน (Training Complexity) – การเลือกผู้เชี่ยวชาญและการคำนวณคะแนนจาก router ต้องมีการออกแบบที่แม่นยำ มิฉะนั้นอาจเกิดปัญหาผู้เชี่ยวชาญบางตัวไม่ได้รับการฝึกเพียงพอ (undertrained experts)
- ปัญหาการกระจายโหลดไม่สมดุล (Load Imbalance) – หาก router เลือกผู้เชี่ยวชาญบางตัวบ่อยเกินไป อาจทำให้เกิดการใช้งานทรัพยากรไม่เท่ากัน ซึ่งต้องแก้ไขด้วยเทคนิคเช่น load-balancing loss
- การสื่อสารระหว่างอุปกรณ์ (Communication Overhead) – เมื่อผู้เชี่ยวชาญถูกกระจายอยู่บนหลายเครื่อง การแลกเปลี่ยนข้อมูลระหว่างอุปกรณ์อาจกลายเป็นคอขวด (bottleneck) ที่ลดประสิทธิภาพโดยรวม
- ความยากในการนำไปใช้จริง (Deployment Difficulty) – การนำ MoE ไปใช้งานในระบบจริง โดยเฉพาะในสภาพแวดล้อมที่มีข้อจำกัดด้านหน่วยความจำหรือการเชื่อมต่อ จำเป็นต้องออกแบบระบบให้รองรับการเลือกผู้เชี่ยวชาญแบบไดนามิก
โมเดลรุ่นใหม่ที่ใช้หลักการ MoE
แนวคิด Mixture-of-Experts (MoE) ได้รับความนิยมอย่างต่อเนื่องในกลุ่มโมเดลภาษารุ่นใหม่ของปี 2025 ซึ่งหลายค่ายนำสถาปัตยกรรมนี้มาใช้เพื่อเพิ่มประสิทธิภาพและลดต้นทุนการประมวลผล โดยมีตัวอย่างที่น่าสนใจดังนี้
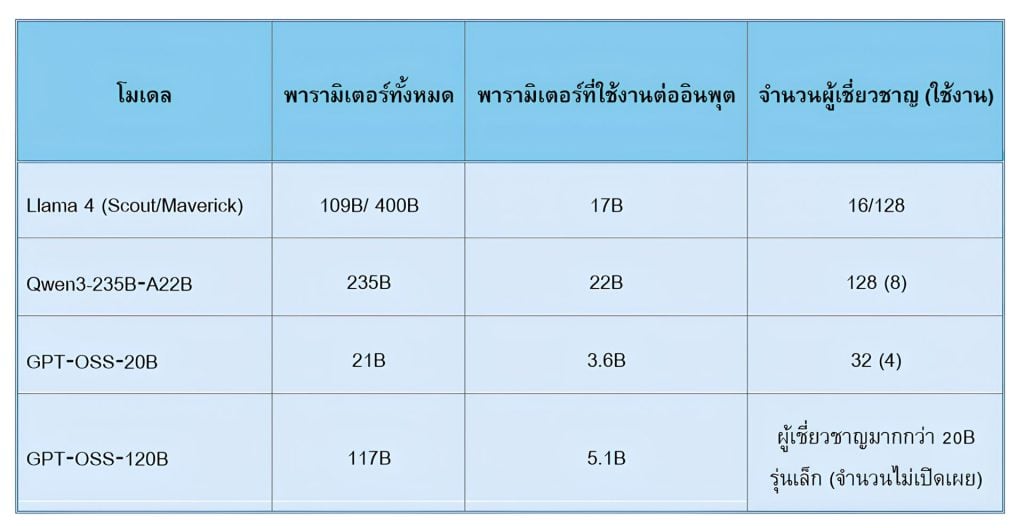
- Llama 4 (Meta) – เปิดตัวในเดือนเมษายน 2025 และให้บริการผ่านแพลตฟอร์มคลาวด์หลายแห่ง โมเดลรุ่นนี้ระบุชัดเจนว่าใช้สถาปัตยกรรมแบบ Mixture-of-Experts และรองรับการทำงานแบบมัลติโหมด (multimodal) ทั้งข้อความและภาพ ถือเป็นหนึ่งในโมเดลเชิงพาณิชย์ขนาดใหญ่ที่ใช้แนวคิด MoE อย่างเป็นทางการ
- Qwen3 (Alibaba) – นำเสนอทั้งรุ่น Dense และ MoE โดยรุ่น Qwen3-MoE สามารถให้สมรรถนะใกล้เคียงกับรุ่น Dense เดิม แต่ใช้พารามิเตอร์ที่ทำงานจริงต่อโทเคนเพียงประมาณ 10% ซึ่งช่วยลดค่าใช้จ่ายทั้งในขั้นตอนการฝึก (training) และการใช้งานจริง (inference) ได้อย่างมาก
- OpenAI gpt-oss – กลุ่มโมเดลแบบ open-weight ที่ใช้หลักการ MoE เช่น
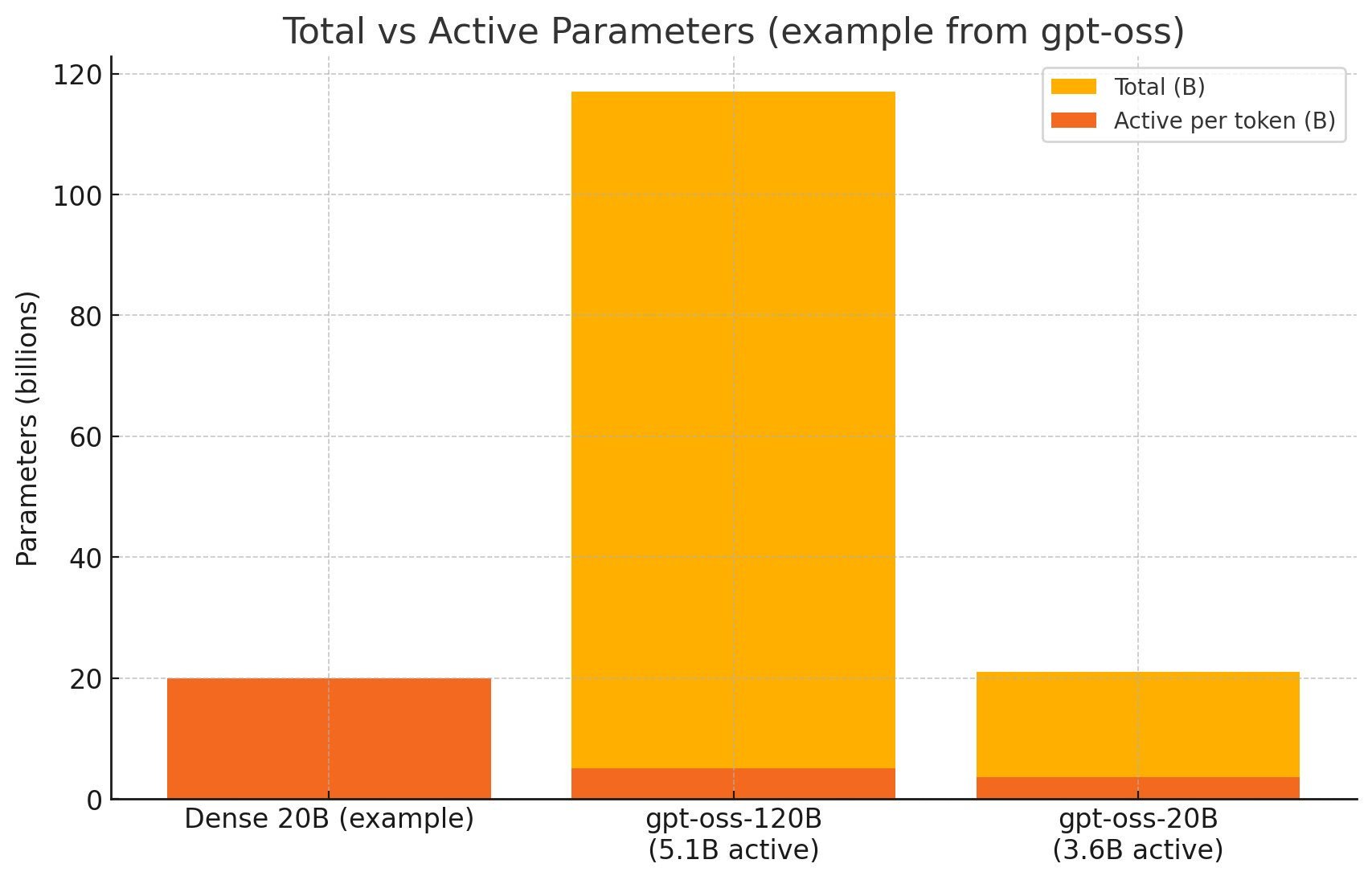
- gpt-oss-120B (เปิดใช้งานประมาณ 5.1B พารามิเตอร์ต่อโทเคน)
- gpt-oss-20B (เปิดใช้งานประมาณ 3.6B พารามิเตอร์ต่อโทเคน)
