
ความท้าทายงานจดหมายเหตุเมื่อเข้าสู่ยุค Big Data
ตอนที่ 1. ความหมายของจดหมายเหตุ
ตอนที่ 2. การทำให้เป็นดิจิทัลของเอกสารจดหมายเหตุ (ท่านกำลังอ่านบทความนี้)
ตอนที่ 3. การใช้ประโยชน์ข้อมูลงานจดหมายเหตุ
ก่อนหน้านี้ในบทความ งาน “จดหมายเหตุ” ความท้าทายเมื่อเข้าสู่ยุค Big Data เราได้รู้จักคำจำกัดความของงาน “จดหมายเหตุ” และการคัดแยกระหว่างสิ่งที่เป็นเอกสารจดหมายเหตุและสิ่งที่ไม่ใช่เอกสารจดหมายเหตุ ซึ่งจะเห็นได้ว่ารูปแบบของเอกสารจดหมายเหตุเปลี่ยนไปตามกาลเวลาดังภาพที่ 1

การจัดการเอกสารจดหมายเหตุในปัจจุบันสมัยจึงเป็นสิ่งที่ท้าทายมากยิ่งขึ้นทั้งในปัจจัยทางรูปแบบเอกสารและปัจจัยทางการวิเคราะห์ข้อมูล ซึ่งในบทความนี้จะแบ่งความท้าทายในงานจดหมายเหตุออกเป็น 4 ประเด็นดังนี้
- ข้อมูลมีความหลากหลายมากขึ้นในยุค Big Data
- หากต้องการใช้ข้อมูลเก่าในการวิเคราะห์ การแปลงข้อมูลให้อยู่ในรูปแบบดิจิทัล (Digitization) กับข้อมูลชุดนั้นจึงมีบทบาทที่สำคัญ
- ข้อมูลที่มีมากขึ้นในปัจจุบันทำให้เทคนิคในการหาข้อมูลเชิงลึก (Insights) และการจัดการเอกสารที่ซับซ้อนยิ่งขึ้นจึงเป็นเรื่องที่สำคัญ
- ข้อมูลมีบริบทที่หลากหลายทำให้คนที่ตีความข้อมูลและผลการวิเคราะห์ต้องมีความรู้รอบด้าน
โดยบทความนี้จะพูดถึงในสองหัวข้อแรกก่อน ซึ่งเกี่ยวข้องกับส่วนของการแปลงข้อมูลให้อยู่ในรูปแบบดิจิทัล (Digitalization)
ภาพรวมของเนื้อหา
ข้อมูลที่หลากหลายมากขึ้นในยุค Big Data
ด้วยความที่หลักฐานทางประวัติศาสตร์สามารถเป็นเอกสารจดหมายเหตุได้ โดยขึ้นอยู่การจัดการเก็บรวบรวมของเอกสารหรือวัสดุนั้น ๆ หากหลักฐานทางประวัติศาสตร์นั้นได้ถูกจัดเก็บและได้ทำบัญชีแล้ว หลักฐานทางประวัติศาสตร์นั้นจะนับเป็นเอกสารจดหมายเหตุตามนิยามของเอกสารจดหมายเหตุ ฉะนั้นการพิจารณารูปแบบของเอกสารจดหมายเหตุจึงสามารถทำได้เหมือนกับ “หลักฐานทางประวัติศาสตร์”
