
หลังจากที่เห็นความสามารถและผลงานอันน่าทึ่งของ DALL·E 2 ในภาคแรก บทความนี้จะพามาให้รู้จักปัญญาประดิษฐ์ตัวนี้ให้มากขึ้น ทั้งในแง่มุมของเทคโนโลยีเบื้องหลัง ข้อจำกัดของความสามารถและผลกระทบที่อาจจะสร้างความกังวลในสังคมได้
อ่านบทความแรกได้ที่ DALL·E 2: ปัญญาประดิษฐ์ผู้สร้างภาพตามคำบรรยาย – Part I
การทำงานของ DALL·E 2
การทำงานของ DALL·E 2 นั้นมีเทคโนโลยีหลักที่เกี่ยวข้อง 2 อย่างดังนี้
- CLIP (Contrastive Language-Image Pre-training) เป็นอีกหนึ่งผลงานของ OpenAI ซึ่งสร้างคำบรรยายภาพจากรูปภาพที่กำหนด (นั่นคือ ทำหน้าที่ตรงข้ามกับ DALL·E) โมเดลนี้ประกอบไปด้วยโครงข่ายประสาทเทียมสองตัว นั่นคือ Text Encoder และ Image Encoder ซึ่งเป็นตัวแปลงคำบรรยายและรูปภาพให้อยู่ในรูปแบบเวกเตอร์ที่เรียกว่า Text Embedding และ Image Embedding ตามลำดับ
Text encoder และ Image Encoder นี้จะผ่านการฝึกฝนด้วยการแปลงข้อมูลรูปภาพและคำบรรยายภาพที่กำหนดมาคู่กันจำนวนมหาศาลให้อยู่ในรูปแบบ Text Embedding และ Image Embedding และทำความเข้าใจความสัมพันธ์ ให้สามารถจับคู่คำบรรยายภาพและรูปภาพให้ถูกต้องมากที่สุด
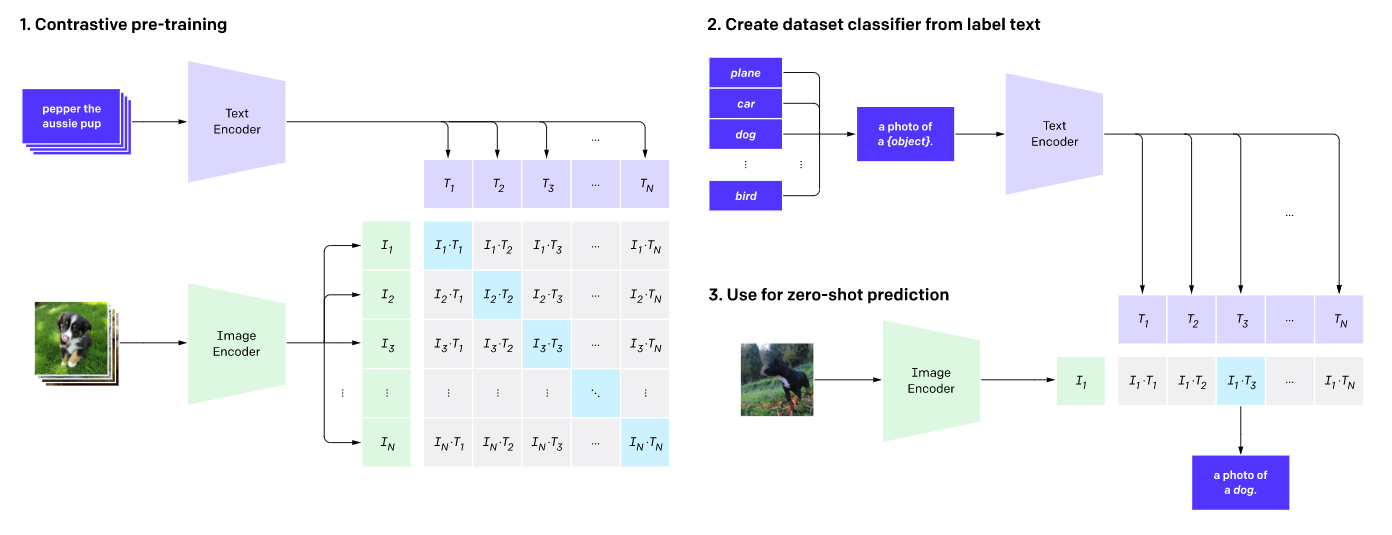
ดังเช่นในขั้นตอนสุดท้าย เมื่อใส่รูปสุนัขเข้าไปในโมเดล ผลออกมาว่าเป็น “a photo of a dog” (Source: OpenAI)
- Diffusion Model เป็นโมเดลที่ใช้สำหรับสร้างรูปภาพจาก random dots (กลุ่มของจุดที่กระจัดกระจายอย่างไม่มีรูปแบบ) หลักการการฝึกโมเดลนี้ คือ เริ่มต้นจากรูปภาพที่ชัดเจน จากนั้นจึงเพิ่ม Noise หรือสิ่งที่ทำให้ภาพเริ่มไม่ชัดเจนให้มากขึ้นเรื่อย ๆ จนกระทั่งภาพนั้นไม่สามารถระบุได้ และให้โมเดลเรียนรู้ในการทำให้รูปภาพนั้นกลับมาดังเดิมอีกครั้ง

