
ความท้าทายงานจดหมายเหตุเมื่อเข้าสู่ยุค Big Data
ตอนที่ 1. ความหมายของจดหมายเหตุ
ตอนที่ 2. การทำให้เป็นดิจิทัลของเอกสารจดหมายเหตุ
ตอนที่ 3. การใช้ประโยชน์ข้อมูลงานจดหมายเหตุ (ท่านกำลังอ่านบทความนี้)
จาก 4 ประเด็นความท้าทายในงานจดหมายเหตุ
- ข้อมูลมีความหลากหลายมากขึ้นในยุค Big Data
- หากต้องการใช้ข้อมูลเก่าในการวิเคราะห์ การแปลงข้อมูลให้อยู่ในรูปแบบดิจิทัล (Digitization) กับข้อมูลชุดนั้นจึงมีบทบาทที่สำคัญ
- ข้อมูลที่มีมากขึ้นในปัจจุบันทำให้เทคนิคในการหาข้อมูลเชิงลึก (Insights) และการจัดการเอกสารที่ซับซ้อนยิ่งขึ้นจึงเป็นเรื่องที่สำคัญ
- ข้อมูลมีบริบทที่หลากหลายทำให้คนที่ตีความข้อมูลและผลการวิเคราะห์ต้องมีความรู้รอบด้าน
ในบทความตอนที่ 2 ได้พูดถึงประเด็นความท้าทาย 2 ประเด็นแรกเป็นที่เรียบร้อยแล้ว ซึ่งเกี่ยวข้องกับการทำเอกสารให้อยู่รูปแบบดิจิทัล (Digitization) ซึ่งชี้ให้เห็นว่ากระบวนการทั้งระบบในการเก็บเอกสารให้อยู่ในรูปแบบดิจิทัลจะต้องทำอย่างไรบ้าง
บทความนี้จึงต้องการให้เห็นถึงการใช้ประโยชน์ข้อมูลจดหมายเหตุเป็นกรณีศึกษาทั้งในหอจดหมายเหตุและนอกหอจดหมายเหตุ ซึ่งสามารถปรับใช้ทฤษฎีทางจดหมายเหตุและการบริหารจัดการข้อมูลกับองค์กรได้ และความท้าทายอื่น ๆ ที่เกี่ยวข้องกับงานจดหมายเหตุที่ยังไม่ได้กล่าวถึงในบทความตอนที่ 2
ภาพรวมของเนื้อหา
การจัดการและหาข้อมูลเชิงลึกในเอกสารจดหมายเหตุในปัจจุบัน
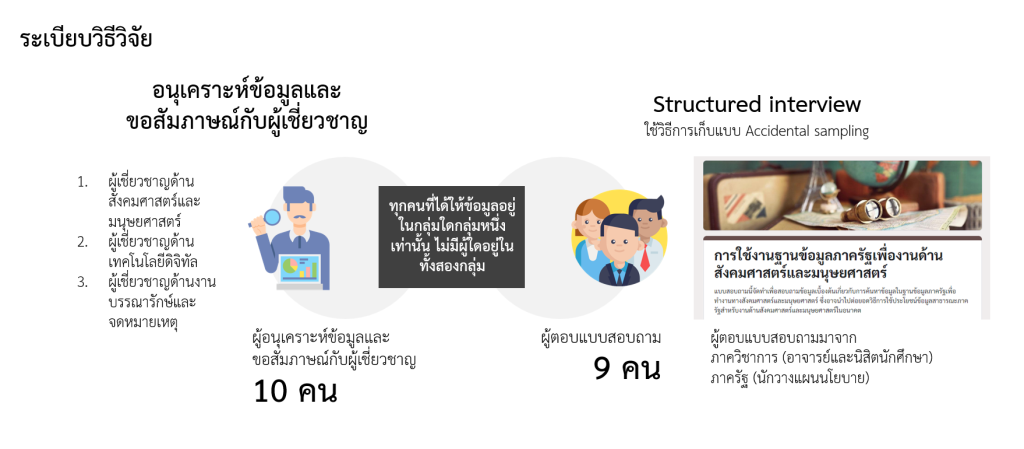
เนื่องจากเอกสารจดหมายเหตุในปัจจุบันมีความหลากหลายและมีจำนวนที่มาก การเตรียมการทางสถาปัตยกรรมข้อมูลสำหรับเอกสารเหล่านี้จึงเป็นเรื่องที่สำคัญเป็นอย่างยิ่ง ซึ่งในบริบทของประเทศไทย ทางเราได้มีการจัดทำระเบียบวิธีวิจัยดังภาพที่ 1 ซึ่งสามารถแบ่งออกได้เป็น 2 ส่วนการวิจัย คือ
1. การสอบถามจากผู้ที่เกี่ยวข้องกับการค้นคว้าเอกสารจดหมายเหตุ จำนวน 9 คน
ซึ่งใช้วิธีการสุ่มโดยเผอิญ โดยวัตถุประสงค์ที่ใช้งานนั้นสามารถแบ่งออกมาได้เป็น 2 วัตถุประสงค์หลัก คือ เพื่อการวิจัยในทางสังคมศาสตร์และมนุษยศาสตร์ และ เพื่อนำไปใช้ในการวางนโยบายองค์กรของรัฐ