เอกสารจดหมายเหตุสามารถเป็นได้ทั้งในรูปแบบที่เป็นลายลักษณ์อักษรและไม่ใช่ลายลักษณ์อักษร โดยผันแปรไปตามเทคโนโลยี ซึ่งในปัจจุบัน รูปแบบการจัดเก็บของเอกสาร มีความซับซ้อนยิ่งขึ้นตามเทคโนโลยี เอกสารจดหมายเหตุนั้นสามารถอยู่ทั้งในรูปแบบดิจิทัลและรูปแบบไม่เป็นดิจิทัล ซึ่งสามารถแบ่งออกมาได้เป็นดังภาพที่ 2
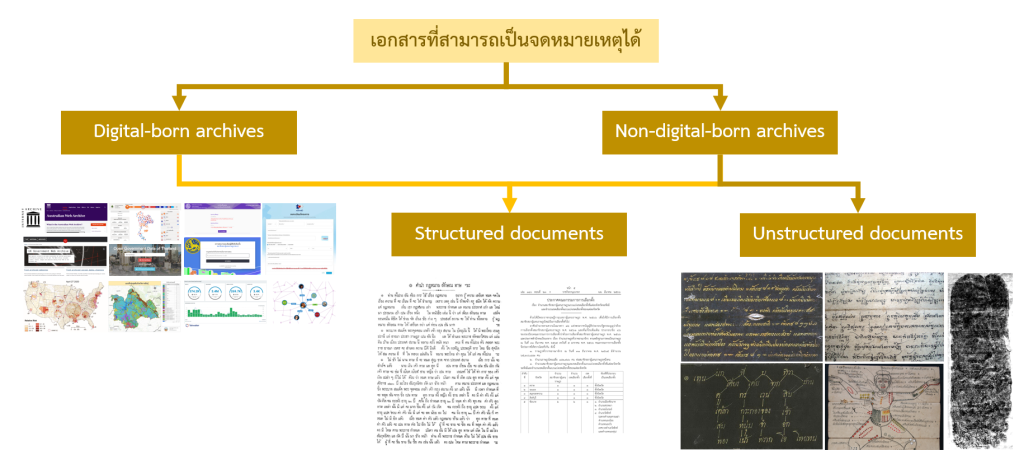
เอกสารแบบมีโครงสร้างกับเอกสารแบบไม่มีโครงสร้าง
โครงสร้างของเอกสารนับจากรูปแบบที่ตายตัวของเอกสารนั้น ๆ เช่น เอกสารที่มีรูปแบบชัดเจนถูกกำหนดด้วยระเบียบ เช่น เอกสารของรัฐในสหรัฐอเมริกาที่มีรูปแบบมาตรฐานจาก U.S. Government Publishing Office Style Manual หรือในประเทศไทยที่มีระเบียบสำนักนายกรัฐมนตรีว่าด้วยงานสารบรรณ พ.ศ. 2526 กำกับอย่างชัดเจน หรือแม้แต่ว่าหากไม่ได้มีลักษณะรูปแบบที่ตายตัวก็อาจมีวิธีการเขียนที่ตายตัว เช่น มหากฎบัตร (Magna Carta)
แต่เมื่อเรากล่าวถึงเอกสารที่ไม่มีรูปแบบตายตัวหรือเอกสารไม่มีโครงสร้าง เราจะหมายถึงวิธีการเขียนที่มีพลวัตเฉพาะในแต่ละเล่ม หรือ อาจมีลักษณะการเขียนที่เฉพาะซึ่งไม่ตรงกับไวยากรณ์ปัจจุบันหรือเป็นการเล่นกลเพื่อสุนทรียภาพ เช่น ความเป็นกลบท หรือ ภาพประกอบ ซึ่งลักษณะเอกสารโบราณเหล่านี้จึงไม่สามารถใช้วิธีการจัดการเอกสารเหมือนกับเอกสารในยุคปัจจุบันได้
การคัดแยกเอกสารที่สามารถเป็นจดหมายเหตุได้ว่าเป็น Digital-born จะสามารถคัดแยกได้จากความจำเป็นในการทำ Digitization ต่อเอกสารนั้น ๆ หากต้องการให้คอมพิวเตอร์สามารถอ่านได้ หากเอกสารนั้นไม่มีความจำเป็นในการทำ Digitization จะนับว่าเอกสารที่เป็น Digital-born
ว่าด้วยรูปแบบเอกสาร Digital-born และโครงการที่เกี่ยวข้อง
เอกสารที่เป็น Digital-born จะกล่าวถึงเอกสารที่สร้างขึ้นจากคอมพิวเตอร์ โดยไม่ได้เกิดจากกระบวนการ Digitization โดยตัวอย่างเอกสาร Digital-born จะเป็นไปดังภาพที่ 3

ตัวอย่างของเอกสาร digital-born
- ข้อมูลเว็บไซต์ เป็นข้อมูลที่สามารถเข้าถึงได้ผ่านเว็บเบราว์เซอร์ โดยอยู่ในรูปแบบเว็บไซต์ เช่น เว็บไซต์ของหน่วยงานราชการ ซึ่งจะเก็บรูปแบบของเว็บไซต์และข่าวประชาสัมพันธ์ที่เกี่ยวข้อง