เทคโนโลยีข้างต้นได้ถูกนำมาประยุกต์ในการทำงานของ DALL·E 2 โดยเริ่มต้นจากการที่ CLIP Text Encoder แปลงคำบรรยายภาพที่ต้องการสร้างให้อยู่ในรูปแบบเวกเตอร์ Text Embedding หลังจากนั้นจะสร้างรูปภาพผ่าน 2 โมเดลดังต่อไปนี้
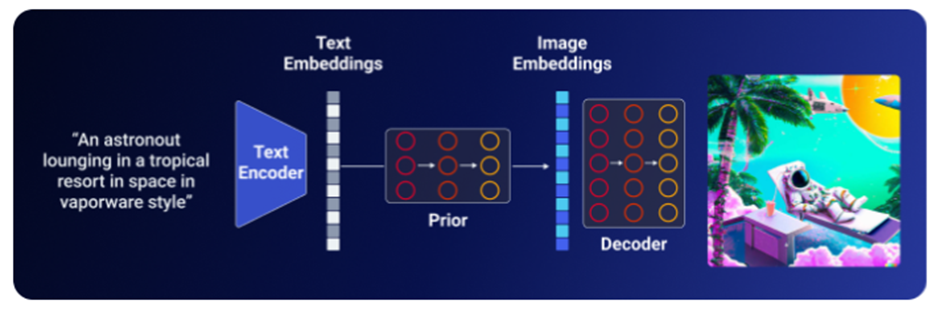
(Source: Aditya Singh)
- Prior model ซึ่งเป็นโมเดลสำหรับการเก็บข้อมูลขององค์ประกอบหลักของภาพที่ต้องการสร้างจากคำบรรยายภาพ โมเดลนี้จะรับ CLIP Text Embedding ซึ่งเป็นเวกเตอร์ที่เก็บข้อมูลของคำบรรยายภาพที่แปลงไว้แล้วและ สร้าง CLIP Image Embedding ที่สอดคล้องกันออกมา
- Decoder Diffusion model (unCLIP) ซึ่งเป็นโมเดลสำหรับการสร้างภาพและเติมรายละเอียดของรูปภาพให้สมบูรณ์เป็นโมเดลที่ประยุกต์จาก Diffusion Model ให้สามารถแปลงเวกเตอร์ CLIP Image Embedding ให้กลายเป็นรูปภาพตามคำบรรยาย สาเหตุที่เรียกโมเดลนี้ว่า unCLIP เนื่องจากทำตรงข้ามกับ CLIP ซึ่งสร้างคำบรรยายภาพจากรูปภาพที่กำหนดนั่นเอง
ข้อดีที่โดดเด่นของการทำงานแบบ 2 ขั้นตอนนี้ คือ การเน้นเก็บข้อมูลขององค์ประกอบหลักของรูปภาพที่ต้องการสร้างใน Prior model ก่อนจะสร้างภาพที่มีความละเอียดสูงในขั้นตอนต่อมา ทำให้ DALL·E 2 ยังสามารถเก็บองค์ประกอบหลักของภาพได้อย่างครบถ้วน ในขณะที่ยังสามารถสร้างความหลากหลายของภาพในรายละเอียดที่แตกต่างกันได้
ข้อจำกัดและอันตรายที่อาจจะเกิดขึ้นจาก DALL·E 2
แม้ว่า DALL·E 2 แสดงความสามารถอันน่าทึ่งมากมาย แต่อย่างไรก็ยังมีข้อจำกัดซึ่งยังแสดงว่า ปัญญาประดิษฐ์นี้ยังไม่สามารถเข้าใจความซับซ้อนของสมองมนุษย์ได้ ดังต่อไปนี้
อคติในการสร้างรูปภาพ
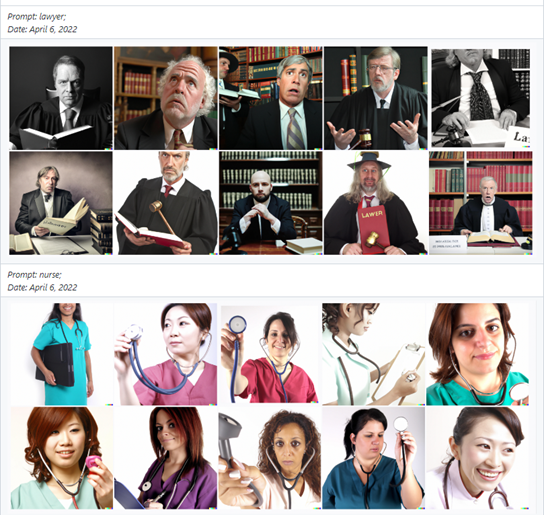