2. การอนุเคราะห์ข้อมูลจากผู้เชี่ยวชาญ จำนวน 10 คน
มาจากผู้เชี่ยวชาญจากสายงานต่าง ๆ ซึ่งมีการใช้ข้อมูลทางสังคมศาสตร์และจดหมายเหตุ จำนวน 10 คน โดยกระบวนการซึ่งได้มาด้วยข้อมูลนั้นมีวิธีที่แตกต่างกัน ทั้งการสัมภาษณ์ การขอข้อมูลและจัดบรรยายภาพรวมของวิชาจดหมายเหตุ
ความท้าทายในการเข้าถึงข้อมูลเพื่องานด้านสังคมศาสตร์และมนุษยศาสตร์
จากการให้ข้อมูลผ่านแบบสอบถามประกอบกับประสบการณ์การเข้าใช้ของผู้เขียน จึงสามารถประกอบออกมาเป็นความท้าทายออกมาได้ดังนี้
1. การรวบรวมฐานข้อมูลให้มีความสะดวกต่อการใช้งาน
ซึ่งฐานข้อมูลที่จัดเก็บเอกสารจดหมายเหตุมีอยู่หลายที่มาก การค้นคว้าเอกสารโดยไม่รู้แหล่งที่จัดเก็บจึงเป็นการลำบากในการเริ่มต้นการค้นคว้าดังกล่าว โดยความท้าทายที่เกิดขึ้น คือ การทำให้มีฐานบัญชีข้อมูลกลาง นับเป็นความท้าทายทั้งในด้านการบริหารจัดการภาครัฐและความท้าทายทางสถาปัตยกรรมอีกด้วย
2. การค้นหาเป็นไปด้วยความยากลำบาก
ซึ่งเทคโนโลยีการค้นหาที่ทำให้เจอได้ง่ายขึ้นตามบริบทจะมีพื้นฐานอยู่บนลักษณะข้อมูลที่เป็น Graph Network อาจทำให้ต้องมีการทำประมวลผลภาษาธรรมชาติ (Natural Language Processing: NLP) ในภาษาไทย (สร้าง AI เข้าใจภาษามนุษย์ด้วย Natural Language Processing สำหรับ NLP) ซึ่งมีความท้าทายเป็นอย่างมาก (บทความที่เกี่ยวข้องในเชิงไวยากรณ์ทางภาษาไทยเอง ซึ่งเป็นความท้าทายหลักในการพัฒนา NLP ภาษาไทย: ทำไม NLP ภาษาไทยถึงไม่โตสักที – Arnondora)
3. ข้อมูลมีขนาดที่ใหญ่มาก
เมื่ออ้างอิงจากสำนักหอจดหมายเหตุแห่งชาติ พบว่าเอกสารที่มีอยู่ในสำนักฯ มีอยู่จำนวนประมาณ 15 ล้านแผ่นสำหรับงานเอกสารลายลักษณ์ เอกสารเย็บเล่มประมาณ 1.5 ล้านแผ่น และยังมีเอกสารประเภทอื่นอีกจำนวนมาก1
นอกจากนี้ยังมีความท้าทายอื่น เช่น ข้อมูลในอินเทอร์เน็ต หรือ ข้อมูลจากฐานข้อมูลขององค์กรซึ่งเป็น Digital-born (ข้อมูลที่เป็นดิจิทัลมาตั้งแต่เริ่มต้น) ไม่ครอบคลุมเมื่อเทียบกับที่มีอยู่ในสถานที่จริง หรือ แม้แต่ความหลากหลายของชนิดเอกสารที่จัดเก็บซึ่งมีความท้าทายในกระบวนการ digitization, การจัดเก็บข้อมูลดิจิทัลเหล่านั้น และการเก็บรักษาเอกสารต้นฉบับให้คงอยู่ได้นานที่สุดอีกด้วย