- ข้อมูลที่เกี่ยวข้องกับ e-Service เป็นข้อมูล Transactional ที่เกิดขึ้นจากกระบวนการที่เกี่ยวข้องกับบริการอิเล็กทรอนิกส์
- ข้อมูลสถิติ เป็นข้อมูลที่สร้างขึ้นโดยเป็นดิจิทัล ทั้งในรูปแบบเชิงภูมิสารสนเทศ ซึ่งสร้างขึ้นจากดาวเทียมหรืออากาศยานที่ส่งข้อมูลแบบดิจิทัล หรือไม่ใช่รูปแบบสารสนเทศที่ไม่ใช่เชิงภูมิสารสนเทศ เช่น ข้อมูลสำรวจ ข้อมูลเอกสารสารบรรณอิเล็กทรอนิกส์
- ข้อมูลประเภทอื่น ๆ เช่นข้อมูล Graph Network เช่น ข้อมูลสังคมออนไลน์ ข้อมูลความเชื่อมโยงจากความสัมพันธ์ที่วิเคราะห์ในแบบจำลอง หรือ Linked Data เช่น วิกิพีเดีย, ข้อมูล Streaming อย่างข้อมูลจากอุปกรณ์ Internet of Things (IoT) เป็นต้น
การแบ่งรูปแบบเอกสาร Digital-born นี้มีความแตกต่างในการจัดเก็บข้อมูล อย่างข้อมูลเว็บไซต์อาจต้องเก็บข้อมูลให้ยังสามารถเข้าถึงผ่านเว็บเบราว์เซอร์ได้ในปัจจุบัน โดยมีเซิร์ฟเวอร์ที่สามารถโฮสต์เว็บนั้นได้อยู่ ข้อมูลที่เกี่ยวข้องกับ e-Service อาจสามารถเก็บอยู่ภายใต้ Relational Database, ข้อมูลสถิติอาจปล่อยเป็นรูปแบบหน้า View ซึ่งให้เข้าถึงผ่าน API ได้ หรือข้อมูลประเภทอื่น ๆ ซึ่งวิธีการเก็บข้อมูลต่าง ๆ จะใช้สถาปัตยกรรมข้อมูลที่แตกต่างกันขึ้นกับข้อมูลนั้น ๆ
ความท้าทายแรกที่ว่านี้จึงเป็นส่วนของการวางสถาปัตยกรรมข้อมูลและการวางนโยบายธรรมาภิบาลข้อมูลขององค์กร ซึ่งโครงการธรรมาภิบาลข้อมูลจากแต่ละประเภทข้อมูลที่ได้ยกตัวอย่างมาอาจยกตัวอย่างได้ 2 กรณี คือ
- Government Web Archive: ในหลายประเทศ โครงการที่เกี่ยวข้องกับการทำงานจดหมายเหตุกับข้อมูลเว็บไซต์ของรัฐบาลได้มีการจัดทำขึ้น เช่น สหราชอาณาจักร ออสเตรเลีย นิวซีแลนด์ โดยโครงการดังกล่าวนี้ได้เก็บเว็บไซต์ของรัฐในทุก ๆ เวอร์ชันตั้งแต่เวอร์ชันเก่า จนถึงเวอร์ชันก่อนเวอร์ชันปัจจุบัน การต่อยอดการวิเคราะห์ข้อมูลเว็บไซต์เกิดขึ้นเพื่ออำนวยความสะดวกในการค้นคว้าข้อมูลได้เกิดขึ้น ซึ่งตัวอย่างหน่วยงานที่เกี่ยวข้องกับการวิเคราะห์ข้อมูลขนาดใหญ่ที่จัดทำโครงการนี้ คือ สถาบันอลัน ทัวริ่ง (Alan Turing Institute) ภายใต้การสนับสนุนงบประมาณของรัฐบาลสหราชอาณาจักร โดยจัดทำ Semantic Search Engine ของ The National Web Archive ของสหราชอาณาจักร1 สร้างออกมาเป็น Knowledge Graph และทำ Tagging ในเว็บเพจที่มีในฐานข้อมูล