โมเดลเหล่านี้แสดงให้เห็นความแตกต่างเชิงปริมาณระหว่าง “จำนวนพารามิเตอร์ทั้งหมด” กับ “พารามิเตอร์ที่ทำงานจริง” ซึ่งเป็นหัวใจสำคัญของสถาปัตยกรรม MoE
ตารางสรุปโมเดลที่ใช้ MoE
สรุป
Mixture-of-Experts (MoE) เป็นสถาปัตยกรรมที่ช่วยให้โมเดลภาษาขนาดใหญ่สามารถขยายขนาดได้อย่างมีประสิทธิภาพ โดยแบ่งโมเดลออกเป็น “ผู้เชี่ยวชาญ” หลายตัว และใช้ “ตัวเลือก” (router) ในการกำหนดเส้นทางของข้อมูลไปยังผู้เชี่ยวชาญที่เหมาะสม แนวทางนี้ช่วยลดภาระการคำนวณ ใช้พลังงานและหน่วยความจำน้อยลง แต่ยังคงเพิ่มขีดความสามารถของโมเดลได้อย่างต่อเนื่อง
แนวคิด MoE ซึ่งเริ่มต้นจากงานวิจัยในช่วงทศวรรษ 1990 ได้รับการพัฒนาจนกลายเป็นเทคโนโลยีสำคัญในโมเดลรุ่นใหม่ของยุคปัจจุบัน เช่น Llama 4, Qwen3, และ GPT-OSS ที่ต่างนำแนวคิดนี้ไปปรับใช้เพื่อเพิ่มประสิทธิภาพ ลดต้นทุน และเปิดโอกาสให้ชุมชนผู้พัฒนาสามารถต่อยอดได้อย่างอิสระ
สำหรับประเทศไทย การมีโมเดล โอเพนซอร์สที่ใช้สถาปัตยกรรม MoE จะช่วยให้นักวิจัยและนักพัฒนาสามารถทดลอง สร้างสรรค์ และต่อยอดบริการอัจฉริยะได้ด้วยตนเอง โดยไม่ต้องพึ่งพาแพลตฟอร์มปิดจากต่างประเทศ ความเข้าใจเกี่ยวกับ MoE จึงเป็นรากฐานสำคัญในการก้าวสู่ยุคใหม่ของปัญญาประดิษฐ์ ที่เน้นทั้ง ประสิทธิภาพ การเปิดกว้าง และความยั่งยืนของนวัตกรรม
เอกสารอ้างอิง :
[1] Shazeer et al., 2017, ‘Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer' (arXiv:1701.06538) https://arxiv.org/abs/1701.06538
[2] Lepikhin et al., 2020, ‘GShard' (arXiv:2006.16668) https://arxiv.org/abs/2006.16668
[3] Fedus et al., 2021, ‘Switch Transformers' (arXiv:2101.03961) https://arxiv.org/abs/2101.03961
[4] Meta Llama 4 บน Azure/Databricks https://azure.microsoft.com/en-us/blog/introducing-the-llama-4-herd-in-azure-ai-foundry-and-azure-databricks/
[5] Cloudflare: ‘Llama 4 is now available on Workers AI' https://blog.cloudflare.com/meta-llama-4-is-now-available-on-workers-ai/