ความท้าทายเชิงเทคนิคเพื่อสัมฤทธิ์ผลความต้องการของผู้ใช้
จากการอนุเคราะห์ข้อมูลและคำสัมภาษณ์ตามส่วนที่ 2 ที่ระบุในระเบียบวิธีวิจัย รวมถึงการศึกษางานวิจัยที่เกี่ยวข้องกับการจัดการข้อมูลจดหมายเหตุ พบว่าความท้าทายในเชิงเทคนิคสามารถแบ่งออกมาได้เป็น 3 รูปแบบ คือ
1. การค้นหาเอกสารด้วยเนื้อหาและความหมายภายในเอกสารนั้น (Semantic Search)
นับตั้งแต่ พ.ศ. 2550 (ค.ศ. 2007) เป็นต้นมา แนวคิดวิทยาการเปิดเผย (Open Science) ได้ถูกนำมาพูดถึงและปฏิบัติใช้ในวงการวิจัยและแพร่กระจายไปยังวงการอื่น ๆ รวมถึงการทำข้อมูลเปิดเผยอีกด้วย2 ซึ่งโครงสร้างและความเชื่อมโยงของแนวคิดวิทยาการเปิดเผยเป็นไปตามภาพที่ 2 โดยแนวคิดแกนหลักของวิทยาการเปิดเผยจะมีวัตถุประสงค์เพื่อเพิ่มความโปร่งใสในกระบวนการวิจัย นับตั้งแต่กระบวนการทำวิจัย การบริหารจัดการงานวิจัย ไปจนถึงการบริหารข้อมูลที่มาจากงานวิจัย3
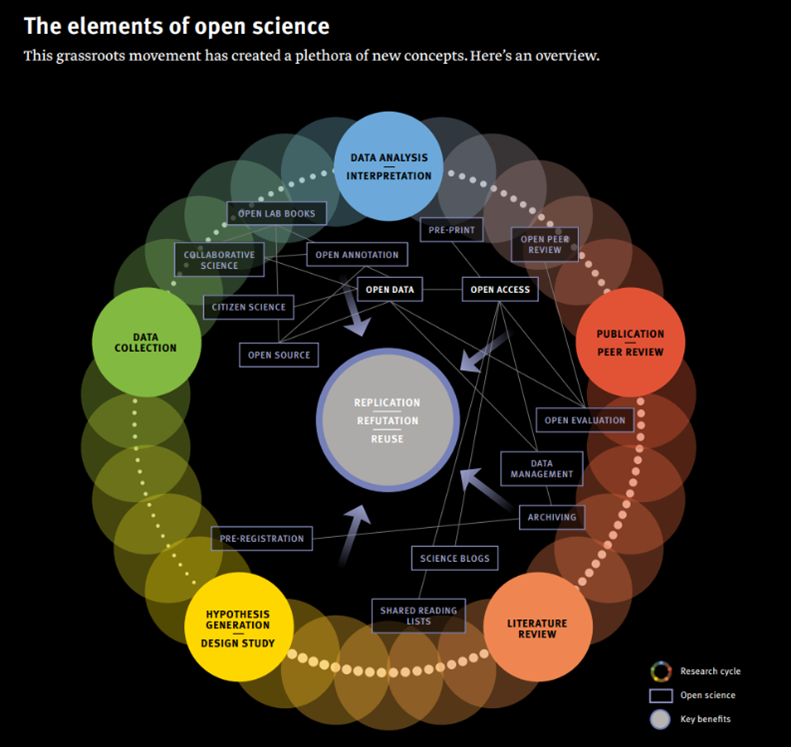
อ้างอิง: Horizons No. 110, p.13
ในปัจจุบัน เนื่องจากข้อมูลนั้นเพิ่มขึ้นมาเป็นจำนวนมาก การบริหารจัดการข้อมูลเพื่อทำให้สามารถเพิ่มศักยภาพในการค้นพบความรู้ใหม่และนวัตกรรมเป็นสิ่งที่จำเป็นอย่างยิ่ง จึงทำให้ Wilkinson, et al. (2016)4 ได้สรุปหลักการพื้นฐานที่ทำให้การบริหารจัดการข้อมูลเป็นไปอย่างมีประสิทธิภาพ คือ Findable-Accessible-Interoperable-Reusable (FAIR Principles) ซึ่งเจาะจงไปที่ตัวข้อมูลและเมตาเดตาให้มีรายละเอียดอธิบายที่มากเพียงพอให้สามารถค้นหาได้ เปิดเผย และเป็นมาตรฐาน
Hawkins (2022) ได้ระบุว่าการทำให้ผู้ศึกษาวิจัยสามารถค้นคว้าข้อมูลในเชิงความหมาย (Semantic Search) สามารถยกระดับความเร็วในการค้นพบความรู้สู่การเป็นวิทยาการใหม่หรือแนวทางการศึกษาแบบใหม่ให้กับผู้ศึกษาวิจัยที่เกี่ยวข้องกับสาขาวิชานั้นมากขึ้น5 โดยพื้นฐานโครงสร้างหลักจะแบ่งออกเป็น 4 องค์ประกอบหลักดังภาพที่ 3 คือ โครงสร้างพื้นฐานทางข้อมูล (Data Infrastructure) ชั้นภววิทยา (Ontological Layer) ชั้นจัดการตรรกะ (Unifying Logic Layer) และชั้นพิสูจน์ข้อเท็จจริง (Proof Layer)6 โดยชั้นที่มีความท้าทายในการทำงานที่สุด คือ ชั้นจัดการตรรกะและชั้นพิสูจน์ข้อเท็จจริง