แม้ว่า DALL·E 2 จะมีการเรียนรู้จากภาพจำนวนมหาศาลในอินเตอร์เน็ต รูปของ DALL·E 2 ยังคงความอคติทั้งทางด้านเชื้อชาติและเพศอยู่ เช่น รูปส่วนใหญ่อาจเป็นชนชาติผิวขาวหรือชาวตะวันตก และในหลายอาชีพ DALL·E 2 จะสร้างรูปทั้งหมดเป็นเพศหญิงหรือเพศชายเท่านั้น
การสะกดคำในรูปภาพที่ยังไม่สมบูรณ์
DALL·E 2 นั้นยังไม่สามารถสะกดคำในรูปภาพได้อย่างแม่นยำ ดังในตัวอย่างในรูปที่ 16 ที่จริง ๆ แล้ว ป้ายควรแสดงคำว่า “deep learning”

(Source: OpenAI)
รายละเอียดบางอย่างที่ไม่สมเหตุสมผล
DALL·E 2 นั้นทำงานได้ดีในการสร้างองค์ประกอบหลักของรูปภาพ แต่สามารถขาดการสร้างรายละเอียดที่สมเหตุสมผลได้ ดังเช่น รูปมือถือใบไม้ ที่องค์ประกอบหลักอย่างมือ หรือใบไม้นั้นดูสมจริง โดยเฉพาะมือที่เปื้อนดินราวกับเพิ่งขุดใบไม้ขึ้นมา แต่ถ้าสังเกตแล้ว ตรงกลางฝ่ามือที่มีใบไม้วางอยู่ซึ่งควรจะมีเส้นแบ่งระหว่างมือสองข้างกลับหายไป

การไม่สามารถกำหนดตำแหน่งของวัตถุที่เกี่ยวข้องกันได้อย่างแม่นยำ
DALL·E 2 ยังคงไม่สามารถวางตำแหน่งของวัตถุที่เกี่ยวข้องกันได้อย่างถูกต้องแม่นยำ ตัวอย่างเช่น รูปลูกบาศก์สีแดงซึ่งควรจะอยู่บนลูกบาศก์สีน้ำเงินนี้ แม้ DALL·E 2 จะสามารถสร้างองค์ประกอบหลักอย่างลูกบาศก์ได้ถูกต้อง แต่ส่วนใหญ่ยังคงจัดวางตำแหน่งที่เกี่ยวข้องกันได้ผิดพลาด นั่นคือ หลาย ๆ รูปนั้น ลูกบาศก์สีน้ำเงินกลับอยู่ข้างบนลูกบาศก์สีแดง

ลูกบาศก์สีแดงบนลูกบาศก์สีน้ำเงิน
ซึ่งรูปส่วนใหญ่ยังคงจัดวางตำแหน่งไม่ถูกต้อง (Source: OpenAI)
ที่สำคัญไปกว่านั้น การที่ DALL·E 2 สามารถสร้างภาพที่สมจริงตามคำบรรยายและมีความสามารถในการตัดต่อภาพได้อย่างแนบเนียนอาจสามารถถูกนำไปใช้ในทางที่ไม่ดีได้ เช่น การตัดต่อภาพในการแบล็คเมล์ผู้คน หรือ การสร้างรูปภาพที่ก่อให้เกิดความเข้าใจผิดหรือกังวลใจได้