[6] TechCrunch: ‘Meta releases Llama 4' https://techcrunch.com/2025/04/05/meta-releases-llama-4-a-new-crop-of-flagship-ai-models/
[7] Qwen3 GitHub https://github.com/QwenLM/Qwen3
[8] Qwen3 Blog (Qwen) https://qwenlm.github.io/blog/qwen3/
[9] Alibaba Cloud: ‘Qwen3 … Hybrid Reasoning' https://www.alibabacloud.com/blog/alibaba-introduces-qwen3-setting-new-benchmark-in-open-source-ai-with-hybrid-reasoning_602192
[10] OpenAI: ‘Introducing gpt‑oss' https://openai.com/index/introducing-gpt-oss/
[11] GitHub: openai/gpt‑oss https://github.com/openai/gpt-oss
[12] Wikipedia. “Mixture of experts: Machine learning technique.” อธิบายว่า MoE ประกอบด้วยผู้เชี่ยวชาญหลายชุดและฟังก์ชันเกตสำหรับกำหนดน้ำหนัก.
[13] Neptune.ai. “Mixture of Experts LLMs: Key Concepts Explained.” สรุปข้อดีของ MoE เช่น การใช้ผู้เชี่ยวชาญบางส่วนต่ออินพุต การแบ่งภาระ และประสิทธิภาพการฝึก.
[14] Neptune.ai. “Mixture of Experts LLMs: Key Concepts Explained.” อธิบายว่าผู้เชี่ยวชาญถูกจัดเป็น sub-networks ที่เปิดใช้งานตามอินพุตและสามารถกระจายไปยังอุปกรณ์หลายตัวได้.
[15] Du et al. “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts.” รายงานว่า GLaM มี 1.2 ล้านล้านพารามิเตอร์ ใช้สถาปัตยกรรม MoE และใช้พลังงานเพียงหนึ่งในสามของ GPT‑3.
[16] Meta. “Llama 4: Leading intelligence.” หน้าเว็บทางการระบุว่า Llama 4 ใช้สถาปัตยกรรม multimodal และ mixture-of-experts พร้อม context window ขนาดใหญ่.
[17] Meta. “Build with Llama 4.” หน้าเว็บแสดงคุณลักษณะของรุ่นย่อยเช่น Llama 4 Scout ที่รองรับ multimodal และ context window ยาว 10M tokens.
[18] HuggingFace model card. “Qwen3-235B-A22B-Thinking-2507.” ระบุว่ามีพารามิเตอร์รวม 235B และเปิดใช้งาน 22B ต่อ token บ่งบอกการใช้ MoE.
[19] GPT-Oss.ai. “GPT-Oss MoE Architecture.” อธิบายว่า GPT‑Oss ใช้ผู้เชี่ยวชาญ 128 ชุดและ Top‑4 routing มีพารามิเตอร์ sparse 11.6B ใช้งานจริง 510M.