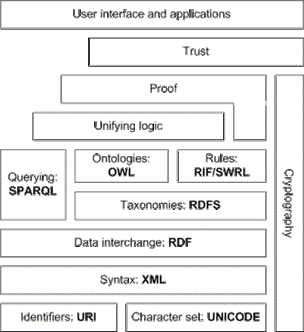
ความซับซ้อนในการทำ Semantic web
การทำ Unifying Logic ใน Semantic Web อาศัยโครงสร้างการวางระบบตรรกะเป็นแบบจำลองทางคณิตศาสตร์ ซึ่งมีวิธีการในการอนุมานโดยอ้างอิงความน่าจะเป็นสูงสุดที่คำตอบที่ตอบคำถามนั้นสมเหตุสมผลที่สุด7 ผ่านกราฟความรู้ (Knowledge Graph) ซึ่งเชื่อมโยงระหว่างสิ่งที่ต้องการศึกษา8 ในปัจจุบันนี้ การทำงานดังกล่าวยังคงเป็นหัวข้อวิจัยที่ยังได้รับความสนใจเป็นอย่างมาก เช่น การประชุมวิชาการ Knowledge Discovery and Data Mining (KDD) มีผู้ส่งงานวิจัยในการประชุมปีละประมาณ 800-1,200 บทความ9 รวมทั้งส่วนที่สามารถวิจัยได้มีได้นับตั้งแต่ญาณวิทยา (Epistemology) คณิตตรรกศาสตร์ (Mathematical Logic) ไปจนถึงวิทยาการคอมพิวเตอร์ จึงเป็นหัวข้อที่นักวิจัยสนใจอย่างกว้างขวาง
การทำ Proof ใน Semantic Web ซึ่งหมายถึงการอธิบายเหตุผลที่มาที่ไปของการอนุมานจากส่วนที่ให้เหตุผลจากชั้น Unifying Logic แล้ว มีวิธีการทำอ้างอิงจาก Explainable Artificial Intelligence (XAI) โดยแบบจำลองที่เป็นยอดนิยม คือ SHAP และ LIME และยังมีความพยายามในการทำคำอธิบายในการอนุมานนั้นด้วยวิธีอื่น ๆ อีกด้วย เช่น Knowledge Matching ซึ่งเป็นการนำข้อมูลที่ Machine Learning Model สามารถทำนายได้มาจับคู่กับความรู้ที่มีอยู่ในโครงสร้างความรู้ หรือการอธิบายที่มีลักษณะมนุษย์เป็นศูนย์กลางมากขึ้น ซึ่งใช้แบบจำลองการประมวลผลภาษาธรรมชาติ (NLP)10
แต่อย่างไรนั้น การสร้างแพลตฟอร์มที่สามารถค้นหาบริบทอย่างชาญฉลาดดังที่กล่าวไว้ ข้อมูลเป็นสิ่งที่จำเป็น ซึ่งข้อมูลดังกล่าวมีความเป็นไปได้ทั้งเป็น Digital-born และ Non-digital-born Documents โดยจากที่พูดถึงในตอนที่ 2 เรื่อง Digitalization นั้นจะเห็นถึงปัญหาในการแกะตัวอักษรทั้งด้วยเทคโนโลยีและโบราณคดี หากสรุปโดยง่าย เราสามารถทำ Digitization ได้ด้วย OCR อย่างที่ผู้เขียนได้ทำไว้ในภาพที่ 4