(Source: OpenAI)
ณ ปัจจุบัน ทางทีมผู้พัฒนา DALL·E 2 มีแผนในการเปิดการใช้งานของ DALL·E 2 แบบสาธารณะในเร็ว ๆ นี้ โดยจะเริ่มต้นจากเชิญบุคคลที่ลงทะเบียนสนใจจะใช้งาน DALL·E 2 (สามารถลงทะเบียนได้ที่นี่) ผู้ใช้งานจะได้รับเครดิตในการสร้างรูปภาพได้ฟรี แต่อย่างไรก็ตาม เครดิตฟรีนั้นสร้างภาพได้จำนวนจำกัด และจะมีค่าใช้จ่ายถ้าผู้ใช้งานต้องการสร้างรูปเพิ่มเติม
นอกเหนือจากนี้ ทางทีมงานผู้พัฒนา DALL·E 2 ได้ประกาศถึงมาตรการความปลอดภัยเพื่อป้องกันการนำ DALL·E 2 ที่กำลังจะเปิดสู่สาธารณะไปใช้ในทางที่ไม่เหมาะสม นั่นคือ ไม่อนุญาตให้อัปโหลดรูปภาพที่มีใบหน้าบุคคลจริง มีการป้องกันในการสร้างภาพที่มีความรุนแรง พัฒนาระบบให้ลดความอคติในการสร้างรูปภาพ และมีระบบการติดตามการใช้งานเพื่อป้องกันการใช้งานที่ไม่เหมาะสม
สุดท้ายนี้ แม้ว่า DALL·E 2 จะแสดงความสามารถและศักยภาพอันน่าทึ่งของปัญญาประดิษฐ์มากเพียงใด ก็ยังคงมีข้อจำกัด ที่สำคัญคือ ยังมีผลกระทบที่สามารถสร้างความวิตกกังวลให้สังคมได้ ในอนาคต ความสามารถของปัญญาประดิษฐ์ในด้านการสร้างรูปภาพจะสามารถพัฒนาไปไกลถึงระดับใกล้เคียงกับความสามารถของสมองอันซับซ้อนของมนุษย์ได้มากขนาดไหน อีกทั้งปัญญาประดิษฐ์ตัวนี้จะสร้างอันตรายในสังคมอย่างที่หลายคนกังวล แม้ว่าทางทีมงานจะเตรียมมาตรการความปลอดภัยไว้แล้วหรือไม่ ก็คงต้องติดตามกันต่อไป
แหล่งอ้างอิง
- DALL·E 2, Explained: The Promise and Limitations of a Revolutionary AI by Alberto Romero (2022)
- How DALL·E 2 Works by Aditya Ramesh (2022)
- How Does DALL·E 2 Work? By Aditya Singh (2022)
เนื้อหาโดย ศรัณธร ภู่สิงห์ ตรวจทานและปรับปรุงโดย อนันต์วัฒน์ ทิพย์ภาวัต