- Government Open Data: หลายประเทศก็มีโครงการในลักษณะแบบนี้เช่นกัน โดยมีกระบวนการที่ถูกวิจัยหลายประเด็น เช่น การทำ Semantic Tagging ในกระบวนการจัดทำร่างกฎหมาย2 หรือมีความพยายามสร้างการมีส่วนร่วมของประชาชนของ Open Data platform เช่น https://data.gouv.fr ก็เป็นการจัดการเอกสาร Digital-born ในอีกรูปแบบหนึ่งเช่นกัน
แต่ถ้าหากว่าเราสนใจเอกสารที่ไม่เป็น Digital-born ความท้าทายที่เกิดขึ้นจะเป็นอีกรูปแบบหนึ่ง ซึ่งเจาะจงไปที่การทำให้อยู่ในรูปแบบดิจิทัลของเอกสารนั้น ๆ โดยจะกล่าวถึงในหัวข้อถัดไป
กระบวนการ Digitization ในเอกสารจดหมายเหตุ
การทำ Digitization เบื้องต้นในเอกสารจดหมายเหตุจะสามารถแบ่งขั้นตอนได้ออกมาเป็น 4 ขั้นตอนหลักดังภาพที่ 4 ซึ่งกระบวนการที่มีความแตกต่าง คือ กระบวนการที่ 1 ในการสแกนเอกสารซึ่งใช้อุปกรณ์และเทคนิคที่แตกต่างกันตามชนิดเอกสารนั้น ๆ และกระบวนการที่ 3 ที่จะทำการดึงสารสนเทศของเอกสาร (Information Retrieval) นั้นออกมา เช่น เอกสารลายลักษณ์ สามารถใช้เทคนิค Optical Character Recognition (OCR) ในดึงข้อความจากเอกสาร หรือ เอกสารจำพวกเสียง อาจนำเทคนิคที่เกี่ยวกับ Speech-to-text มาแปลงเป็นรูปคำที่กล่าวออกมาในไฟล์เสียงนั้น ๆ ได้อีกด้วย

รายละเอียดการทำ digitization
ขั้นตอนการทำ digitization สามารถแบ่งเป็น 4 ขั้นตอนโดยคร่าวดังนี้
- Scanning: กระบวนการนี้เป็นการทำให้เอกสารอยู่ในรูปแบบดิจิทัล (Digitalization) จะใช้อุปกรณ์ที่ตรวจจับสัญญาณแอนาล็อกเป็นสัญญาณดิจิทัล (Analog-to-digital Device) เช่น กล้องถ่ายรูป เครื่องอัดเสียงดิจิทัล เครื่องสแกนสามมิติที่พยายามสร้าง Point Cloud แล้วแปลงเป็นวัตถุสามมิติ โดยกระบวนการนี้จะเป็นเพียงการสุ่มตัวอย่างจากบางส่วนของสัญญาณแอนาล็อกเท่านั้น เพราะ Digitalization จะมีขั้นตอนที่ทำให้เกิดการสูญเสียรายละเอียดข้อมูลไปบางส่วนจากกระบวนการ Sampling กับ Quantization