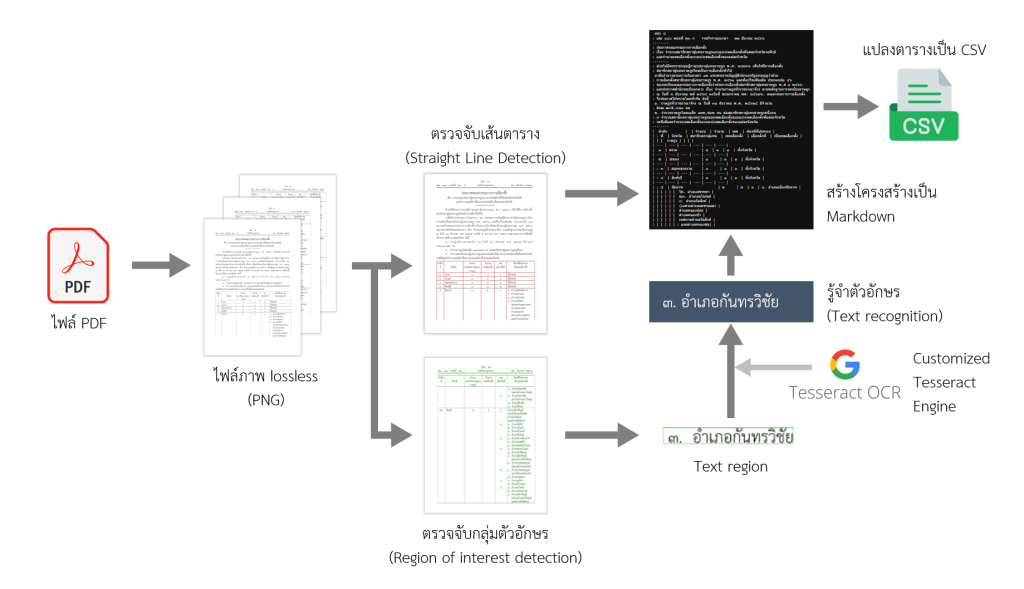
ซึ่งหากยังไม่มีข้อมูลที่เพียงพอในการทำการวิเคราะห์ผล การทำให้มีข้อมูลอย่างเช่นการนำเข้าข้อมูลเอกสารจริงเป็นรูปแบบดิจิทัลเป็นปัจจัยที่จำเป็นอย่างยิ่ง
2. การสืบประวัติการแก้ไขของเอกสารทางกฎหมาย
นอกจากนี้แล้ว ประเด็นที่น่าสนใจอีกหนึ่งอย่างจากที่ได้ข้อมูลมาจากผู้เชี่ยวชาญ คือ การสืบประวัติการแก้ไขของเอกสารทางกฎหมาย ซึ่งมีลักษณะคล้ายกับ Git Version Control System โดยในเบื้องต้น การทำให้เห็นการชำระและปรับปรุงกฎหมายเป็นสิ่งที่รัฐหลายประเทศทำ เช่น สหราชอาณาจักร หรือ สหรัฐอเมริกาใน District of Columbia ซึ่งทำให้เห็นถึงการเปลี่ยนแปลงและตีความกฎหมายได้อย่างเป็นระบบมากยิ่งขึ้น ประการหนึ่ง คือ การทำให้เห็นเป็นที่ประจักษ์ว่าศัพท์ทางกฎหมายหนึ่ง ๆ มีบริบทความหมายว่าอย่างไร
3. การจัดการเอกสารจดหมายเหตุด้วยกฎเกณฑ์การจำแนกเอกสาร (Document Classification)
ในทางงานจัดการบันทึกเอกสารและจัดการจดหมายเหตุ กฎเกณฑ์การจำแนกเอกสารเป็นสิ่งที่จำเป็นอย่างยิ่งเพื่อทำให้ผู้ค้นคว้าสามารถหยิบหาได้ง่ายยิ่งขึ้นและเห็นภาพรวมของการจัดเก็บเอกสารยิ่งขึัน ซึ่งในงานจัดการบันทึกเอกสารและงานทางจดหมายเหตุจะมีหลักการคิดไม่เหมือนกันดังภาพที่ 5
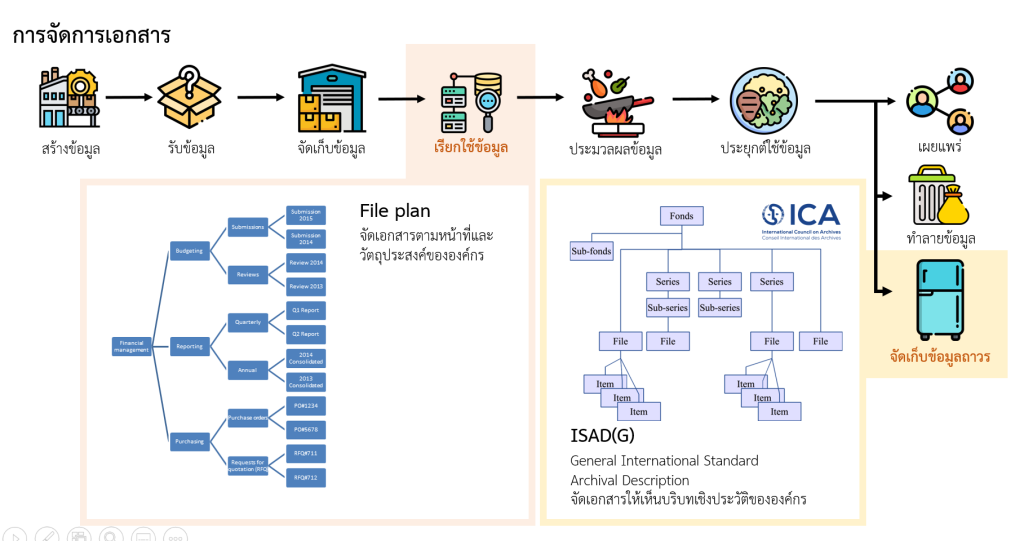
ซึ่งหลักการในการจัดการเอกสารบันทึกนั้นจะเน้นการใช้งานที่ทำให้องค์กร11 สะดวกในการทำงานตามภารกิจขององค์กรที่สุด โดยจะเริ่มแบ่งขั้นตอนตามหน้าที่ขององค์กร แล้วลงมาที่กิจกรรมซึ่งทำให้วัตถุบรรลุวัตถุจุดประสงค์นั้น โครงการ และชิ้นงานเอกสารตามลำดับ12 แต่หากพูดถึงมาตรฐาน ISAD(G)13 ซึ่งเป็นมาตรฐานในการจัดการเอกสารจดหมายเหตุหรือการจัดเก็บข้อมูลถาวร โจทย์ประธานของมาตรฐานนี้จึงเป็นวัตถุประสงค์ในการสืบสาวความเป็นมาและเหตุในการกระทำเชิงประวัติ การจัดมาตรฐานจึงจำเป็นต้องแบ่งตามหัวข้อที่ชี้ให้เห็นถึงเหตุการณ์สำคัญขององค์กร
อย่างไรก็ตาม Payne (2018)14 และนักวิจัยอื่น ๆ ที่เกี่ยวข้อง15 ได้เล็งเห็นถึงอิทธิพลสำคัญของขนาดของข้อมูลที่เพิ่มขึ้นมาอย่างมีนัยสำคัญ จึงทำให้เกิดวิทยาการใหม่อย่าง “วิทยาการจดหมายเหตุเชิงคำนวณ (Computational Archival Sciences)” ซึ่งเห็นว่าการนำวิทยาการคอมพิวเตอร์มาใช้ในการจัดการเอกสารจดหมายเหตุ ทั้งในมิติของการทำให้เห็นความสัมพันธ์ระหว่างมนุษย์ เทคโนโลยี และสังคม การเก็บรักษาเอกสารระยะยาว และประกอบสร้างซึ่งข้อเท็จจริงให้มีความคงเส้นคงวามากขึ้นผ่านเทคโนโลยี
ตัวอย่างหนึ่งที่ทำให้เห็นว่าบทบาทของแบบจำลองการเรียนรู้ของเครื่อง ซึ่ง Franks (2022)16 ได้ใช้แบบจำลองการเรียนรู้ 3 ประเภท คือ Machine Learning Model กับ TF-IDF ปกติ Neural Networks และ Language Model ในการคัดแยกหมวดหมู่ของเอกสารในองค์กร Australian Human Rights Commission ที่มีจำนวนบทความทั้งสิ้น 6,217 บทความใน 29 กลุ่มชุดของเอกสาร พบว่าความถูกต้องในการจัดหมวดหมู่เอกสารอยู่ที่ประมาณ 67-88% และมีความแม่นยำ 54-81% ซึ่งร้อยละจะแปรผันตามประเภทของแบบจำลองที่ใช้ การ Resampling จากความไม่สมดุลของจำนวนข้อมูลในแต่ละประเภท (Imbalanced Data) และจำนวนของข้อมูลในแต่ละประเภท
นอกจากนี้ เมื่อสามารถจัดหมวดหมู่ของเอกสารได้แล้ว แบบจำลองการเรียนรู้ของเครื่องอื่น ๆ ยังสามารถสร้างคำอธิบายให้กับคลังจดหมายเหตุ, การตอบคำถามจากสารานุกรม, และการสรุปสาระสังเขป โดย Generative AI อย่าง ChatGPT สามารถทำงานเหล่านี้ได้ หากมีการปรับปรุงแบบจำลองให้มีความจำเพาะกับบริบทที่สนใจ เช่น WangchanBERTa ซึ่งก็จะย้อนไปตอบคำถามในส่วนแรกที่เกี่ยวข้องกับการค้นหาข้อมูลเชิงความหมาย ทว่าแบบจำลองเหล่านี้ยังคงสร้างข้อมูลที่ไม่มีอยู่จริงและขัดแย้งกับข้อเท็จจริงที่มนุษย์ทราบ (Hallucination) และยังต้องใช้ทรัพยากรการคำนวณที่ค่อนข้างมาก จึงยังคงเป็นความท้าทายอยู่ในปัจจุบันนี้
การตีความผลการวิเคราะห์จากเอกสารจดหมายเหตุ
สามารถอ่านได้เพิ่มเติมที่ Critical Questions for Archives as (Big) Data (core.ac.uk)