- Upload: ถัดจากที่ได้เอกสารรูปแบบดิจิทัลในขั้นตอนที่ 1 เป็นที่เรียบร้อยแล้ว การจัดเก็บข้อมูลที่ได้มาเป็นเรื่องที่สำคัญก่อนที่จะนำมาใช้ประโยชน์ ซึ่งส่วนประกอบที่สำคัญ คือ ตัวจัดเก็บข้อมูลและระบบจัดการไฟล์ ซึ่งสามารถเป็นได้ทั้งระดับส่วนบุคคล จนถึงสามารถวางศูนย์ข้อมูลที่รองรับข้อมูลขนาดใหญ่มากขึ้น
- Process: สืบเนื่องจากเอกสารดิจิทัลที่ได้มาในขั้นตอนที่ 1 นั้นยังมีลักษณะรูปแบบที่คอมพิวเตอร์ยังไม่สามารถประมวลผลได้ (Machine-readable) ขั้นตอนนี้จึงเป็นการตีความหมาย ซึ่งถ้าหากเป็นตัวอักษรอาจทำการปริวรรต (Transliteration) หรือถ้าเป็นเสียง อาจใช้การถอดเสียง (Transcription) ออกมาได้เช่นกัน นอกจากนี้ การทำสาระสังเขปหรือบัญชีข้อมูลให้กับเอกสารดังกล่าวก็มีส่วนที่ทำให้เห็นถึงบริบทของเอกสารมากยิ่งขึ้นอีกด้วย
- Display: เมื่อเอกสารได้ผ่านกระบวนการทั้งสามกระบวนการเป็นที่เรียบร้อยแล้ว เราสามารถทำให้เกิดการใช้ประโยชน์ข้อมูลโดยสาธารณะได้ด้วยการเผยแพร่และสร้างแพลตฟอร์มให้สามารถเข้าถึงได้ ซึ่งทำให้การเป็นจดหมายเหตุสาธารณะได้ทำหน้าที่ของมันโดยสมบูรณ์
ทว่าในบางครั้ง ความแม่นยำในการดึงสารสนเทศออกมาจากเอกสารเหล่านั้นอาจมีไม่สูงนัก เนื่องจากข้อจำกัดทางอุปกรณ์และอัลกอริทึมที่ใช้ในการดึงข้อมูล โดยในที่นี้เราจะยกตัวอย่างเป็นเอกสารลายลักษณ์ที่ปรากฏอยู่ในประวัติศาสตร์ไทย
Digitization งานเอกสารลายลักษณ์ภาษาไทย
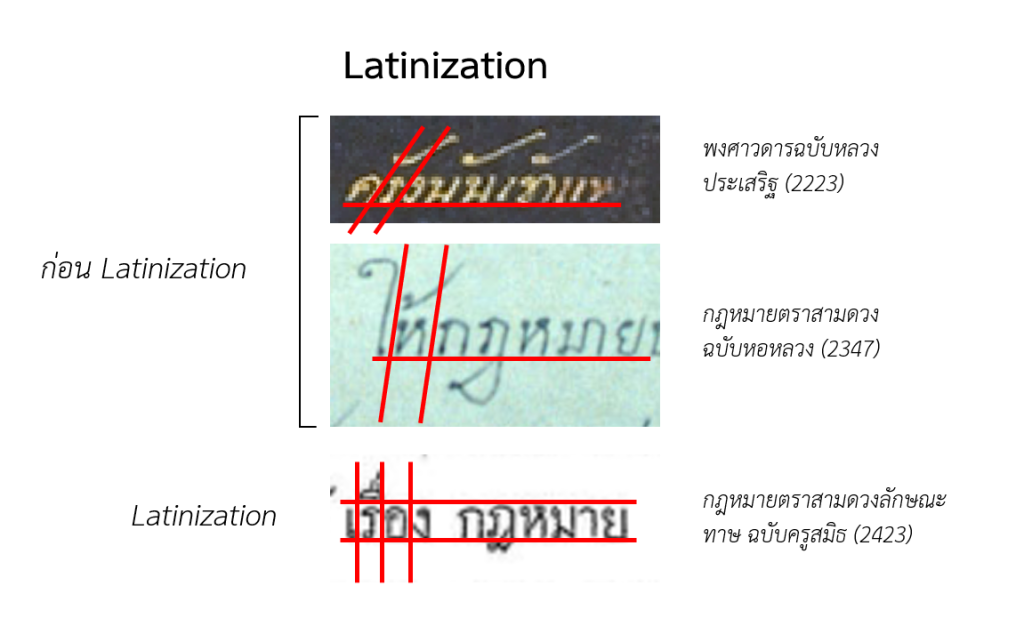
ในบริบทของภาษาไทย การปฏิรูปอักขระไทยมีส่วนสำคัญในการประเมินความสะดวกในการทำ digitization โดยการปฏิรูปอักขระไทยเกิดขึ้นในสมัยรัชกาลที่ 3 จากใบประกาศห้ามสูบฝิ่นและเอกสารไวยากรณ์ไทย และมีแบบอักขระในการจัดพิมพ์ที่เหมาะสมกับการพิมพ์เอกสารด้วยแท่นเดิม ซึ่งเรียกว่าตัวพิมพ์ตะกั่ว เหตุการณ์สำคัญดังกล่าวที่ใช้แยกเกณฑ์การทำ Digitization คือ การทำให้ตัวอักขระไทยเป็นอักขระตั้งตรง (Latinization3,4) โดยความแตกต่างเป็นไปดังภาพที่ 5