หากเรามองว่าเอกสารจดหมายเหตุเป็นข้อมูลที่ถูกนำมาใช้ในการวิเคราะห์ได้นั้น การทำ data analytics สามารถกระทำได้โดยนักวิทยาศาสตร์ข้อมูลและผู้เชี่ยวชาญทางการคำนวณอื่น ๆ เพื่อแสดงให้เห็นถึงผลสัมฤทธิ์จากโจทย์ปัญหาโดยมีเอกสารจดหมายเหตุเป็นข้อมูลตัวตั้ง ชะรอยผู้เชี่ยวชาญเหล่านี้อาจไม่ได้มีความรู้ที่เกี่ยวข้องกับเอกสารsหรือโจทย์ที่เกี่ยวข้อง ซึ่งเป็นปกติในงานทางวิทยาศาสตร์ข้อมูลที่จะมีผู้เชี่ยวชาญด้านอื่น ๆ มาช่วยพิจารณาความสมเหตุสมผลในการวิเคราะห์ข้อมูลจากนักวิทยาศาสตร์ข้อมูล
การวิเคราะห์ข้อมูลตามโจทย์ปัญหาที่ตั้งไว้นับตั้งแต่กระบวนการคิดโจทย์ไปจนถึงกระบวนการตอบคำถามและอภิปรายผล ย่อมมีปรัชญาที่แทรกซึมอยู่ภายในปัญหาเหล่านั้นเสมอ หากได้เป็นตั้งแต่การวิเคราะห์ประวัติศาสตร์ ไปจนถึงการค้นหาความจริงของโลก ซึ่งเป็นสิ่งที่ ณ ปัจจุบันนี้ยังไม่สามารถนำปัญญาประดิษฐ์มาใช้ในการตอบคำถามได้ และยังเป็นที่ถกเถียงเสมอมาว่าคำตอบของปัญหาเหล่านั้นอาจไม่ได้มีลักษณะสัมบูรณ์ ความจำเป็นที่จะต้องเปิดเผยหลักคิดในการทำแบบจำลองหรือระเบียบวิธี (Algorithmic Transparency) จึงสำคัญเป็นอย่างมากในการใช้ประโยชน์ข้อมูลเอกสารจดหมายเหตุ
ยกตัวอย่างเช่น งานการออกแบบนโยบายสาธารณะที่อาจจำเป็นต้องวิเคราะห์จากเอกสารในอดีต ซึ่งก็มีทฤษฎีทางเศรษฐศาสตร์ที่สามารถกำหนดวัตถุประสงค์ของปัญหาที่นำไปสู่นโยบายสาธารณะนั้น ๆ ได้ หรือสำหรับในงานประวัติศาสตร์เชิงคำนวณ (Computational History) ก็ยังมีความจำเป็นที่จะต้องพึ่งพาข้อเสนอทางประวัติศาสตร์ที่นักประวัติศาสตร์เสนอต่อเหตุการณ์ที่สนใจอีกด้วย
ต่อจากนี้ เราจะมาแนะนำศาสตร์ที่สามารถนำเอกสารประวัติศาสตร์มาทำเป็นโครงการทางวิทยาศาสตร์ข้อมูลอย่าง มนุษยศาสตร์ดิจิทัล
เปลี่ยนมุมมองการศึกษามนุษยศาสตร์ด้วยมนุษยศาสตร์ดิจิทัล (Digital Humanities)

โจทย์ศึกษาแรกของมนุษยศาสตร์ดิจิทัล
ที่มา: http://www.nationalgallery.org.uk/paintings/carlo-crivelli-saint-thomas-aquinas
ในปี พ.ศ. 2489 (ค.ศ. 1946) Roberto Busa นักบวชชาวอิตาลี, Josephine Miles อาจารย์ภาควิชาภาษาอังกฤษในมหาวิทยาลัยแคลิฟอร์เนียเบิร์คลีย์ (University of California, Berkeley), และ IBM ได้ทำโครงการสรุปสารานุกรมการบริบทใช้คำ (Concordance) ของนักบุญทอมัส อไควนัสจากงานเขียนทั้งสิ้น 179 ชิ้น ซึ่งทำให้ได้จำนวนคำมาทั้งสิ้น 10,631,980 คำ แบ่งหนังสือได้เป็น 56 เล่ม รวมสุทธิประมาณ 70,000 หน้า ซึ่งเผยแพร่ในชุดหนังสือ Index Thomisticus โดยสมบูรณ์ในปี 1980
นับตั้งแต่คริสต์ทศวรรษ 1960 การเข้ามาของเทคโนโลยีการคำนวณอย่างคอมพิวเตอร์อิเล็กทรอนิกส์ได้เข้ามาสู่มนุษยชาติทำให้เกิดการสร้างกลุ่มวิจัยที่เกี่ยวข้องกับการประยุกต์ใช้คอมพิวเตอร์อิเล็กทรอนิกส์กับงานทางมนุษยศาสตร์ ทั้งในโบราณคดี ภาษาศาสตร์ จนกลายเป็นวิชามนุษยศาสตร์ดิจิทัลในที่สุด โดยมนุษยศาสตร์ดิจิทัลนั้นสามารถแบ่งออกมาได้จากวัตถุประสงค์ของโครงการเป็นหลายรูปแบบ เช่น
1. เพื่อทำให้เห็นภาพรวมขององค์ประธานที่สนใจ (Data visualization)
การทำให้เห็นภาพเป็นสิ่งหนึ่งที่มนุษยศาสตร์ดิจิทัลสนใจ ซึ่งทำให้มนุษย์เห็นความเชื่อมโยงของข้อมูลได้มากขึ้น หรือ สามารถสรุปงานที่เกี่ยวข้องกับองค์ประธานที่กำลังศึกษาค้นคว้า ซึ่งอาจมีข้อมูลที่มากและซับซ้อนจนมนุษย์ไม่สามารถทำความเข้าใจได้
2. ใช้เป็นเครื่องมือในการคำนวณและประมวลผล

ที่มา: เพจคิดอย่าง – อุโบสถ วัดหาดเสี้ยว อำเภอศรีสัชนาลัย จังหวัดสุโขทัย
การมีเทคโนโลยีดิจิทัลทำให้งานค้นคว้าทางโบราณคดีอย่าง เช่น การดูแลบูรณปฏิสังขรณ์วัดหาดเสี้ยว อำเภอศรีสัชนาลัย จังหวัดสุโขทัย ซึ่งเป็นโบราณสถานอายุประมาณ 200 ปี จึงทำการถ่ายรูปเป็นโมเดล 3 มิติเพื่อให้การบูรณปฏิสังขรณ์เป็นไปในแนวทางอนุรักษ์มากที่สุด โดยทำให้โบราณสถานนั้นเสียหายให้น้อยที่สุดดังภาพที่ 8
นอกจากนี้ งานที่เกริ่นไว้ข้างต้นอย่าง Index Thomisticus ก็จัดอยู่ประเภทนี้เช่นกัน
ทั้งหมดนี้จะพบว่าความท้าทายที่เกิดขึ้นในงานจดหมายเหตุไม่ได้มีแต่ความท้าทายที่เกิดขึ้นในเชิงเทคนิคทางวิทยาศาสตร์ข้อมูลเท่านั้น แต่ยังมีความท้าทายที่เกิดขึ้นในเชิงประวัติศาสตร์เรื่องการตีความ การประเมินคุณค่าของเอกสาร และการบำรุงรักษาเอกสารให้อยู่ในสภาพที่สมบูรณ์ที่สุด ซึ่งต้องพึ่งพิงความเชี่ยวชาญจากผู้เชี่ยวชาญที่เกี่ยวข้องกับเอกสารและวิทยาการที่เกี่ยวข้องอีกด้วย
เชิงอรรถ
เรียบเรียงโดย กฤตพัฒน์ รัตนภูผา
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์