นอกจากนี้แล้ว รูปแบบเอกสารอาจไม่ได้มีลักษณะเป็นการเขียนเรียงเป็นบรรทัดอย่างที่เป็นในปัจจุบันดังตัวอย่างในภาพที่ 6 เช่น กลบท หรือ การเขียนรวบรัดอย่างฉบับขอม รวมทั้งในบางครั้งเอกสารนั้นอาจไม่ได้ใช้ตัวอักษรไทย แต่อาจใช้ไวยากรณ์และการสะกดแบบภาษาไทย เช่น ตัวอักษรไทยย่อ ไทยขอม ปัลลวะ ตัวธรรมอีสาน/เมือง หรืออาจเขียนเป็นภาษาอื่น เช่น ภาษาจีน

หากว่ากระบวนการ OCR ไม่สามารถนำมาใช้ได้แล้ว โดยปกติ วิธีการทางโบราณคดีในการตีความเอกสารเหล่านี้จะแบ่งออกเป็น 5 ขั้นตอนตามภาพที่ 7

รายละเอียดการถอดอักขระจากเอกสารลายลักษณ์ไทย (ซึ่งอาจไม่ใช่อักษรไทยปัจจุบัน)
- ทำสำเนาต้นฉบับกับเอกสารที่เกี่ยวข้องในกรณีที่เอกสารดังกล่าวนั้นไม่สามารถยกมาได้ (ซึ่ง ณ ที่นี้ หมายถึงกำลังแรงของนักโบราณคดีทั่วไปคนหนึ่ง)
- เอกสารที่สามารถยกมาได้ ยกตัวอย่างเช่น หนังสือไม้ไผ่จากสมัยจีนยุคจักรพรรดิ สมุดใบลาน สมุดไทย ซึ่งสิ่งเหล่านี้สามารถยกมาได้ไม่ต้องทำขั้นตอนนี้ แต่หากว่ามีการถอดรื้อหรือทำความสะอาดเพื่อบำรุงรักษาเอกสารและทำให้กระบวนการถอดอักขระเป็นไปได้ง่ายยิ่งขึ้น
- เอกสารที่ไม่สามารถยกได้ เช่น จารึก ซึ่งกระบวนการทำสำเนาจารึกจะเป็นไปในลักษณะดังในวิดีทัศน์นี้ (วิดีทัศน์ประกอบ: ตอนที่ 4 การทำสำเนาจารึก โดย อาจารย์พอพล สุกใส – YouTube)
- ถอดอักษรจากต้นฉบับหรืออักขรวิทยา (Paleography): กระบวนการนี้อาศัยความเข้าใจในบริบททางประวัติศาสตร์และอักษรศาสตร์ในการถอดอักษรออกมาให้ใกล้เคียงกับสถานการณ์ ณ ขณะนั้นที่สุด เริ่มต้นจากการตีความก่อนว่าอักษรดังกล่าวเป็นอักษรรูปแบบใดและเขียนในภาษาใด ซึ่งอาจมีการเข้ารหัสข้อความและถอดความต่อไปในขั้นตอนถัดไป
- การถอดปริวรรต (Transliteration): กระบวนการนี้เป็นกระบวนการที่พยายามแปลงอักษรที่ได้มาจากการแปลงในการทำอักขรวิทยาให้อยู่ในรูปแบบภาษาปัจจุบันตามหลักการสะกดและไวยากรณ์
- การแปลความ: กระบวนการนี้จะมีการใช้บริบททางประวัติศาสตร์เพิ่มเข้าไปให้บุคคลอื่นสามารถเข้าใจความเป็นมาของเอกสาร นักประวัติศาสตร์จะมีบทบาทมากในส่วนนี้ ซึ่งฐานคิดของนักประวัติศาสตร์จะวางอยู่บนปรัชญาประวัติศาสตร์ของสำนักต่าง ๆ และข้อเสนอของนักประวัติศาสตร์ท่านอื่น ๆ
จะเห็นได้ว่าในกระบวนการ Digitization ขั้นตอนที่ 1 และ 3 ในภาพที่ 4 นั้นมีความละเอียดอ่อนและบางครั้งอาจต้องใช้ผู้เชี่ยวชาญจากสาขาที่เกี่ยวข้องกับเอกสารชุดนั้น ๆ มาทำ Digitization อีกด้วย นอกจากนี้แล้ว กระบวนการ Digitization ยังมีความซับซ้อนเพิ่มเติมในส่วนขั้นตอนที่ 2 และขั้นตอนที่ 4 อีกด้วย ซึ่งความซับซ้อนดังกล่าวเกี่ยวข้องกับการจัดการข้อมูลขนาดใหญ่และลักษณะภววิทยาของเอกสารจดหมายเหตุที่แปลงมาอยู่ในรูปแบบดิจิทัลเป็นที่เรียบร้อยแล้วอีกด้วย
เมื่อเรากล่าวถึงกระบวนการที่ทำให้เอกสารต่าง ๆ เป็นข้อมูลดิจิทัลซึ่งนำไปใช้ประโยชน์ได้แล้ว ความท้าทายหนึ่งที่สำคัญไม่แพ้กับกระบวนการ Digitization คือ การนำข้อมูลไปใช้ประโยชน์ได้อย่างมีประสิทธิภาพ ซึ่งเราจะกล่าวในตอนถัดไป
เชิงอรรถ
- Alan Turing Institute, Data Study Group Final Report: The National Archives, UK, สามารถเข้าถึงได้ที่ https://www.turing.ac.uk/sites/default/files/2021-06/data_study_group_final_report_2020_-_national_archives.pdf
- Petr Křemen และ Martin Nečaský (2019), Improving discoverability of open government data with rich metadata descriptions using semantic government vocabulary, สามารถเข้าถึงได้ที่: https://doi.org/10.1016/j.websem.2018.12.009
- ประชา สุวีรานนท์ (2545), ๑๐ ตัวพิมพ์ กับ ๑๐ ยุคสังคมไทย, สามารถเข้าถึงได้ที่: https://www.sarakadee.com/feature/2002/09/thaifont.htm
- กมลกานต์ โกศลกาญจน์ (2564), ทุติยะและฝรั่งเศส ความจริงในความเปลี่ยนแปลง, สามารถเข้าถึงได้ที่: https://www.cadsondemak.com/medias/read/thai-latinized-typeface
เรียบเรียงโดย กฤตพัฒน์ รัตนภูผา
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์












